非关系型数据库(选修课)
非关系型数据库(选修课)
上课老师发的课件合计,下载地址如下
https://wwcz.lanzout.com/b04kt28wb
密码:4a0t
Redis基础内容
概述
简介
Remote Dictionary Server,简称Redis,即远程字典服务器,它是一个开源的、高性能的、基于键值对的缓存与存储数据库,并且通过提供多种键值数据结构来适应不同场景下的缓存与存储需求。Redis数据库是基于ANSI C语言编写开发的,并且提供了多种语言API,例如Java、C/C++、C#、PHP、JavaScript、Perl、Python及Ruby等语言。
特点
- 支持多种数据结构
- 功能丰富
- 应用广泛
- 读写速度快
应用场景
- 构建队列系统
- 排行榜
- 实时的垃圾系统
- 数据自动过期处理
- 计数器应用
- 缓存
支持的数据结构
- String(字符串)
- List(列表)
- Set(集合)
- Hash(散列)
- Sorted Sets(有序集合)
相关操作
其他
启动 redis-cli 客户端工具,可以做如下处理:
修改 cmd 控制台的编码格式为 UTF-8:
命令:chcp 65001
然后再输入:
命令:redis-cli –raw
再查询时,就能得到想要的中文数据了。
Key(键)
| 命令 | 作用 |
|---|---|
| SET | 为指定键设置值 |
| MSET | 为多个键设置值 |
| GET | 获取指定键等值 |
| MGET | 获取多个键对应的值 |
| EXISTS | 判断指定键是否存在 |
| KEYS | 查找所有符合给定pattern(正则表达式)的键 |
| DUMP | 序列化置顶的键,并返回被序列化的值 |
| TYPE | 查看指定键的类型 |
| RENAME | 重命名指定键的键名 |
| EXPIRE | 设置指定键的生存时间,以秒为单位 |
| TTL | 查看指定键的剩余生存时间 |
| PERSIST | 移除键的生存时间 |
| DEL | 在键存在时,删除键 |

String(字符串)

| 命令 | 作用 |
|---|---|
| SET | 为指定键设置值 |
| MSET | 为多个键设置值 |
| GET | 获取指定字符串key中的值 |
| MGET | 获取多个字符串key中的值 |
| GETSET | 获取指定字符串的旧值并设置新值 |
| STRLEN | 获取字符串的字节长度 |
| GETRANGE | 获取字符串键指定索引范围的值的内容 |
| SETRANGE | 为字符串的指定索引位置设置值 |
| APPEND | 追加新内容到值的末尾 |
注:setrange是指定一个字符串的开始替换位置,然后从这个位置开始把要设置的值替换进去,相当于从指定位置开始把原始值和指定值做覆盖,指定值覆盖在原始值上面

List(列表)

| 命令 | 作用 |
|---|---|
| LPUSH | 将一个或多个元素推入到列表的左端 |
| RPUSH | 将一个或多个元素推入到列表的右端 |
| LRANGE | 获取列表指定索引范围内的元素 |
| LINDEX | 获取列表指定索引位置上的元素 |
| LPOP | 弹出列表最左端的元素 |
| RPOP | 弹出列表最右端的元素 |
| LLEN | 获取指定列表的长度 |
| LREM | 移除列表中的指定元素 |

Set(集合)

| 命令 | 作用 |
|---|---|
| SADD | 将一个或多个元素添加到集 |
| SCARD | 获取集合中元素数量 |
| SMEMBERS | 获取集合中所有存在元素 |
| SISMEMBER | 检查指定元素是否存在在集合中 |
| SREM | 移除集合中的一个或多个已存在的元素 |
| SMOVE | 将元素从一个集合移到另一个集合中 |

Hash(散列)

| 命令 | 作用 |
|---|---|
| HSET | 为散列中指定键设置值 |
| HMSET | 为散列中多个键设置值 |
| HGET | 获取散列中的指定键的值 |
| MMGET | 获取散列中多个键的值 |
| HGETALL | 获取散列中的所有键值对 |
| HKEYS | 获取散列中所有键 |
| HVALS | 获取散列中所有键的值 |
| HDEL | 删除散列中指定键及其对应的值 |

Sorted Sets(有序集合)

| 命令 | 作用 |
|---|---|
| ZADD | 为有序集合添加一个或多个键值对(先写值后写键) |
| ZCARD | 获取有序集合中元素个数 |
| ZCOUNT | 统计有序集合中指定分值范围内的元素个数 |
| ZRANGE | 获取有序集合中指定索引范围内的元素 |
| ZSCORE | 获取有序集合中指定元素的分值 |
| ZREM | 移除有序集合中的指定元素 |

Docker基础内容
概述
概念
Docker 是一个开源的应用容器引擎,诞生于 2013 年初,基于 Go 语言实现, dotCloud 公司出品(后改名为Docker Inc) Docker 可以让开发者打包他们的应用以及依赖包到一个轻量级、可移植的容器中,然后发布到任何流行的Linux 机器上。容器是完全使用沙箱机制,相互隔离容器性能开销极低。Docker 从 17.03 版本之后分为 CE(Community Edition: 社区版) 和 EE(Enterprise Edition: 企业版)
架构
镜像(Image):Docker 镜像(Image),就相当于是一个 root 文件系统。比如官方镜像 ubuntu:16.04 就包含了完整的一套 Ubuntu16.04 最小系统的 root 文件系统。
容器(Container):镜像(Image)和容器(Container)的关系,就像是面向对象程序设计中的类和对象一样,镜像是静态的定义,容器是镜像运行时的实体。容器可以被创建、启动、停止、删除、暂停等。
仓库(Repository):仓库可看成一个代码控制中心,用来保存镜像。
命令
Docker
Window端通过安装docker软件,通过软件启动、停住重启docker服务
镜像相关
查看镜像
docker imagesdocker images –q查看所用镜像的id搜索镜像
docker search 镜像名称拉取镜像
docker pull 镜像名称删除镜像
docker rmi 镜像id删除指定本地镜像docker rmi docker images -q删除所有本地镜像
容器相关
查看容器
docker ps查看正在运行的容器docker ps –a查看所有容器创建容器
docker run 参数参数如下
-i:保持容器运行。通常与 -t 同时使用。加入it这两个参数后,容器创建后自动进入容器中,退出容器后,容器自动关闭。
-t:为容器重新分配一个伪输入终端,通常与 -i 同时使用。
-d:以守护(后台)模式运行容器。创建一个容器在后台运行,需要使用docker exec 进入容器。退出后,容器不会关闭。
-it 创建的容器一般称为交互式容器,-id 创建的容器一般称为守护式容器
–name:为创建的容器命名。
-p: 把写在前面的本地tcp端口映射到写在后面的容器内部端口号,如
-p 8000:8080表示将容器内的8080端口映射到主机的8000端口。进入容器
docker exec 参数退出容器,容器不会关闭启动容器
docker start 容器名称进入容器、启动容器、停止容器可以通过docker软件以可视化的方式完成
停止容器
docker stop 容器名称
- 删除容器
docker rm 容器名称 删除已经停止的容器,运行状态的容器会删除失败
- 查看容器信息
docker inspect 容器名称
数据卷配置
概念
数据卷是宿主机中的一个目录或文件
当容器目录和数据卷目录绑定后,对方的修改会立即同步
一个数据卷可以被多个容器同时挂载
一个容器也可以被挂载多个数据卷
作用
容器数据持久化
外部机器和容器间接通信
容器之间数据交换
配置数据卷
创建启动容器时,使用-v参数设置数据卷、
docker run ... –v 宿主机目录(文件):容器内目录(文件) ...
注意:目录必须是绝对路径,如果目录不存在会自动创建,可以挂载多个数据卷
Docker网络
网络模式
使用 Docker 时,宿主机和容器内系统、容器和容器之间都需要进行网络连接,因此要考虑容器和宿主机、容器和容器之间的网络连接方式,了解 Docker 的网络模式对正确使用 Docker 是非常重要的。
Docker 启动后,它默认会创建三个网络,使用 docker network ls 命令可以查看这些网络。
docker 自动创建了 bridge、host 和 none 3 种网络模式,默认情况下,使用的是 bridge 模式。
另外,用户还可以创建 Container 网络模式和自定义网络模式。在实际应用中,通过这 5 种网络模式就可以实现:
容器间的互联和通信
容器和宿主机的通信以及端口映射
容器 IP 变动时,可以通过服务名直接进行网络通信,不需要重新配置
Docker 中的网络接口默认都是虚拟的接口。对于本地系统和容器内系统来说,虚拟接口跟一个正常的以太网卡相比,是一样的。
Bridge(桥接模式)
Bridge 模式是 docker 默认的,也是最常使用的网络模式。
当 Docker 服务启动时:会在宿主机上创建一个名为 docker0 的虚拟网桥,并选择一个和宿主机不同的IP 地址(172.12.0.1)和子网(172.12.0.0/16)分配给 docker0 网桥,此主机上启动的 Docker 容器会连接到这个虚拟网桥上;
创建一个容器时,docker 也会为该容器创建独立的网络环境,保证容器内的进程使用独立的网络环境,同时还会将容器连接到 docker0 虚拟网桥;
通过宿主机上的 docker0 网桥,就实现了容器之间、容器与宿主机之间乃至外界进行网络通信。
docker network inspect bridge 查看docker0的相关信息
创建容器时,使用--network=bridge,参数表示使用 bridge 网络模式,该参数可以不写,默认情况下就是使用 bridge。命令:docker run --network=bridge
docker inspect r1 查看一个容器的网络信息
如果宿主机外的机器想访问容器,只能先访问宿主机,再使用端口映射来访问,即将容器的端口与宿主机的端口进行映射,供外面的机器访问
Host(主机模式)
如果启动容器的时候使用 Host 模式,那么这个容器将不会获得独立的网络命名空间,而是和宿主机共用一个 Network Namespace;容器也不会模拟出自己的网卡,配置自己的 IP 等,而是使用宿主机的 IP 和端口。但是,容器的其他方面,如文件系统,进程列表等还是和宿主机隔离的。
Host模式下虽然容器和宿主机的IP一样,但是端口号不同。
创建容器时,使用--network=host参数表示使用 host 网络模式。命令:docker run --network=host
none(无网络模式)
none 无网络模式下,容器有独立的 network namespace,但不对其进行任何网络设置。该模式实际上是关闭了容器的网络功能,容器不能联网。
Docker下使用Redis
搜索redis镜像
docker search redis下载redis镜像
docker pull redis不添加下载参数就是默认下载最新版本,默认补全为该命令
docker pull redis:latest新建redis容器
docker run -id --name redis_test -p 6379:6379 redis
Docker下使用MySql
docker run -d --name mysql_test_6367 -e MYSQL_ROOT_PASSWORD=wang10086 -p 6367:3306 mysql
MySQL安装_mysql :: download mysql installer (archived versio-CSDN博客
Docker下使用MongoDB
docker pull mongo拉取镜像
docker run -d --name mongodb -p 27017:27017 --privileged=true -v /d/mongodb/data:/data/db mongo
Redis数据持久化
概述
简介
持久化可以理解为数据的永久存储,就是将数据存储到一个不会丢失的地方。如果把数据放在内存中,电脑关闭或重启数据就会丢失,所以放在内存中的数据不是持久化的,而放在磁盘上就是一种持久化。Redis 的数据存储在内存中,内存是瞬时的,如果系统宕机或重启,又或者 Redis崩溃或重启,所有内存数据都会丢失,尤其是在 Redis 作为缓存使用时,数据丢失影响非常大。为解决这个问题,Redis 提供两种机制对数据进行持久化存储,以便发生故障后能迅速恢复数据。
Redis两种持久化方式
- RDB 默认的持久化方式,备份数据
- AOF 备份读写操作
具体操作
RDB
Redis Database(RDB),就是在指定的时间间隔内将内存中的数据集快照写入磁盘。每次进行数据写入时,为了不影响 Redis 服务的正常使用,都会通过 fork 方式创建一个新的写入子进程,将当前的数据以二进制的形式写入到 dump.rdb 文件中。当Redis 实例故障重启后,会自动从磁盘读取快照文件,恢复数据。快照文件称为 RDB 文件,保存了在某个时间点的全部数据,默认是保存在当前运行目录,默认文件名是 dump.rdb,该文件会自动创建。RDB 技术可能会造成主进程和子进程之间数据不同步,产生部分数据丢失现象,比较适合定期对数据做完整备份。
手动方式
执行 save 命令
执行save命令会使用主进程来执行RDB,这个进程中其他所有命令都会被阻塞,即redis无法对外提供服务,因此一般关闭redis之前或在数据迁移时可能会用到该命令。
执行 bgsave 命令
bgsave命令是异步执行RDB,执行后会开启子线程来完成EDB,主线程可以继续处理用户请求,不受影响。
执行 shutdown 命令时,Redis 自动执行 save 命令
执行该命令后会redis会自动执行save命令然后关闭服务器
自动方式
- 触发RDB方式(修改配置文件)
Redis的配置文件redis.conf中设置了出发RDB的机制,启动redis时可以指定绑定conf配置文件,其中的save参数下面有几个属性设置了执行RDB生成快照文件的时间策略。
配置格式:save
作用:在N秒内数据集至少有M个key改动,这一条件被满足时自动保存一次数据集,如“save 900 1”就是900秒内如果至少有1个key被修改,则执行bgsave命令。
注:可以根据系统需要,加入自己的触发机制,save “”表示禁用RDB

