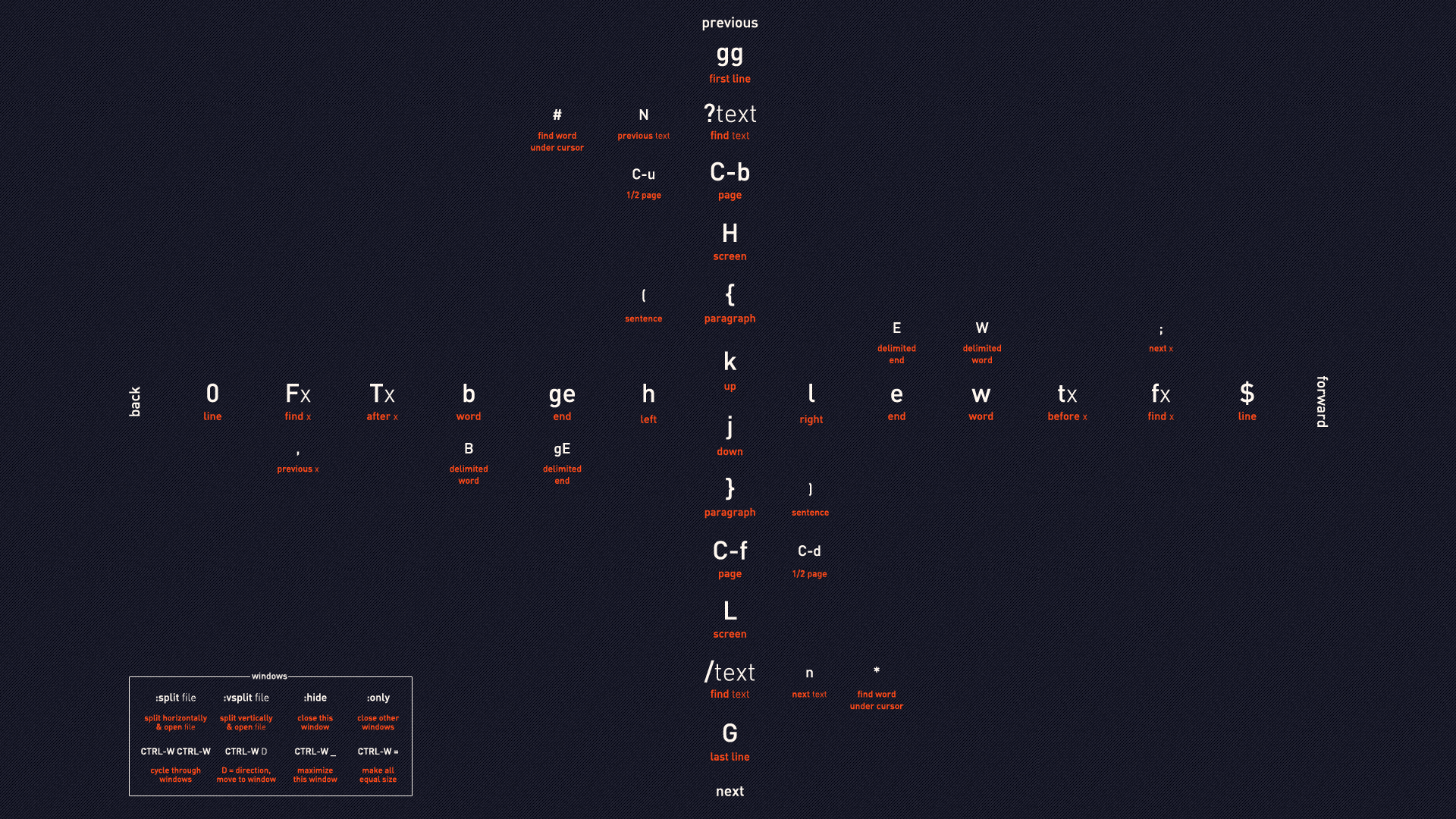
自然语言处理(选修课)
自然语言处理(选修课)
写在前面
个人代码水平并不高,文中代码也是按照老师讲解和个人思路纯手打和debug出来的,许多代码也只是解决了test测试中的问题,需要更高深的代码可以绕道了,文章仅用于记录个人学习经历。
理论部分
简介
NLP分析技术大致分为三个层面:词法分析、句法分析和语义分析。
词法分析
词法分析是为了分析文本中的词汇和标记,主要任务包括分词、词性标注、命名实体识别。
- 分词:将文本分割成单词、标记或短语的过程。分词是NLP任务的基础。
- 词性标注:词性标注是为文本中的每个单词或标记分配一个词性(名词、动词、形容词等)的过程。
- 命名实体识别:命名实体识别是用于识别文本中的命名实体,如人名、地名、组织名、日期等的任务。
句法分析
句法分析涉及理解句子的结构和语法关系,以便对文本进行更深入的分析和理解。两种主流的句法分析方法为短语结构句法体系、依存结构句法体系(后者为当前热点)。
- 依存句法分析:依存句法分析研究词汇之间的依存关系,即一个词与句子中其他词之间的语法依赖关系。这些依赖关系通常表示为有向图中的弧,其中一个词是另一个词的依赖项。依存句法分析有助于理解词与词之间的语法关系,如主谓关系、修饰关系等。
- 短语结构句法分析:短语结构句法分析关注句子中短语的结构,包括短语的组成和嵌套关系。这种分析将句子分解为短语和子句,以揭示句子的语法结构。