其他配置
dbfilename:设置 RDB 文件的名称
dir:指定 RDB 文件的存储位置
Rebcompression:是否压缩 RDB 文件
AOF
为解决 RDB 方式丢失数据的问题,从 1.1 版本开始,redis 增加了一种更加可靠的方式:AOF 持久化方式。Append-only File(AOF),Redis 每次接收到一条更新数据的命令时,它将把该命令写到一个 AOF 文件中(只登记写操作,读操作不登记)。当 Redis 重启时,它通过重新执行 AOF 文件中所有的命令来恢复数据。
配置(也是修改conf配置文件实现)
- Appendonly:开启 aof 功能
默认是no,给成yes是开启aof持久化
appendfilename:指定 AOF 文件名
默认文件名为 appendonly.aof ,可以修改。
dir:指定 RDB 和 AOF 文件存放的目录,默认是./
appendfsync:配置向 aof 文件写命令数据时的策略
有以下三种策略(对比在下面表格):
no:写命令执行完先放入 AOF 缓冲区,由操作系统决定何时将缓冲区内容写回磁盘;
always:表示每执行一次写命令,立即记录到 AOF 文件;
everysec:写命令执行完先放入 AOF 缓冲区,然后表示每隔 1 秒将缓冲区数据写到 AOF 文件,是默认方案。
| 配置项 | 刷盘时机 | 优点 | 缺点 |
|---|---|---|---|
| Always | 同步刷盘 | 可靠性高,几乎不丢数据 | 性能影响大 |
| everysec | 每秒刷盘 | 性能适中 | 最多丢死1秒数据 |
| no | 操作系统控制 | 性能最好 | 可靠性较差,可能丢失大量数据 |
Docker下的Redis实现数据持久化
RDB
- 将本地修改好的conf配置文件(记得把这个挂载的配置文件的save等允许持久化挂载打开并且有需要修改的修改)挂载数据卷到redis容器
现在的redis初始配置文件默认开启RDB了,会自动备份到data目录(容器运行目录)下,不做任何修改可以不挂载配置文件,直接执行下一步操作即可
docker run -p 6379:6379 --name redis -v /home/docker/redis/conf:/etc/redis/redis.conf -v /home/docker/redis/data:/data redis
这条命令就是把容器中/etc/redis/redis.conf映射到本地,本地/home/docker/redis/conf配置文件会挂载在容器的配置文件,修改会同步生效
docker run -p 6379:6379 --name redis -v /home/docker/redis/conf:/etc/redis/redis.conf -v /home/docker/redis/data:/data -d redis redis-server /etc/redis/redis.conf --appendonly yes
- 将容器data目录映射到本地(挂载data目录)
docker run -d --name redis1 -p 6379:6379 -v /d/redis/data:/data redis
这条命令主要就是-v部分去挂载数据卷,这里表示把本地D:\redis\data(如果路径不存在,Docker会自动创建)映射到容器内的路径(容器的data路径是容器内自动创建的目录)
示例命令(包括挂载conf和data)
docker run -id -p 6380:6379 --name redis2 -v C:/Users/GTR/Desktop/temp/大学上课学习/大三上/非关系型数据库/redis/conf:/etc/redis/redis.conf -v C:/Users/GTR/Desktop/temp/大学上课学习/大三上/非关系型数据库/redis/data:/data redis
AOF
修改配置文件并在挂载data后命令加上--appendonly yes表示开启aof数据持久化
运行起来后会发现在挂载的data目录下会出现appendolydir文件夹,该文件夹下自动生成了多个备份文件,这是因为在 redis7.x 以后,采取了 AOF 多文件存储技术。
示例命令
docker run -id -p 6380:6379 --name redis2 -v C:/Users/GTR/Desktop/temp/大学上课学习/大三上/非关系型数据库/redis/conf:/etc/redis/redis.conf -v C:/Users/GTR/Desktop/temp/大学上课学习/大三上/非关系型数据库/redis/data:/data redis --appendonly yes
Redis主从复制(适合中小型系统)
概述
简介
主从复制,是将多台数据库服务器分为主节点(master)和从节点(slaver),主节点数据更新后会根据配置和策略,自动同步到从节点上,从而保证主从节点中存有相同的数据。主从复制常见结构如下。

当有许多从节点时,可以采用主-从-从的链式结构,以减少主节点的压力

好处
- 默认实现读写分离机制,Master 以写为主,Slave 以读为主,提升系统的缓存读写性能;
容灾快速恢复,提升整个系统的可用性。因为从节点中有主节点数据的副本,当主节点宕机后,可以立刻提升其中一个从节点为主节点,继续提供服务;
数据备份,主从节点上都有数据,且都可以进行数据持久化处理;
支持高并发,提升数据库系统的请求处理能力。单个节点能够支撑的读流量有限。部署多个节点,并构成主从关系,主从节点一起提供服务。
简单实现数据同步
一开始6379为主节点,6380、6381为从节点,名称就是对应端口号
修改配置文件
修改其中的slaveof参数,这个参数指定成为哪一个master的从节点
启动主从服务器(一台主服务器,两台从服务器)
通过redis-server redis_6379.conf redis-server redis_6380.conf redis-server redis_6381.conf指定以哪个配置文件启动服务

6379主节点信息

6380从节点信息

6381从节点信息

- 测试数据同步

主从复制的容灾处理(手动)
手动关闭主节点(模拟主节点宕机)

将一个从节点提升为主节点,原先从节点挂载到新主节点上
slaveof no one: 将一台 slave 服务器提升为 Masterslaveof 主节点的 ip + 端口号: 将 slave 挂至新的 master 上


- 重启原先主节点,修改原先主节点为新主节点的从节点

哨兵模式
概述
简介
哨兵(Sentinel)是 Redis 官方提供的一种高可用方案,它可以监控多个 Redis 服务实例的运行情况,监控主节点是否出现故障。如果出现故障,它会根据投票数自动将某一个从节点提升为主节点,以继续对外提供服务。
本质上,Sentinel 也是一个运行在特殊模式下的 Redis 服务器。主从复制模式下,一般会配置多个 Sentinel 节点,通过互相协作来实现系统的高可用,如下图所示。