语义分析
语义分析涉及理解文本的语义含义和关系,以便深入理解文本内容。
- 词义消歧
- 命名实体链接
- 情感分析
- 语义角色标注
- 语义关系抽取
- 问答系统
- 自然语言生成
- 语义相似度计算
- 知识图谱
数学基础
概率论基础
- 样本空间(Sample Space)
通常把随机试验的每一个可能结果称为一个样本点,样本点的全体称为样本空间用Ω表示
样本空间的子集称为事件,常用A,B,…表示
概率函数是从随机试验中的事件到实数域[0,1]的映射函数,用以表示事件发生的可能性,通常:P(A) 表示事件A的概率函数,概率函数具有以下公理性质:
0≤ P(A) ≤1,对每个属于 Ω 的事件A
P(Ω)=1
A∩B= , P(A ∪ B)=P(A)+P(B)
- 条件概率和独立性(Conditional Probability independence)
两个事件A,B同时发生的概率为事件A,B的交集的概率,P(A∩B)
两个事件A,B独立,则满足:P(A∩B)=P(A)·P(B)
P(A|B) 在已知事件B发生的基础上,判断事件A发生的概率,这个叫条件概率
𝑃(𝐴 ∩ 𝐵) = 𝑃(𝐵)𝑃(𝐴|𝐵) = 𝑃(𝐴)𝑃(𝐵|𝐴)
若事件A1,A2,…,An互相独立,则:
𝑃(𝐴1 ∩ ⋯ ∩ 𝐴𝑛)= 𝑃(𝐴1)𝑃(𝐴2) ⋯ 𝑃(𝐴𝑛)
- 贝叶斯定理 (Bayesan theorem)