作用
主从监控:Sentinel 不断的检查主节点和从节点是否按照预期正常工作;
消息通知: Sentinel 会将故障和故障转移的结果通知客户端或其他应用程序;
自动故障转移:如果主节点异常,Sentinel 会自动进行故障迁移操作。即将一个从节点升级新的主节点,并让其他从服务器挂到新的主服务器,同时向客户端提供新的主服务器地址;
配置中心:客户端通过连接哨兵来获得当前 redis 服务的主节点地址。
原理
Sentinel 基于心跳机制监测服务状态,每隔 1 秒向集群的每个实例发送 ping 命令:
- 主观下线:如果某个 Sentinel 发现某个 redis 服务未在规定时间内(默认 30秒)响应,则认为该实例主观下线;
- 客观下线:若超过指定数(投票数)的 Sentinel 认为该 redis 服务主观下线,则该实例为客观下线,即哨兵模式确认该 redis 服务下线了。投票数的值最好超过 Sentinel 实例数量的一半。
具体样例搭建
一开始6379为主节点,6380、6381为从节点,26379、26380、26381分别为6379、6380、6381哨兵
修改配置文件
以哨兵1(监听6379服务器)的配置文件为例,修改端口号为26379(自己设定),修改sentinel monitor参数
Sentinel monitor <master-name> <masterIP> <masterPort><Quorum 投票数>参数说明
- Master-name:主节点的名字
- masterIP:主节点的 IP
- masterPort:主节点的端口号
- Quorum:判断主节点失效时,需要的哨兵节点的投票数
哨兵1样例
sentinel monitor mymaster 127.0.0.1 6379 2启动主从服务的三个Redis服务

启动三个哨兵服务
通过 redis-server sentinel_26379.conf –sentinel redis-server sentinel_26380.conf –sentinel redis-server sentinel_26381.conf –sentinel命令启动哨兵
可以通过
info sentinel命令查看哨兵运行情况

- 模拟主机宕机

主机宕机前后哨兵变化,可以看到主节点自动迁移到从节点了,从节点提升为主节点

6380变成了主节点

6379重启变成了从节点
6379重启后的主从结构

Docker下Redis实现哨兵模式
- 修改redis服务的配置文件
需要注意的是默认情况下新建一个redis主节点,其ip为172.17.0.2,端口号为6379,然后需要跟正常配置主从模式一样,要在配置文件中把6380和6381设置为是6379的从节点,这就需要知道主节点的ip以及端口号,但是如果存在建立过的docker容器可能主节点ip不同,所以可以先启动主节点,通过docker inspect 主节点容器名称 查看其ip再修改从节点配置文件以及启动从节点。
下面是各节点配置文件
主节点
1 | port 6379 |
从节点1
1 | port 6380 |
从节点2
1 | port 6381 |
- 搭建和运行1主2从服务
下面是运行例子的命令
新建主节点容器
1 | docker run -d --name redis_master -p 6379:6379 --privileged=true -v C:/Users/GTR/Desktop/temp/大学上课学习/大三上/非关系型数据库/redis/docker_sentinel/redis_6379.conf:/etc/redis/redis_6379.conf redis redis-server /etc/redis/redis_6379.conf |
新建从节点1容器
1 | docker run -d --name redis_slave1 -p 6380:6380 --privileged=true -v C:/Users/GTR/Desktop/temp/大学上课学习/大三上/非关系型数据库/redis/docker_sentinel/redis_6380.conf:/etc/redis/redis_6380.conf redis redis-server /etc/redis/redis_6380.conf |
新建从节点2容器
1 | docker run -d --name redis_slave2 -p 6381:6381 --privileged=true -v C:/Users/GTR/Desktop/temp/大学上课学习/大三上/非关系型数据库/redis/docker_sentinel/redis_6381.conf:/etc/redis/redis_6381.conf redis redis-server /etc/redis/redis_6381.conf |
新建容器完成后,可以进入主节点,通过info replication查看主从复制是否成功建立

- 修改哨兵的配置文件
修改配置需要修改的有端口号,以及添加sentinel指令去指定监听的redis服务的ip和端口、投票数
下面是各哨兵的配置
26379哨兵监听6379
1 | port 26379 |
26380哨兵监听6380
1 | port 26380 |
26381哨兵监听6381
1 | port 26381 |
- 创建哨兵节点
下面是运行例子的命令
新建26379哨兵监听6379节点
docker run -d –name redis_sentinel1 -p 26379:26379 –privileged=true -v C:/Users/GTR/Desktop/temp/大学上课学习/大三上/非关系型数据库/redis/docker_sentinel/redis_26379.conf:/etc/redis/redis_26379.conf redis redis-server /etc/redis/redis_26379.conf –sentinel
新建26380哨兵监听6380节点
docker run -d –name redis_sentinel2 -p 26380:26380 –privileged=true -v C:/Users/GTR/Desktop/temp/大学上课学习/大三上/非关系型数据库/redis/docker_sentinel/redis_26380.conf:/etc/redis/redis_26380.conf redis redis-server /etc/redis/redis_26380.conf –sentinel
新建26381哨兵监听6381节点
docker run -d –name redis_sentinel3 -p 26381:26381 –privileged=true -v C:/Users/GTR/Desktop/temp/大学上课学习/大三上/非关系型数据库/redis/docker_sentinel/redis_26381.conf:/etc/redis/redis_26381.conf redis redis-server /etc/redis/redis_26381.conf –sentinel
可以进入哨兵1容器,通过info sentinel查看整个哨兵结构

- 主从数据同步实验


- 自动处理故障
首先将master主节点停止,模拟宕机

可以发现6381节点自动变成了主节点,并且此时6381作为主节点,6380节点为从节点依然可以满足用户请求需求

重启6379节点,可以发现他自动变成6381的从节点了

最后主从结构为下图

Redis Cluster 分片集群
相关概念
分布式数据存储
分布式数据存储是一种计算机数据存储架构,它将数据存储在多台独立的数据库服务器上,以实现数据的高可靠性、可扩展性和性能。在分布式存储中,每个计算机或服务器都可以看作一个存储节点,它们通过网络连接相互通信和协作,以实现数据的分布式存储和管理,同时还采用可扩展的系统结构,不仅提高了系统的可靠性、可用性和存取效率,还易于扩展。
分布式存储通常使用数据分片和副本复制技术,以确保数据的可靠性和可用性。
为了确保数据在不同节点之间的一致性,分布式存储系统通常使用数据同步和管理机制。
在分布式存储系统中,数据可以并行地从多个节点中读取和写入,以提高读写性能和吞吐量。数据访问通常使用负载均衡机制来实现,例如,使用分布式哈希表、分布式缓存或分布式文件系统等技术来实现。(负载均衡是一种用于分布式计算和网络系统中的关键技术,旨在平衡服务器集群的负载,以确保每个服务器都能充分利用并均匀分担请求负荷。负载均衡机制有助于提高系统的可用性、性能和稳定性。)
数据分片
在分布式存储系统中,数据被分成多个部分,每个部分存储在不同的节点上,以实现数据的分布式存储和管理。数据分片通常使用哈希函数或一致性哈希算法等技术来实现。分布式数据存储首先要考虑的是如何将整体数据按照分片规则映射到多个存储节点上,让节点负责数据的一个子集。
副本复制
为了提高数据的可靠性和可用性,分布式存储系统通常使用副本复制技术。每个数据副本都存储在不同的节点上,以确保即使某些节点出现故障,仍然可以从其他节点中恢复数据。副本复制通常使用复制策略来实现,例如,简单的复制、多副本复制和跨区域复制等。
哈希取余分区
公式:
hash(key) % n(其中key可以为特定的数据,如键或用户ID;n为节点数量)优点:简单明了,常用于可以预估数据节点,或扩容/缩容不太频繁的应用场景,如使用 5 台服务器,就可以保证可支撑未来一段时间的数据请求处理。
缺点:当节点数量变化频繁时,如扩容或收缩节点,数据节点映射关系需要重新计算,会导致数据的重新迁移。
一致性哈希分区
一致性哈希算法:一致性哈希算法的目的是解决分布式数据变动和映射问题,在移除或者添加一个服务器时,能够尽可能小地改变已存在的服务请求与服务器之间的映射关系。
工作原理
- 构建哈希环:一致性哈希算法将整个哈希值空间映射成一个虚拟的圆环,即哈希环。整个哈希空间的取值范围为 0~2的32 次方-1,并按顺时针方向组织,最后的2的32次方和零点重合,形成哈希环;
- 服务器节点映射:可以选择服务器的 IP 或主机名作为 key,进行 hash 运算,将服务器也映射到了哈希环上;
- 数据读写映射:先根据 key 计算 hash 值,然后沿哈希环顺时针找到第一个大于等于该哈希值的服务器节点,即为该数据的服务节点。
优点:当增加一台新的服务器时,受影响的数据仅仅是新添加的服务器到其环空间中的前一台服务器(也就是顺着逆时针方向遇到的第一台服务器)之间的数据,其他节点都不会受到影响。因此,一致性哈希算法对于节点的增减,只需重新定位环空间中的一小部分数据,具有较好的容错性和扩展性。
缺点:不适合作为少量数据节点的分布式存储方案。在一致性哈希算法中,数据的分布和服务器节点的位置有关,这些节点不是均匀分布在哈希环上的。因此,当使用少量节点时,节点变化可能会影响哈希环中大范围的数据映射,产生数据倾斜问题(一部分数据集中在少数的节点或分区上,而其他节点或分区相对空闲),出现数据访问负载不均衡
虚拟一致性哈希分区
为了解决一致性哈希分区的缺点,一些分布式系统采用虚拟槽/虚拟节点对一致性哈希方法进行了改进,如虚拟一致性哈希分区方法。
虚拟一致性哈希分区为了让各节点能够保持动态的均衡,在每个真实节点上虚拟出若干个虚拟节点,再将这些虚拟节点随机映射到哈希环上。此时,每个真实节点就不再直接映射到环上了,它只负责管理一组环上的虚拟节点和实际存储的键值对数据。
这样,就形成了数据 - - 虚拟节点 - - 真实节点的映射关系。当对数据进行存取操作时,
首先映射到虚拟节点上,再由虚拟节点找到对应的真实节点。
如,三个真实节点: Node1、Node2 和 Node3,每个真实节点再虚拟出三个虚拟节点: V1,V2,V3,一共是 9 个虚拟节点。然后,这 9 个虚拟节点再映射到哈希环上。
这样,每个真实节点所负责的 hash 空间不再是连续的一段,而是分散在环上的各处,这样就可以将局部的压力均衡到不同的节点,虚拟节点越多,分散性越好,理论上负载就越倾向均匀
概述
Cluster 分片集群架构基本结构
Redis 哨兵模式虽然提供了 Redis 高可用、高并发读写的解决方案,但是在当前的一些互联网海量数据应用场景下,因为只有一组 master-slave 结构对外提供服务,数据的高并发写、数据备份和恢复都会大大降低效率,因此仍然存在海量数据存储问题、高并发和高可用等问题。
针对这些问题,Redis 推出 Cluster 分片集群架构,集群基本结构如下:

Redis分片集群实现了自动数据分片,实现了数据负载均衡,方便集群动态伸缩。(优点)
Cluster 分片集群架构特点
Redis Cluster 采用的是基于 P2P 的去中心化的网络拓扑架构,没有中心节点,支持多个 master 节点,所master 节点既是数据存储节点,也是监控节点;
引入槽(slot)的概念,通过 CRC + hashslot算法支持多个主节点(分片),每个主节点分别负责存储一部分数据,集群自动维护数据 – 哈希槽 – 节点之间的对应关系,这样理论上可以支持无限主节点的水平扩容以便支持海量吞吐量;
每个 master 节点又可以配置多个 slave 节点,支持读写分离;
内置类似哨兵的高可用机制,能够实现自动故障转移,保证每个 master 节点的高可用;
Master 节点之间通过 ping 监测彼此健康状态;
客户端请求可以访问集群任意节点,最终都会被转发到正确节点。
因此,Redis Cluster 集群也叫分片集群,是一个有多个主从节点群组成的分布式服务集群。它具有复制、高可用性和分布存储的特性。该集群不需要哨兵也可以完成节点故障自动转移功能,并可实现动态扩容(官方建议不要超过 1000 个节点)。Cluster 集群的性能和高可用性均优于哨兵模式,且集群配置非常简单,更加适合应用于海量数据、高并发和高可用的场景。
数据自动分片的实现
Redis参考虚拟一致性哈希分区的思想,提出了虚拟槽分区方案。哈希槽(hash slot)是 Redis 实现分片集群的基础,也是集群内数据管理和迁移的基本单位。虚拟槽的取值为整数,范围为 016383(02的14次方-1),每一个整数即为一个哈希槽。
具体步骤
预先设定哈希槽:共 16384 个哈希槽(默认数量);
为每个 Redis 节点分配哈希槽位:根据节点的性能分配槽位,一般是平均分配。分配后,该节点就负责管理这些槽的读写操作;
计算要写入数据的哈希槽:当在 master 节点上写入数据时,Redis 先对每个键(key)用 CRC16 + hashslot 算法进行运算,所得数值即为槽位号;
在对应节点上写入数据:寻找该槽位号所在的 Redis 节点,并在对应编号的哈希槽中写入数据;
读取数据: 计算该数据的槽位号,寻找该槽位所在的 Redis 节点,然后读取数据。
默认情况下虚拟槽位值的计算:slot = CRC16(key) mod 16383
Docker下简单实现
因为本身就是分布式实现,需要多台电脑,一台电脑多开虚拟机很卡,无法实践,这里这里借助docker简单展示使用
配置六个redis服务器,形成一主一从,一共3组的分片集群,修改所有节点的配置文件
主节点 1: IP:127.0.0.1 6379,配置文件:redis_6379.conf
主节点 2: IP:127.0.0.1 6380,配置文件:redis_6380.conf
主节点 3: IP:127.0.0.1 6381,配置文件:redis_6381.conf
从节点 4: IP:127.0.0.1 26379,配置文件:redis_26379.conf
从节点 5 :IP:127.0.0.1 26380,配置文件:redis_26380.conf
从节点 6 :IP:127.0.0.1 26381,配置文件:redis_26381.conf
主节点就以主节点1的配置文件修改为例,其他节点类似,修改端口号、打开分片集群、设置节点配置文件名
cluster-enabled yes表示开启分片集群cluster-config-file 配置文件名表示指定分片集群需要使用的节点配置文件名,这个指定的文件Redis自动创建,这里只需要给出配置文件名1
2
3
4port 6379
cluster-enabled yes
cluster-config-file nodes-6379.conf启动docker服务并创建6个Redis容器,并查看启动情况
主节点挂载data卷和redis配置卷,从节点挂载redis配置卷即可
1
2
3
4
5
6
7
8
9
10
11docker run -d --name redis_6379 -p 6379:6379 --privileged=true -v C:/Users/GTR/Desktop/temp/大学上课学习/大三上/非关系型数据库/redis/data/6379:/data -v C:/Users/GTR/Desktop/temp/大学上课学习/大三上/非关系型数据库/redis/docker_cluster:/etc/redis redis redis-server /etc/redis/redis_6379.conf
docker run -d --name redis_6380 -p 6380:6380 --privileged=true -v C:/Users/GTR/Desktop/temp/大学上课学习/大三上/非关系型数据库/redis/data/6380:/data -v C:/Users/GTR/Desktop/temp/大学上课学习/大三上/非关系型数据库/redis/docker_cluster:/etc/redis redis redis-server /etc/redis/redis_6380.conf
docker run -d --name redis_6381 -p 6381:6381 --privileged=true -v C:/Users/GTR/Desktop/temp/大学上课学习/大三上/非关系型数据库/redis/data/6381:/data -v C:/Users/GTR/Desktop/temp/大学上课学习/大三上/非关系型数据库/redis/docker_cluster:/etc/redis redis redis-server /etc/redis/redis_6381.conf
docker run -d --name redis_26379 -p 26379:26379 --privileged=true -v C:/Users/GTR/Desktop/temp/大学上课学习/大三上/非关系型数据库/redis/docker_cluster:/etc/redis redis redis-server /etc/redis/redis_26379.conf
docker run -d --name redis_26380 -p 26380:26380 --privileged=true -v C:/Users/GTR/Desktop/temp/大学上课学习/大三上/非关系型数据库/redis/docker_cluster:/etc/redis redis redis-server /etc/redis/redis_26380.conf
docker run -d --name redis_26381 -p 26381:26381 --privileged=true -v C:/Users/GTR/Desktop/temp/大学上课学习/大三上/非关系型数据库/redis/docker_cluster:/etc/redis redis redis-server /etc/redis/redis_26381.conf
docker创建容器

查看服务器启动情况

查询每个redis节点的容器内IP
docker inspect redis_63796379主节点

6380主节点

6381主节点

26379从节点

26380从节点

26381从节点

创建集群:将 6 个节点创建成 3 主 3 从的分片集群(最重要的步骤),到这里就搭建完成了,后面可以查看是否正确搭建
- 先进入一个容器(也可以在docker可视化里面进入容器,然后执行后面的命令就行)
1
docker exec -it redis_6380 /bin/bash
- 然后执行下面创建分片集群语句,然后输入yes后面出现绿色语句说明创建成功
1
redis-cli --cluster create 172.17.0.2:6379 172.17.0.3:6380 172.17.0.4:6381 172.17.0.5:26379 172.17.0.6:26380 172.17.0.7:26381 --cluster-replicas 1
redis-cli --cluster help查询集群创建相关参数
redis-cli --cluster create --cluster-replicas 1 <节点 1>,<节点 2>...
cluster create参数表示要创建集群;cluster-replicas 1表示1个主节点配置1个从节点
根据上面查询的IP地址,可以用最上面的命令创建分片集群,redis 会根据–cluster-replicas 1 参数,自动平均分配 6 个节点,前 3 个为主节点,后 3 个为从节点,这里的端口号也可以根据上面查询得到,也可以根据一开始创建容器的指令直接得到


连接任一节点,查看集群节点和集群状态信息
cluster nodes查看各节点信息,如主从配置信息,节点 ID 等
cluster info 显示集群的相关信息

搭建完成后读写操作
进入6381节点容器内并连接redis服务
docker exec -it redis_6381 /bin/bashredis-cli -c -p 6381这里一定要加上-c表示进入集群环境写入数据
集群会计算键等slot值,并存储到相应的redis节点上

查询数据
查询数据时也会计算slot值,然后从对应节点上拉取数据

查询集群各节点的数据存储情况
redis-cli --cluster check 任一节点 ip:端口号

搭建完成后的故障转移
- 停止6379,进入6380容器输入
redis-cli -p 6380 cluster nodes可以看到6379的fail说明出现问题并且26380成为master了

- 重启6379,再次查询集群节点信息,可以发现6379变成了从节点

搭建完成后的扩容
- 新建一个6382主节点,端口号为6382,配置文件类似前面6379主节点,创建这个容器并查看IP
1 | docker run -d --name redis_6382 -p 6382:6382 --privileged=true -v C:/Users/GTR/Desktop/temp/大学上课学习/大三上/非关系型数据库/redis/data/6382:/data -v C:/Users/GTR/Desktop/temp/大学上课学习/大三上/非关系型数据库/redis/docker_cluster:/etc/redis redis redis-server /etc/redis/redis_6382.conf |


进入任一节点,将6382节点加入到集群,默认是主节点
docker exec -it redis_6379 /bin/bashredis-cli --cluster add-node 172.17.0.8:6382 172.17.0.2:6379
查看集群节点信息

为6382节点分配4096个slot插槽(即4个主节点平均分配)
当前,6382 节点虽然已加入集群,但是没有 slot 插槽,不能使用,所以还需要为它分配插槽。
redis-cli --culuster reshard 集群中任一节点的 IP + port reshard表示在集群中重新分配slot插槽,后面接目标分配节点和端口号,这个命令中的IP和端口是集群中的任何一个可访问的节点的IP地址和端口,通常是用于执行reshard操作的源节点。这个节点将被用作数据的来源,从而将数据从一个源槽移动到目标槽。
redis-cli --cluster reshard 172.17.0.8:6382
然后输入分配的槽位4096,输入all表示平均分配,系统分配方案,输入yes表示同意该方案,等待分配,分配完没有报错即为正确


redis-cli --cluster check 172.17.0.3:6380 查看集群各节点数据存储情况

为6382主节点配置从节点26382
- 创建26382节点
1
docker run -d --name redis_26382 -p 26382:26382 --privileged=true -v C:/Users/GTR/Desktop/temp/大学上课学习/大三上/非关系型数据库/redis/docker_cluster:/etc/redis redis redis-server /etc/redis/redis_26382.conf

- 为6382节点指定26382从节点,进入主节点执行
1
redis-cli --cluster add-node 172.17.0.9:26382 172.17.0.8:6382 --cluster-slave --cluster-master-id dc3f89457c6038e72b5f70a7b44af39f9b748c58
redis-cli --cluster add-node 新节点IP 旧节点IP --cluster-slave --cluster-master-id 指定的主节点的容器 id
补充(手动迁移槽位)
指定从某个节点移动多少个槽位到指定节点,这里把6382所有节点移动到6379节点


搭建完成后的缩容
(在Redis Cluster中,你可以从集群中移除节点,然后再重新分配虚拟槽。这个过程不会导致数据丢失,因为Redis Cluster具有数据复制和故障转移机制,可以确保数据的可靠性。)
缩容可以先备份数据,然后从集群中删除节点,之后通过上面的方法手动迁移删除的节点的槽位到其他节点(也可以直接均匀分配槽位,都是同个命令,同上面),等待槽位迁移完成后,验证集群状态。(也可以先迁移槽位再删除节点,这种方式更加安全)
1 | redis-cli --cluster reshard 172.17.0.3:6380 --cluster-from 2bea24374ee6403d86cd5fb2d81ff1f55640471f --cluster-to ffa0585637379e96c91b6f6f8de7f7aa3248567f --cluster-slots 4096 |
这条指定可以直接把第一个容器2bea24374ee6403d86cd5fb2d81ff1f55640471f指定的槽位数4096转移到第二个容器ffa0585637379e96c91b6f6f8de7f7aa3248567f(可以直接用这条命令,会更快一点)
cluster slots检查槽位分配情况
cluster nodes验证集群状态
redis-cli --cluster del-node 172.17.0.2:6379 c6a46b48e977b86b369c6b25f8b146cdf4f94655删除节点
Java连接数据库(MySQL和Redis)
前言
关于Maven和SpringBoot的配置和创建
【精选】IDEA配置Maven(详细版)_idea maven-CSDN博客
JUnit单元测试框架的基本介绍和使用
非关系型数据库这门课程主要是介绍Redis相关的,这部分主要介绍使用关于Java访问Redis以及Redis搭配MySQL的使用,需要应用到的主要有Jedis、JDBC、SpringDataRedis、SpringBoot、MyBatis,案例可以直接通过文档最顶部的网盘链接打开
Jedis API访问Redis
基于Maven项目导入依赖
1
2
3
4
5<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>3.7.0</version>
</dependency>基本使用,使用单元测试框架进行展示
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPubSub;
import java.util.List;
import java.util.Map;
import java.util.Set;
import java.util.concurrent.TimeUnit;
/**
* @className JedisDemo
* @date 2022/6/21
**/
public class JedisDemo {
Jedis jedis;
public void before() {
this.jedis = new Jedis("127.0.0.1", 6379);
}
public void after() {
//关闭jedis
this.jedis.close();
}
/**
* 测试redis是否连通
*/
public void test1() {
String ping = jedis.ping();
System.out.println(ping);
}
/**
* string类型测试
*/
public void stringTest() {
jedis.set("site", "http://www.itsoku.com");
System.out.println(jedis.get("site"));
System.out.println(jedis.ttl("site"));
}
/**
* list类型测试
*/
public void listTest() {
jedis.rpush("courses", "java", "spring", "springmvc", "springboot");
List<String> courses = jedis.lrange("courses", 0, -1);
for (String course : courses) {
System.out.println(course);
}
}
/**
* set类型测试
*/
public void setTest() {
jedis.sadd("users", "tom", "jack", "ready");
Set<String> users = jedis.smembers("users");
for (String user : users) {
System.out.println(user);
}
}
/**
* hash类型测试
*/
public void hashTest() {
jedis.hset("user:1001", "id", "1001");
jedis.hset("user:1001", "name", "张三");
jedis.hset("user:1001", "age", "30");
Map<String, String> userMap = jedis.hgetAll("user:1001");
System.out.println(userMap);
}
/**
* zset类型测试
*/
public void zsetTest() {
jedis.zadd("languages", 100d, "java");
jedis.zadd("languages", 95d, "c");
jedis.zadd("languages", 70d, "php");
List<String> languages = jedis.zrange("languages", 0, -1);
System.out.println(languages);
}
/**
* 订阅消息
*
* @throws InterruptedException
*/
public void subscribeTest() throws InterruptedException {
// subscribe(消息监听器,频道列表)
jedis.subscribe(new JedisPubSub() {
public void onMessage(String channel, String message) {
System.out.println(channel + ":" + message);
}
}, "sitemsg");
TimeUnit.HOURS.sleep(1);
}
/**
* 发布消息
*
* @throws InterruptedException
*/
public void publishTest() {
jedis.publish("sitemsg", "hello redis");
}
}
SpringDataRedis API访问Redis集群
这里给定的是一个基于spring boot 的java web项目
- 首先需要基于docker搭建redis集群环境
其中的cluster-announce-ip是用来宣告IP的,需要的是一个可访问redis的IP,不宣告则为本地IP,这里宣告为本地IP
6380
1 | port 6380 |
6381
1 | port 6381 |
6382
1 | port 6382 |
6383
1 | port 6383 |
6384
1 | port 6384 |
6385
1 | port 6385 |
- 创建容器
1 | docker run -id --name redis_6380 -p 6380:6380 -p 16380:16380 --privileged=true -v C:/Users/GTR/Desktop/temp/大学上课学习/大三上/非关系型数据库/redis/data/6380:/data -v C:/Users/GTR/Desktop/temp/大学上课学习/大三上/非关系型数据库/redis/conf_cluster:/etc/redis redis redis-server /etc/redis/redis-6380.conf |
- 进入容器并创建集群
1 | //进入容器 |
- 案例
这个类是对redis的相关操作
1 | package com.example.demo.controller; |
pom.xml文件中导入了相关的依赖
1 | <?xml version="1.0" encoding="UTF-8"?> |
application.yml和application.properties文件配置文件的作用一样,但是格式不一样,配置文件中配置了对redis数据库的访问信息
下面是application.yml的配置
1 | spring: |
MyBatis框架
ORM框架连接MySQL: ORM(Object-Relational Mapping)框架是一种将对象和关系数据库进行映射的技术。MyBatis就是一种ORM框架。
简单学习
MyBatis的入门学习(增删改查)_mybatis增删改查项目demo-CSDN博客
mybatis看这一篇就够了,简单全面一发入魂-CSDN博客
配置文件
spring boot +mybatis(通过properties配置) 集成-CSDN博客
也可以通过.yml文件配置,两者作用一样就是书写方式有些区别
Spring-Boot (二) application.properties配置文件内容_springboot application.properties配置-CSDN博客
如何实现spring boot redis 集群 配置的具体操作步骤_mob649e81664bd9的技术博客_51CTO博客
集群配置中,如spring.redis.cluster.nodes=redis1:6379,redis2:6379,redis3:6379中redis1、redis2和redis3是Redis集群中的三个节点的主机名或IP地址,6379是这些节点上Redis服务器的端口号,也可以直接使用IP进行配置,这里是本地使用Docker创建了几个容器并且配置了集群环境
1 | # 集群信息 |
1 | # Redis集群配置 |
Redis作为MySQL缓存应用
一般流程如下

需要解决的一些问题
(5 封私信 / 20 条消息) Redis 缓存和 MySQL 数据保持一致性的方法有哪些? - 知乎 (zhihu.com)
Redis - 缓存雪崩,缓存穿透,缓存击穿_雪崩redis_MinggeQingchun的博客-CSDN博客
缓存雪崩是指在同一时段,Redis 中的缓存 key 大面积同时失效,或者 Redis 服务宕机,导致大量的数据请求直接面向 MySQL 数据库,给数据库造成巨大压力,可能带来灾难性的问题。
解决相关问题出现的一些知识回顾
样例实现
下面代码为学习过程中仿照给定代码进行书写的,整个样例实现了Redis作为MySQL的缓存并且Redis开启了三主三从的集群,同时对缓存穿透、缓存雪崩、缓存击穿作出了一些简单的处理
整个样例下载路径
https://wwcz.lanzout.com/b04kt8wla
密码:2wdy
- 首先需要在MySQL数据库中存在一个名为week_10的数据库,并且在其中创建一张名为student的表
1 | create table student |
- 使用Docker创建集群环境,创建方法在上面讲了,创建的集群跟上面一样
跳转查看集群创建
使用上面构建SpringBoot项目的方法创建项目并通过maven导入依赖
1 |
|
application.properties配置文件
该文件位于resources文件夹下
1 | #mysql配置 |
注:也可以使用.yml配置文件进行配置,下面放出两者的区别的介绍博客
SpringBoot之yml与properties配置文件格式的区别 - 彼岸舞 - 博客园 (cnblogs.com)
- 首先需要了解这几层再进行代码书写,各层放在了项目不同文件夹下,可以看项目结构了解
经典的四层架构,通常在使用 Spring 框架进行开发时会采用这种结构。下面是每一层的主要职责:
Pojo层(Model层):
- 主要包含应用程序的领域模型,通常是实体类(Entity)或者简单的 Java Bean。
- 用于表示业务数据以及业务规则。
Mapper层(Data Access层):
- 负责数据的持久化,与数据库进行交互。
- 包含数据访问对象(DAO)或者 Repository。
- 可以使用 ORM 框架(如 MyBatis 或 Hibernate)简化数据库操作。
Service层:
- 业务逻辑的处理中心,负责处理应用程序的业务规则。
- 调用 Mapper 层进行数据库操作,协调不同的业务逻辑。
- 提供事务管理、安全性等服务。
Controller层:
- 处理用户请求,接收用户输入,调用 Service 层处理业务逻辑,最终返回结果给用户。
- 负责与用户界面进行交互,通常是通过 HTTP 请求和响应。