贝叶斯定理实际是概率转换公式,求P(A|B)可以转换为计算P(B|A)
信息论
- 熵 (entropy)
熵表示单个随机变量的不确定性的均值,随机变量的熵越大,它的不确定性越大,即能正确估计其值得概率越小

熵的一些属性
H(X)>=0
H(X)=0, 当且仅当随机变量X的值是确定的,没有任何信息量可言
熵值随着信息长度的增加而增加


- 联合熵和条件熵(Joint entropy and conditional entropy)


熵是对不确定性的度量,我们知道的越多,熵越小。
如果一个语言模型可以捕获的语言结构信息越多,那么,熵越小。
因此,我们可以使用熵作为对语言模型的一个度量。
- 互信息 (mutual information)
语言模型
词法分析
相关知识
主要任务
- 分词(Tokenization):将文本拆分成单词或标记。单词是语言中的最小单位,可以是单个词汇或符号。分词是文本处理的基础,它将连续的字符序列切分成离散的单词。
- 去除停用词(Stop Word Removal):停用词是在文本中频繁出现但通常不携带重要信息的词汇,例如“的”、“是”、“在”等。在词法分析中,通常需要去除这些停用词,以减少文本的噪音和提高处理效率。
- 词干提取(Stemming):词干提取是将词语转换为它们的基本形式或词干的过程。例如,将单词的不同时态或复数形式转换为其原始形式,如将“running”转换为“run”。
- 词性标注(Part-of-Speech Tagging):词性标注是为文本中的每个词语分配其词性或语法角色的任务。词性标记可以帮助理解句子的结构和含义。
- 命名实体识别(Named Entity Recognition):命名实体识别是识别文本中特定类型的实体,如人名、地名、组织名等。它有助于从文本中提取重要信息。
- 拼写检查(Spell Checking):拼写检查是检测文本中的拼写错误并提供纠正建议的过程。它可以帮助提高文本质量和可读性。
- 标点符号处理:在词法分析中,通常需要处理文本中的标点符号,包括分句和分段。
- 数字处理:处理文本中的数字,包括数字的规范化、转换和提取。
(这里主要讲了中文相关的分词、词性标注)
语言的分类
传统语言学根据词的形态结构通常把语言分为三大类:
分析型语言( 如:汉语、藏语)
- 词没有专门表示语法意义的附加成分
- 形态变化少
- 语法关系靠词序、虚词来表示
黏着性语言(如:日语、朝鲜语)
- 词前中后有专门表示语法意义的附加成分,一个附加成分表达一种或多种语法意义
- 词根或词干跟附加成分的结合不紧密
屈折型语言(如:英语、德语、法语、西班牙语等)
- 用词的形态变化来表示语法关系,一个形态成分可以表示若干种不同的语法意义
- 词根或词干跟词的附加成分结合得很紧密,往往不容易截然分开
不同的语种本身的结构差异很大,语种之间的语料资源也差异很大,所以,面对不同的语种在自然语言处理方法上会有所差异
分词
相关知识
分词的必要性
分词可以初步帮助我们理解文本的语义信息
分词算法评测标准
通常的评测指标包括:
正确率P
正确率通常指测试结果中正确切分的个数占系统所有输出结果的比例
召回率R
召回率是指测试结果中正确结果的个数占标准答案总数的比例

F度量值
正确率和召回率的综合值


汉语自动分词主要方法
- 基于规则的中文分词方法
- 基于统计的中文分词方法
- 基于神经网络的中文分词方法
基于规则的中文分词方法
基本思路和特点
事先人工建立好分词词典;
基于字符串匹配进行分词,通常需要足够大的词表;
经典算法包括:正向最大匹配法、逆向最大匹配法、双向匹配法等。
优缺点:受限于分词词典的覆盖面。
优缺点
优点:容易实现
缺点:①参数MaxLen不好取:太大,匹配所花时间多,算法时间复杂度提高,太短,不能切分长度超过它的词,导致切分正确率降低。②很多歧义无法处理,例如:幼儿园/地/节目/ 以及 幼儿/园地/节目/ ③最重要一点,准确率不高。
正向最大匹配法
算法描述
输入:分词词典、待切分语料
参数:最大词长maxLen,读取字符串长度len,读取字符串的指针起始位置pos
伪代码:
(1)初始化定义一个maxLen,令len=maxLen,pos=0;
(2)从待切分语料中从字符串下标0的位置开始正向向后取maxLen的字符串str(取不够则全部取完);
(3)将str与词典进行匹配:
①若匹配成功,则认为字符串str为词,pos向后移动len长度,返回步骤(1)
②若匹配失败:如果len>1,则len减1,从待切分语料中从pos往后取长度为len的字符串str,返回步骤(3);否则,得到长度为1的单字词,pos向后移动1长度,返回步骤(1)
代码(个人书写)
1 | # 递归写法 |
1 | # 迭代写法 |
反向最大匹配法
算法描述
输入:分词词典、待切分语料
参数:最大词长maxLen,读取字符串长度len,读取字符串的指针起始位置pos
伪代码:
(4)初始化定义一个maxLen,令len=maxLen,pos=待切分长度-1;
(5)从待切分语料中从字符串最后一个下标的位置开始反向向前取maxLen的字符串str(取不够则全部取完);
(6)将str与词典进行匹配:
①若匹配成功,则认为字符串str为词,pos向前移动len长度,返回步骤(1)
②若匹配失败:如果len>1,则len减1,从待切分语料中从pos往前取长度为len的字符串str,返回步骤(3);否则,得到长度为1的单字词,pos向前移动1长度,返回步骤(1)
代码(个人书写)
1 | # 递归写法 |
1 | # 迭代写法 |
基于统计的中文分词方法
基本思路和特点
利用字与字间、词与词间的同现频率作为分词的依据;
需要大规模的训练文本, 用来训练模型参数;
优点:不受应用领域的限制;
缺点:训练文本的选择影响分词结果。
概率最大分词法(n元语法模型)
概率最大分词法可以通过不同的语法模型完成,这里分别给出不同语法模型的介绍(下面也给出了因为数据缺乏而必需采取平滑算法),同时给出基于二元语法模型的概率最大分词的代码
- 采用一元语法模型(独立性假设)
每个词的出现是独立的,与其他词的出现无关

手算展示例子

- 采用二元语法模型(马尔可夫假设)(代码)
每个词的发生概率取决于前一个词

举例


手算展示例子
对一个待分词的字串S,按照从左到右的顺序取出全部候选词𝑤𝟏, 𝑤2, … , 𝑤𝒏;(这里例子为”结合成分子时“)
序号 候选词 0 结 0 结合 1 合 1 合成 2 成 2 成分 3 分 3 分子 4 子 5 时 计算每个候选词的概率值𝒑 (𝑤𝒊), 记录每个候选词的全部左邻词
(候选词的概率可以从语料库中获得,从左往右寻找到达当前编码的前一个位置的所有词)
(左邻词就是左边相邻的一个词)
序号 候选词 候选词概率 左邻词 0 结 0.0037 / 0 结合 0.0353 / 1 合 0.0049 结 1 合成 0.0006 结 2 成 0.0423 合,结合 2 成分 0.0023 合,结合 3 分 0.0312 合成,成 3 分子 0.0038 合成,成 4 子 0.001 分,成分 5 时 0.1043 子,分子 计算每个候选词的累积概率,并找出每个词的最佳左邻词
(累积概率最大的候选词为最佳左邻词)
| 序号 | 候选词 | 候选词概率 | 左邻词 | 累积概率 | 最佳左邻词 |
|---|---|---|---|---|---|
| 0 | 结 | 0.0037 | / | 0.0037 | / |
| 0 | 结合 | 0.0353 | / | 0.0353 | / |
| 1 | 合 | 0.0049 | 结 | 0.00001813 | 结 |
| 1 | 合成 | 0.0006 | 结 | 0.00000222 | 结 |
| 2 | 成 | 0.0423 | 合,结合 | 0.00149319 | 结合 |
| 2 | 成分 | 0.0023 | 合,结合 | 0.00008119 | 结合 |
| 3 | 分 | 0.0312 | 合成,成 | 0.000046587528 | 成 |
| 3 | 分子 | 0.0038 | 合成,成 | 0.000005674122 | 成 |
| 4 | 子 | 0.001 | 分,成分 | 0.00000008119 | 成分 |
| 5 | 时 | 0.1043 | 子,分子 | 0.0000005918109246 | 分子 |
结:没有左邻词,累积概率为自己的概率0.0037
结合:没有左邻词,累积概率为自己的概率0.0353
合:有一个左邻词是结,概率为0.0049×0.0037=0.00001813
合成:有一个左邻词是结,概率为0.0006×0.0037=0.00000222
成:有两个左邻词,首先看合,概率为0.0423×0.00001813=0.000000766899;再看结合,概率为0.0423×0.0353=0.00149319,选最大累积概率确定最优左邻词为结合
成分:有两个左邻词,首先看合,概率为0.0023×0.00001813=0.000000041699;再看结合,概率为0.0023×0.0353=0.00008119,选最大累积概率确定最优左邻词为结合
分:有两个左邻词,首先看合成,概率为0.0312×0.00000222=0.000000069264;再看成,概率为0.0312×0.00149319=0.000046587528,选最大累积概率确定最优左邻词为成
分子:有两个左邻词,首先看合成,概率为 0.0038×0.00000222=0.000000008436;再看成,概率为 0.0038×0.00149319=0.000005674122,选最大累积概率确定最优左邻词为成
子:有两个左邻词,首先看分,概率为0.001×0.000046587528=0.000000046587528;再看成分,概率为0.001× 0.00008119=0.00000008119,选最大累积概率确定最优左邻词为成分
时:有两个左邻词,首先看子,概率为0.1043×0.00000008119=0.000000008468117;再看分子,概率为0.1043×0.000005674122=0.0000005918109246,选最大累积概率确定最优左邻词为分子
找终点词
这句话最后一个字为时,这里只有一种结果,如果有两种情况,如子时和时出现的时候,就看哪个累积概率大就选哪个
输出分词结果
选时,它的最佳左邻词为分子,选分子,分子最佳左邻词为成,选成,成的最佳左邻词为结合,选结合
最后得出结果为结合/成/分子/时
算法描述
(从上方的手算过程可以看出,这个算法思想是使用动态规划算法来实现,即最优路径中的第i个词wi的累计概率等于它的左相邻词wi-1的累积概率乘以wi自身的概率)
- 对一个待分词的字串S,按照从左到右的顺序取出全部
候选词𝑤𝟏, 𝑤2, … , 𝑤𝒏; - 计算每个候选词的概率值𝒑 𝑤𝒊 记录每个候选词的全部
左邻词; - 计算每个候选词的累计概率,累计概率最大的候选词
为最佳左邻词; - 如果当前词𝑤𝒏是字串的尾词,且累计概率𝒑 𝑤𝒏 最大,
则𝑤𝒏是S的终点词; - 从𝑤𝒏开始,按照从右到左顺序,依次将每个词的最佳
左邻词输出,即S的分词结果.
代码(个人书写)
1 | # 首先要有候选词和候选词的概率字典,这个外部传进来,规定字典样式,字典第一列为正确词语,第二列为概率 |
测试例子
1 | import ProbabilisticMaximumWordSegmentationMethod as Method |
- n元语法模型
每个词的发生概率取决于前n-1个词