- 配置 Spring Boot 项目中 Redis 连接和序列化的类
1 | package com.example.week10_redis_20211003238.config; |
RedisConnectionFactory 是 Spring Data Redis 中的一个关键接口,它定义了用于创建 RedisConnection 对象的工厂方法。RedisConnection 表示与 Redis 数据库的连接,可以用于执行各种 Redis 操作,例如读写数据、执行事务、发布和订阅消息等。
RedisConnectionFactory 的主要作用是抽象出连接 Redis 所需的细节,包括连接池配置、连接超时、主从配置等。通过实现这个接口,可以灵活地配置和管理与 Redis 的连接。
在 Spring 中,RedisConnectionFactory 的实现通常使用第三方的 Redis 客户端库,比如 Jedis 或 Lettuce。这些实现隐藏了底层连接细节,同时提供了一些配置选项,以满足不同应用场景的需求。
以下是 RedisConnectionFactory 的一些常见实现:
JedisConnectionFactory: 使用 Jedis 作为底层连接库,适用于传统的阻塞式 I/O 模型。
LettuceConnectionFactory: 使用 Lettuce 作为底层连接库,适用于基于 Netty 的非阻塞式 I/O 模型,支持更多高级特性,例如异步操作和响应式编程。
通过配置 RedisConnectionFactory,你可以轻松地切换底层连接库,同时可以设置连接池、超时时间、主从配置等参数,以满足具体应用的性能和可用性要求。
- pojo层
1 | package com.example.week10_redis_20211003238.pojo; |
- mapper层
StudentMapper
1 | package com.example.week10_redis_20211003238.mapper; |
StudentMapper.xml
1 |
|
- service层
StudentService
1 | package com.example.week10_redis_20211003238.service; |
StudentServiceImpl
1 | package com.example.week10_redis_20211003238.service.impl; |
- controller层
1 | package com.example.week10_redis_20211003238.controller; |
这里解决缓存雪崩介绍了缓存预热怎么做,具体做法没有实现,就是把框架搭出来,需要怎么预热自己再写,写在了cache下的RedisWarmUp类中
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18package com.example.week10_redis_20211003238.cache;
import org.springframework.boot.ApplicationArguments;
import org.springframework.boot.ApplicationRunner;
import org.springframework.stereotype.Component;
/*
* Redis缓存预热:实现ApplicationRunner接口
* */
//@Component是一个通用性注解,用于表示一个类是Spring容器中的一个组件
public class RedisWarmUp implements ApplicationRunner {
public void run(ApplicationArguments args) throws Exception {
System.out.println("缓存数据开始预热....");
//之后可以使用RedisTemplate将一些数据先加入到缓存之中,再结束预热
}
}修改Application入口代码,加上注解即可
1 | package com.example.week10_redis_20211003238; |
- 之后可以运行起来,再浏览器测试controller中的代码
压力测试
【好物推荐】性能测试之压力测试,如何使用Jmeter来压测接口?_jmeter接口压测_本本本添哥的博客-CSDN博客
MongoDB
安装
- 社区版本安装
- 下载安装包并进行安装
安装过程可以选择data和log的存放路径,安装程序还是会安装到默认路径,所以安装时还是直接用默认路径吧,bin目录在C:\Program Files\MongoDB\Server\7.0\bin,并且为了方便,安装时直接选择Complete选项安装所有组件吧。
- mongod.exe:启动数据库服务器实例进程的可执行文件,是整个 MongoDB中最核心的内容,可进行复制数据库的创建、删除等管理工作,运行在服务器端为客户端提供监听;
- mongos.exe:分片集群的控制器和查询路由器;
- mongod.conf:系统配置文件。

- 配置环境变量

配置好环境后可以输入mongod --version就可以查看到MongoDB的版本
- 之后启动服务就好,MongoDB默认端口为27017,可以在浏览器输入
http://localhost:27017/,有响应就说明服务已启动,也可以在系统服务界面找到服务。
- 进行一些配置
在默认情况下,MongoDB中创建的数据库文件会存储在C:\Program Files\MongoDB\Server\7.0\data路径下,实际开发中需要我们指定存放的路径,下面给出具体的配置方式。
创建存放数据库文件和日志文件的文件夹,一个文件夹为data,一个文件夹为log,具体创建在哪里视自己情况来定吗,路径不能带中文
修改配置文件,7.0版本配置文件在bin目录下,名为
mongod.cfg,注意这里log的写法,这里我的log文件在mongodb路径下,后面加上\mongod.log
重启服务器生效
无法启动检查路径是否为英文,还是不行可以以管理员打开cmd或者powershell窗口下输入sc delete MongoDB删除原有服务,之后输入 mongod --install -f "C:\Program Files\MongoDB\Server\7.0\bin\mongod.cfg"重新安装配置文件,之后点击启动即可
- 安装MongoDB Shell工具
早期的MongoDB版本中自带这个工具,在当前7.0版本中不包含该工具,需要另外下载,MongoDB Shell工具是MongoDB服务器常用客户端访问工具
- 下载MongoDB Shell工具
下载压缩文件即可,安装程序也是安装到跟Mongo服务器的默认路径一样,将压缩文件放到跟Mongo服务器的默认路径下,这样好找,路径为C:\Program Files\MongoDB\Server\7.0\bin,之后解压
- 配置环境
将解压后的文件中的bin目录也加入到环境变量中,相关路径在上面服务器的环境变量配置中框起来的下一条就是了,这里不另外截图了。配置环境后在命令行输入mongosh可以连接到服务器
- 安装MongoDB Compass
MongoDB Compass是官方提供的图形界面,在安装server时可以直接选择安装,也可以单独安装
- Docker中安装MongoDB
- 拉取MongoDB的镜像
docker pull mongo 记得先开启Docker
- 查看下载的镜像
docker images
- 启动一个MongoDB服务器容器
docker run -d --name mongodb -p 27017:27017 --privileged=true -v /d/mongodb/data:/data/db mongo 这里将数据卷挂载在本地的D:/mongodb/data
- 之后可以通过shell工具连接服务器容器
MongoDB简单操作
查询
聚合查询
索引
MongoDB备份和恢复
MongoDB复制集
概述
相关概念
为了提高系统的高可用,MongoDB 提供了数据复制功能。MongoDB 支持两种数据复制功能:传统的主从复制和副本集/复制集。副本集在传统主从复制的基础上,支持故障自动恢复功能,提供了更好的可用性,也是 MongoDB 官方推荐的集群部署方式。
副本集(Replica Set)是一组 MongoDB 实例保持其相同数据集的集群,即由一个主(Primary)服务器和多个副本(Secondary)服务器构成。通过复制(Replication)将数据的更新由主服务器推送到其它副本服务器上,实现每个 MongoDB 实例维护相同的数据集副本。
功能
- 数据备份
- 读写分离
- 自动故障转移
构成
主节点(Primary)
主节点是副本集中负责处理客户端请求和读写数据主要成员。主节点通过 oplog(操作日志)记录所有操作。副本集中有且只有一个主节点,如果当前主节点不可用,则会从副本节点中选举出新的主节点。
副本节点(Secondary)
副本节点定期轮询主节点获取 oplog 记录的操作内容,然后对自己的数据副本执行这些操作,从而保证副本节点的数据副本与主节点保持一致。副本集中可以有一个或多个副本节点。当主节点宕机时,副本集会根据优先级等参数选举出新的主节点。
仲裁节点(Arbiter)
仲裁节点不存储数据,只是负责通过心跳包来确认集群中节点的数量,并在主服务器选举的时候作为仲裁决定结果。仲裁节点需要的资源很小。当副本集中节点个数为偶数时,建议添加一个仲裁节点,防止选举新的主节点过程中出现票数一致,导致无法选举出新的主节点。
默认配置
主节点负责处理所有的写入请求;主节点(默认)和副节点都可以处理读取请求;副节点从主节点(或符合条件的副节点)处复制数据;
每个节点都会向其它节点发送心跳请求;每隔 2 秒发送一次,超过 10 秒则请求超时(默认);副本集中最多可以有 50 个节点。
选举
主节点与副节点之间的心跳请求超时、复制集初始化、新节点加入复制集会触发选举事件。
副本集通过 replSetInitiate 命令(或 mongo shell 的 **rs.initiate()**)进行初始化。初始化后,各个成员之间开始发送心跳消息,并发起 Priamry 节点的选举操作。获得大多数成员投票支持的节点,会成为 Primary 节点,其余节点成为Secondary 节点。假设复制集内投票成员数量为 N,则大多数为 N/2 + 1,当复制集内存活成员数量不足大多数时,整个复制集将无法选举出 Primary,复制集将无法提供写服务,处于只读状态。
被选举为主节点的节点必须能够与多数节点建立连接、具有较新的 oplog、具有较高的优先级(如果有配置)
搭建
创建三个容器
下面可以将数据卷更改成为自己需要保存的位置,其中
--replSet "rs0"指定副本集的名称为rs0,--bind_ip_all表示允许所有IP连接1
2
3
4
5docker run -d --name mongo_1 -p 27018:27017 --privileged=true -v /d/mongodb/replicaSet/mongo_1:/data/db mongo --replSet "rs0" --bind_ip_all
docker run -d --name mongo_2 -p 27019:27017 --privileged=true -v /d/mongodb/replicaSet/mongo_2:/data/db mongo --replSet "rs0" --bind_ip_all
docker run -d --name mongo_3 -p 27020:27017 --privileged=true -v /d/mongodb/replicaSet/mongo_3:/data/db mongo --replSet "rs0" --bind_ip_alldocker ps查看存在容器初始化副本集
初始化副本集,通过
rs.initiate()选举出主节点,首先需要知道自己本机的IP地址,然后将下面的的IP地址更改成为本机的IP地址即可在cmd窗口连接,或者在docker可视化软件进行操作,这里我的IP是192.168.3.226通过
mongosh 192.168.3.226:27018连接其中任何一个mongo服务器即可,然后执行下面命令初始化主节点(注意IP),返回{ok:1}表示创建成功1
2
3
4
5
6
7
8rs.initiate( {
_id : "rs0",
members: [
{ _id: 0, host: "192.168.3.226:27018" },
{ _id: 1, host: "192.168.3.226:27019" },
{ _id: 2, host: "192.168.3.226:27020" }
]
})
rs.conf() 查看副本集配置信息
rs.status() 查看副本集状态,可以看到哪个节点是主节点
这里副本集就搭建完成了,可以进行数据同步验证
首先在主节点插入数据
db.user.insert({"id":1001,"name":"zhangsan"})然后可以在主节点查询数据(新开一个cmd窗口连接到另外一个从节点服务器执行下面查询)
db.user.find(),这时会发现默认情况下从节点不允许读写操作,需要在连接的从节点执行db.getMongo().setReadPref("secondary")命令,这是再查询就可以查询到数据了
下面也可以进行读写分离实验,这个比较简单,在从节点执行写操作会发现不允许进行,只允许在主节点进行写操作
故障自动转移实验:
首先在docker可视化界面中手动暂停主节点服务器,然后在从节点通过
rs.status()可以发现集群选举出了新的主节点,进行了故障转移。重新启动旧的主节点会自动变成从节点。
加入仲裁节点
- 新建一个节点容器
1 | docker create --name mongo04 -p 27021:27017 -v mongo-data-04:/data/db mongo:4 --replSet "rs0" --bind_ip_all |
- 重新配置副本集的写关注
在副本集中,WriteConcern(写关注)配置是决定一个写操作落到多少个节点上才算是成功的参数。WriterConcern 的取值包括:
- 0:发起写操作,不关心是否成功
- 1:默认值,primary 节点完成写操作, 就可以返回确认写成功的消息
- n:表示写操作需要被复制到指定节点数才算成功
- majority:写操作需要被复制到大多数节点上才算成功
由于在副本集中,添加了仲裁节点,可能会导致默认 WriterConcern 发生改变,所以需要再配置一下 setDefaultRWConcern 的内容。
在复制集中的一个节点输入下面命令
1 | db.adminCommand({ |
- 将仲裁节点接入复集
1
rs.addArb("192.168.3.226:27021")
之后可以通过rs.status()查询复制集信息
MongoDB分片集群
概述
相关概念
MongoDB 分片是 MongoDB 支持的另一种集群形式,它可以满足 MongoDB 数据量呈爆发式增长的需求。当 MongoDB 存储海量的数据时,一台服务器可能无法满足数据存储的需求,就可以通过在多台机器上对海量数据进行划分(即分片),使得 MongoDB 数据库系统能够存储和处理更多的数据。
MongoDB 数据库提供了数据自动分片功能,它内置了多种分片逻辑,使得 MongoDB可以自动处理分片数据,也可以很容易的管理分片集群。
构成
- 分片服务器(Mongod/Shard)
即 MongoDB 实例(mongod,用 Shard 表示)。分片服务器是实际存储数据的组件,持有完整数据集中的一部分。每个分片服务器都可以是一个 MongoDB 实例,也可是一组MongoDB 实例组成的集群(副本集)。从 MongoDB 3.6 开始,必须将分片部署为副本集,这样具有更好的容错性。
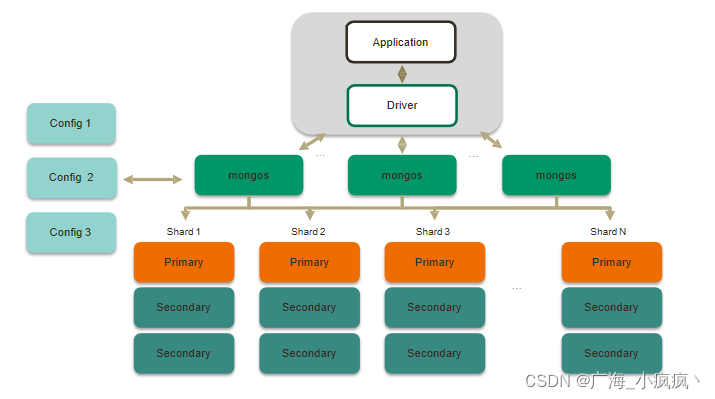
- 路由服务器(Mongos)
即 Mongos。路由服务器主要提供客户端应用程序与分片集群交互的接口,所有请求都需要通过路由服务器进行协调工作。Mongos 实际上就是一个消息分发请求中心,它负责把客户端应用程序对应的数据请求转发到对应的分片服务器上。应用程序将查询、存储、更新等请求原封不动地发送给 Mongos, Mongos 询问配置服务器操作分片服务器需要获取哪些元数据,然后连接相应的分片服务器进行相关操作,最后将各个分片服务器的响应进行合并,返回给客户端应用程序。生产环境中,一个分片集群通常会有多个路由服务器,一方面可以解决多个客户端同时请求,从而达到负载均衡的效果;另一方面可以解决当路由服务器宕机时导致整个分片集群无法使用的问题。
- 配置服务器(Config Server)
即 Config Server。它存储了分片集群的元数据(如,每个集群上有多少分片,数据存储范围等信息),存储了集群的认证和授权配置,这些数据是不允许丢失的。因此,在生产环境中,通常需要配置多个配置服务器以防止数据丢失。从 MongoDB 3.4 版本开始,配置服务器必须部署副本集,因此一般需要配置三个配置服务器组成的副本集。配置服务器存储着分片集群的持久化元数据,而路由服务器存储着分片集群的非持久化元数据,这些数据均为内存缓存的数据。当路由服务器初次启动或关闭重启时,就会从配置服务器中加载分片集群的元数据。若是配置服务器的信息发生变化,则会通知所有路由服务器更新自己的状态,这样路由服务器就能继续准确的协调客户端与分片集群的交互工作。
从上图可以看出,每个分片存储一部分数据,需要部署为复制集;mongos 路由可以将客户请求发送至相关的分片,同时与配置服务器通信,一般部署多台;配置服务器保存集群配置和元数据,需要部署为复制集。
分片优点
- 对集群进行抽象,让集群“不可见”
Mongos 就是掌握统一路口的路由器,其会将客户端发来的请求准确无误的路由到集群中的一个或者一组服务器上,同时会把接收到的响应拼装起来发回到客户端。
- 保证集群总是可读写
MongoDB 通过多种方法来确保集群的可用性和可靠性。如,将 MongoDB 的分片和副本集功能结合使用,在确保数据分片到多台服务器的同时,也确保了每分数据都有相应的备份,这样就可以确保有服务器宕机时,其他的从节点可以立即接替工作。
- 使集群易于扩展
当系统需要更多的空间和资源的时候,可以按需方便的扩充系统容量。
一般分片步骤
- 分析数据库中的哪些集合的数据,需要进行分片存储;
- 指定每个集合的分片键(Shard Key),分片键可以是集合文档中的一个或多个字段;
- 制定分片策略,如是范围分片还是哈希分片;
- 分片键会将集合数据划分为多个块(Chunk)(默认大小为 64MB,每个块均表示集合中数据的一部分);
- MongoDB 根据分片策略和分片键,将划分的块分发到分片集群中。
内置分片策略
- 范围分片
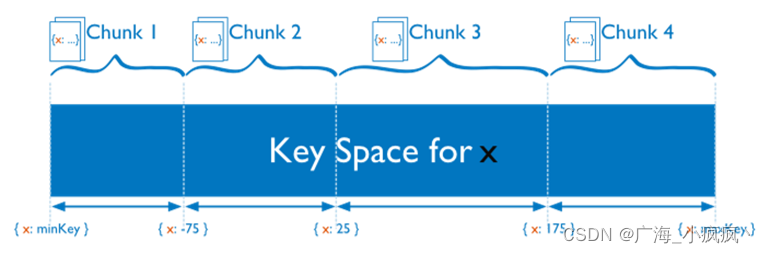
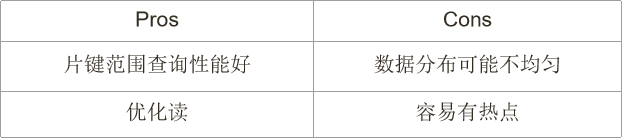
- 哈希分片
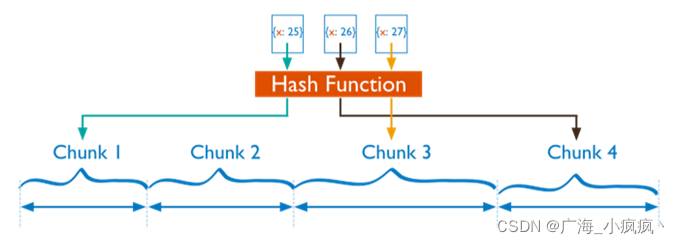