事实上绝大多数历史根本不可能在训练数据中出现,为此,可以通过划分等价类的方法降低历史的数目,等价划分降低参数后的语言模型称为n元语法或n元文法**(n-gram)**,通常n不会太大,否则等价类太多,无法具体实现!
数据平滑
平滑技术就是用来解决0概率问题,其基本思想是“劫富济贫”,提高低概率,降低高概率,尽量使得概率分布趋于均匀!(当分子为0的时候就会出现0概率问题,但这时候整块结果就会为0,影响整体结果)

例子

基于神经网络的中文分词方法
基本思路和特点
参数量大、模型训练时间相对较长等。
词性标注
相关知识
MM(马尔可夫链)
马尔可夫链有显马尔可夫链(VMM)和隐马尔可夫链(HMM)
-
假设某系统有N个有限状态 S={s1,s2,…,sN} ,随着时间的推移,系统将从某一个状态转移到另一个状态。
X={x1,x2,…,xT}是一个取值于有限状态集合S的随机变量序列,随机变量的取值为状态集S的某个状态,假定在时间t的状态记为 xt ,xt∈S,t=1,2,…,T。那么这里X称为一阶马尔可夫链,或称具有马尔可夫性质,则系统在时间t处于状态sj的概率取决于它在时间1,2,3,…,t−1的状态,其概率为
$$
P(xt = sj | x(t-1) = sj,x(t-2) = sk)
$$
即在特定情况下,系统在时间t的状态下只与其在时间t-1的状态相关(二元语法模型),该随机过程称为一阶马尔可夫过程。

注:状态转移矩阵的每一行所有列元素的概率和为1

例2
假设有如下转移矩阵
v n p
v 0.1 0.8 0.1
n 0.8 0.01 0.19
p 0.9 0.05 0.05
那么P(n,v,p,n|M) = P(n) * P(v|n) * P(p|v) * P(n|p) = 1 * 0.8 *0.1 * 0.05 = 0.004