分片键的选择
MongoDB 分片集群中,分片键的选择很重要。分片键的选择标准包括:
- 分片键值的取值范围大,或称基数大(如使用布尔值做片键就不合适);
- 分片键值的取值分布较均衡,取值不要集中在某一个范围内;
- 分片键值不要单向增大或减小,以防产生数据不均衡;
- 分片键值要方便查询;
在实际选择分片键时,可以使用 hash 运算,增加分片键值的随机性;可以使用复合片键,扩大键值的取值基数。
分片集群数据库的分裂
数据块 chunk
在一个分片节点中,MongoDB 会根据分片键,将集合数据划分为多个块(Chunk)。系统初始时产生 1 个 chunk,每个 chunk 默认大小为 64MB,存储了集合中一部分数据。chunk 的产生,有以下两个用途:
分裂 Splitting:当一个 chunk 的大小超过配置中的 chunk size 时,MongoDB 的后台进程会自动把这个 chunk 切分成更小的 chunk,从而避免chunk 过大;
均衡 Balancing:在 MongoDB 中,balancer 是一个后台进程,会负责监视和调整集群的平衡,负责 chunk 的迁移,从而均衡各个分片节点的负载。
搭建
1. 首先需要了解结构
这里共需要11个节点,3 个 Config Server 节点构成的副本集,2 个 shard 集群。每个集群又是一个副本集,包括 1 主 1 从和 1 个仲裁节点,2 个 mongos 节点,具体的配置文件可以下载实验材料找到具体内容找到
2. 搭建3个Config节点构成的副本集
这里有3个节点,分别为conf_1、conf_2、conf_3,IP都为本机回环地址127.0.0.1,端口号分别为17000、17001、17002,副本集名称为rs_conf,配置文件为mongo.cfg
配置文件主要参数
1 | # 日志文件 |
执行命令创建3个config节点容器
1 | docker run -d --name conf_01 -p 17000:27017 --privileged=true -v C:/mongodb/docker/mongodb/cluster/conf/confServ:/data/configdb -v C:/mongodb/docker/mongodb/cluster/data/conf_01:/data/db -v C:/mongodb/docker/mongodb/cluster/logs/conf_01:/data/logs mongo --config /data/configdb/mongo.cfg |
副本集初始化
连接170000节点
1 | mongosh 127.0.0.1:17000 |
输入命令初始化,注意IP
1 | rs.initiate( |
输入rs.status()查看Config server 集群信息


3. 创建2个shard集群
集群1
集群1有3个节点,分别为shardsvr_01、shardsvr_02 、shardsvr_03(仲裁节点),IP都为本机回环IP,端口号分别为27018、27019、27020,副本集的名称为rs_shard01 、配置文件为mongo_1.cfg,配置文件内容如下
1 | # 日志文件 |
集群2
集群1有3个节点,分别为shardsvr_04、shardsvr_05 、shardsvr_06(仲裁节点),IP都为本机回环IP,端口号分别为27021、27022、27023,副本集的名称为rs_shard02 、配置文件为mongo_2.cfg,配置文件内容如下
1 | # 日志文件 |
创建rs_shard01 集群
创建容器
1 | docker run -d --name shardsvr_01 -p 27018:27017 --privileged=true -v C:/mongodb/docker/mongodb/cluster/conf/shardServ:/data/configdb -v C:/mongodb/docker/mongodb/cluster/data/shardsvr_01:/data/db -v C:/mongodb/docker/mongodb/cluster/logs/shardsvr_01:/data/logs mongo --config /data/configdb/mongo_1.cfg |
mongosh 127.0.0.1:27018进入服务器,然后输入下面命令初始化集群
1 | rs.initiate( { |



创建rs_shard02 集群
创建容器
1 | docker run -d --name shardsvr_04 -p 27021:27017 --privileged=true -v C:/mongodb/docker/mongodb/cluster/conf/shardServ:/data/configdb -v C:/mongodb/docker/mongodb/cluster/data/shardsvr_04:/data/db -v C:/mongodb/docker/mongodb/cluster/logs/shardsvr_04:/data/logs mongo --config /data/configdb/mongo_2.cfg |
mongosh 127.0.0.1:27021进入服务器,然后输入下面命令初始化集群
1 | rs.initiate( { |



4. 创建2个Mongos节点
两个节点分别为mongos_01和mongos_02,IP都为本机回环地址,端口号分别为30001和30002,配置文件为mongo.cfg,配置文件内容如下(自己搭建的时候记得把配置文件的IP修改成自己的本机现在的实际IP)
1 | # 日志文件 |
创建2个容器
1 | docker run -d --name mongos_01 -p 30001:27017 --privileged=true --entrypoint "mongos" -v C:/mongodb/docker/mongodb/cluster/conf/mongos:/data/configdb -v C:/mongodb/docker/mongodb/cluster/logs/mongos_01:/data/logs mongo --config /data/configdb/mongo.cfg |

在mongos_01节点添加2个shard 集群
mongosh 127.0.0.1:30001连接30001节点
然后输入下面命令配置WriteConcern 参数(如果需要)
1 | db.adminCommand({ |

在mongos_01中添加第一个shard 集群的节点
1 | sh.addShard("rs_shard01/192.168.3.226:27018,192.168.3.226:27019,192.168.3.226:27020") |
在mongos_01添加第二个shard 集群的节点
1 | sh.addShard("rs_shard02/192.168.3.226:27021,192.168.3.226:27022,192.168.3.226:27023") |

在mongos_02节点添加2个shard 集群
mongosh 127.0.0.1:30002连接30002节点
在mongos_02中添加第一个shard 集群的节点
1 | sh.addShard("rs_shard01/192.168.3.226:27018,192.168.3.226:27019,192.168.3.226:27020") |
在mongos_02中添加第二个shard 集群的节点
1 | sh.addShard("rs_shard02/192.168.3.226:27021,192.168.3.226:27022,192.168.3.226:27023") |

查看分片集群状态
sh.status()
也可以使用以下命令,查看特定分片的详细信息:sh.status(shard 集群名字) 如:sh.status('rs_shard01')
使用
1. 启用分片集群
连接到任意一个mongos节点
mongosh 127.0.0.1:30002
开启数据库的分片功能
这里如要开启数据库study的分片功能
use study
sh.enableSharding("study")

2. 指定分片键和分片策略
如下面的命令就是代表students集合按照_id的hash值进行分片,进行hash分片
1 | sh.shardCollection("study.students", {"_id": "hashed" }) |
如果需要使用其他键作为分片键,需要为它创建索引
db.order.createIndex({"id":1})用于范围分片策略db.user.createIndex({id: "hashed"})创建一个哈希索引,用于哈希分片策略
3. 插入多条信息并进行查看
1 | for (i = 1; i <= 1000; i=i+1){ |
db.stats()查看数据库的基本信息
db.students.getShardDistribution()查看分片集合中数据分布情况

期末大作业(主题一)
写在前面
首先需要先了解我的文件路径是如何的,我在C盘根目录创建了一个examTest文件夹,并在其中创建了MySQL和Redis两个文件夹,再MySQL文件夹下创建了data、log、conf文件夹,在Redis文件夹下创建了data、conf文件夹
出现docker端口没有权限等问题,可以先以管理员身份运行命令行窗口,然后输入net stop winnat停止服务,然后再输入net start winnat重启服务即可
MySQL相关
1. 创建MySQL容器
1 | docker run -d --name mysql_3307_exam -v C:/examTest/MySQL/log:/var/log/mysql -v C:/examTest/MySQL/data:/var/lib/mysql -v C:/examTest/MySQL/conf:/etc/mysql/conf.d -p 3307:3306 -e MYSQL_ROOT_PASSWORD=wang10086 -d mysql --init-connect="SET collation_connection=utf8mb4_0900_ai_ci" --init-connect="SET NAMES utf8mb4" --skip-character-set-client-handshake |

mysql -h 127.0.0.1 -P 3307 -u root -p 输入密码就可以进行连接
2. 创建数据库

1 | docker run -id --name mysql_3307_exam -p 3307:3306 mysql |
Redis创建集群
1. 创建容器
配置文件内容如下(IP修改为自己的本机IP):
redis_exam_6380.conf
1 | port 6380 |
redis_exam_6381.conf
1 | port 6381 |
redis_exam_6382.conf
1 | port 6382 |
redis_exam_26380.conf
1 | port 26380 |
redis_exam_26381.conf
1 | port 26381 |
redis_exam_26382.conf
1 | port 26382 |
命令行输入下面命令创建容器,并配置数据卷的位置和配置文件的位置,上面已经给出了每个配置文件的名字和内容,把配置文件放到自己的目录下后按照实际情况修改下面的路径
1 | docker run -d --name redis_exam_6380 -p 6380:6380 -p 16380:16380 --privileged=true -v C:/examTest/Redis/data/6380:/data -v C:/examTest/Redis/conf:/etc/redis redis redis-server /etc/redis/redis_exam_6380.conf |

2. 创建分片集群
根据自己的IP进行修改,这里指定每个主节点的副本数量为1
1 | //1. 进入一个容器,也可以在docker可视化界面进行操作 |

cluster nodes查看节点信息

cluster info查看集群信息

3. 分片集群测试
1 | docker exec -it redis_exam_6380 /bin/bash |


系统功能模块的实现
登录注册
代码
Mapper

Service


Controller

Token


测试
注册
注册成功

数据库中

不允许相同账号

登录
登录成功返回token

再一次登录删除旧token

账号或密码错误,登录失败返回空

用户信息
代码
Mapper

Service

Controller

测试
token错误

token过期

更新成功


反馈
代码
Mapper

Service

Controller

测试
反馈成功

token过期

token错误

获取所有书本信息

获取一本书


书籍信息
代码
Mapper

Service



Controller

测试
不存在的

Redis保存空白值

查询到

阅读信息
代码
Mapper

Service






Controller

测试
阅读人数


下载人数


点赞人数
身份过期

收藏成功



再次请求就是解除收藏


token错误

定时更新浏览数据到数据库