隐马尔可夫模型(Hidden Markov Model,HMM)是一种概率模型,用于解决序列预测问题
在马尔可夫模型中,每个状态代表了一个可观察到的事件。如:天气马尔可夫模型,前提是,第二天是天气是可以观察到的。如果知道某个事件的观察序列,是可以使用一个马尔可夫模型来计算;但是,有时候有些事件是不可以直接观测到的。例如:如果一个盲人,他不能通过观察天气来预测天气,他只能通过摸水藻的干湿程度来间接预测天气。这时,水藻的干湿就是可观察事件,其状态为可观察状态;而天气则是隐状态;

隐含马尔可夫模型被认为是解决大多数自然语言处理问题最快速、有效的方法;
应用:语音识别、NLP中的分词、词性标注、计算机视觉中的动作识别等;成功解决了复杂的语音识别、机器翻译等问题;


- 评估问题。
给定观测序列 O=O1O2O3…Ot和模型参数λ=(A,B,π),怎样有效计算某一观测序列的概率,进而可对该HMM做出相关评估。例如,已有一些模型参数各异的HMM,给定观测序列O=O1O2O3…Ot,我们想知道哪个HMM模型最可能生成该观测序列。通常我们利用forward算法分别计算每个HMM产生给定观测序列O的概率,然后从中选出最优的HMM模型。
这类评估的问题的一个经典例子是语音识别。在描述语言识别的隐马尔科夫模型中,每个单词生成一个对应的HMM,每个观测序列由一个单词的语音构成,单词的识别是通过评估进而选出最有可能产生观测序列所代表的读音的HMM而实现的。
2.解码问题
给定观测序列 O=O1O2O3…Ot 和模型参数λ=(A,B,π),怎样寻找某种意义上最优的隐状态序列。在这类问题中,我们感兴趣的是马尔科夫模型中隐含状态,这些状态不能直接观测但却更具有价值,通常利用Viterbi算法来寻找。
这类问题的一个实际例子是中文分词,即把一个句子如何划分其构成才合适。例如,句子“发展中国家”是划分成“发展-中-国家”,还是“发展-中国-家”。这个问题可以用隐马尔科夫模型来解决。句子的分词方法可以看成是隐含状态,而句子则可以看成是给定的可观测状态,从而通过建HMM来寻找出最可能正确的分词方法。
- 学习问题。
即HMM的模型参数λ=(A,B,π)未知,如何调整这些参数以使观测序列O=O1O2O3…Ot的概率尽可能的大。通常使用Baum-Welch算法以及Reversed Viterbi算法解决。
怎样调整模型参数λ=(A,B,π),使观测序列 O=O1O2O3…Ot的概率最大?
针对以下三个问题,人们提出了相应的算法
- 评估问题: 直接计算法(概念上可行,计算上不科学)、前向算法、后向算法
当然也存在穷举搜索算法(就是列举出所有可能性,就是把所有组合路径找出来,计算每条路径的概率,当序列词数比较多的时候就会耗费很多时间,为了避免耗费过多时间就会使用前向算法)
- 解码问题:
Viterbi算法:使用动态规划求解概率最大(最优)路径。
近似算法:选择每一时刻最有可能出现的状态,从而得到一个状态序列。
- 学习问题: Baum-Welch算法(向前向后算法)、监督学习算法
词性标注相关概念
词性标注的定义
即判定给定句子中每个词的语法范畴,确定其词性并加以标注的过程。
如果词w存在两个或两个以上的词性,则词w具有词性标注歧义。
词性标注的必要性
汉语由于缺乏语法形态变化,词的应用非常灵活,词类兼类现象特别多,也特别复杂,因此需要做词性标注。
自然语言中普遍存在词类兼类现象(一个词可做多个词性的现象),正因为存在词类兼类的问题,所以在对词切分时必然要注明词的词性,于是就出现了词性标注
例:他是总编辑(名词) 他正在编辑这本书(动词)
应用
词性标注是一个比较活跃的研究领域,应用广泛,如:口语识别与生成、机器翻译、信息检索和词典编撰等
词性标准的研究方法
- 基于规则方法进行标注
- 统计方法进行标注
- 规则与统计方法结合进行标注
- 基于转换的错误驱动学习
基于规则的词性标注
原理
利用事先制定好的规则对具有多个词性的词进行消歧,最后保留一个正确的词性。
步骤
- 对词性歧义建立单独的标注规则库;
- 标注时,查词典,如果某个词具有多个词性,则查找规则库,对具有相同模式的歧义进行排歧,否则保留。
- 程序和规则库是独立的两个部分。
举例
一把青菜(量词)
我把书放在冰箱上(动词)
要求:要对这两句话进行切分并标注词性。
实现步骤:
已建词典中有: 把 v,l
已建规则库中有:
规则1:如果当前词的前相邻词的词性为s,则该词的词性为l ,如果当前词的前相邻词的词性为n,则该词的词性为v
算法:
用MM方法来切分句子,边切边标注词性。
词性标注时,当切分到‘把’时,有两个词性,怎么办?
到规则库中去寻找相同模式的规则,如这里的规则1恰好满足,所以这里的“把”取q词性。
基于统计的词性标注
基本思路
初始:令W=w1w2…wn是由n个词组成的词串,T=t1t2…tn是词串W对应的词性标注串,其中tk是wk的词性标注;
目标:计算使得条件概率 P(T|W)值最大的词性标注序列T’
思路:
根据贝叶斯公式:P(T|W)= P(T) P(W|T)/ P(W)
.由于词串不变,p(W)不影响总的概率值,因此继续简化为:P(T|W)= P(T) P(W|T)
其中P(T)= P(t1|t0) P(t2|t1,t0)… P(ti|ti-1..)
根据2元语法模型,可得:**P(T)= P(t1|t0) P(t2|t1)… P(ti|ti-1) **
P(ti|ti-1)=训练语料中ti出现在ti-1之后的次数 / 训练语料中ti-1出现的总次数
- 根据乘法公式:P(W|T)= P(w1|t1) P(w2|t2,t1)… P(wi|ti,ti-1…,t1)
- 上式使用1元语法模型:P(W|T)= P(w1|t1) P(w2|t2)… P(wi|ti)
P(wi|ti)=训练语料中wi的词性被标记为ti的次数 / 训练语料中ti出现的总次数
CLAWS算法


VOLSUNGA算法
对CLAWS算法进行改进后得到
CLAWS算法中最佳路径的定义为N个可能的排列中概率乘积最大的那条路径
VOLSUNGA算法从左往右,对于当前考虑的词,只保留通往该词的每个词类的最佳路径,然后继续将这些路径与下个词的所有词类标记进行匹配,分别找出通往这个词的每个标记的最佳路径,后面的词依次重复
下面是跟马尔可夫链相关的算法
前向算法
解决问题
给定一个隐马尔科夫模型M=(A,B),以及一个观测序列O,计算P(O|M) (A表示转移概率,B表示发射概率)例如,给定一个天气的HMM模型,计算某个观测序列{dry,damp,soggy}的概率?即: P(dry,damp,soggy|A,B)
描述

个人理解:前向算法是为了评估HMM模型的,返回一个概率以评估HMM模型,以找到最好的HMM模型,对于概率矩阵,第一列跟维特比算法一样,初始概率 * 发射概率,从第二列开始跟维特比算法有区别,对于每列,列中每个元素等于前一列每个元素 * 转移概率求和,然后再 * 发射概率,最后返回最后一列的所有概率的和。
HMM+Viterbi

这样每个节点保存的是到当前节点的局部最优概率;依据最后一个时刻中概率最高的状态,逆向找其路径中的上一个最大部分最优路径,从而找到整个最优路径。
隐马尔可夫模型+维特比算法在词性标注中的应用
(代码)








这里为了代码书写方便,代码中处理的发射矩阵为下图,只需获取对应坐标即得到发射矩阵的值

代码
1 | # 初始化相关 |
1 | # 传入发射矩阵和转移矩阵 |
1 | import InitUtil |
句法分析
相关知识
字符和字符串相关定义(一些概念与后面概念相关)
假定∑是字符的有限集合,它的每一个元素称为字符。由∑中字符相连而成的有限序列称为∑上的字符串。特殊的,不包括任何字符的字符串称为空串,记作ε。包括空串在内的∑上字符串的全体记为∑*
链接和闭包是字符串操作中的两种基本运算
假定∑是字符的有限集合,x,y是∑上的符号串,则把y的各个符号一次写在x符号串之后得到的符号串称为x与y的链接,记作xy。
例如:
$$
∑={a,b,c}, x=abc, y=cba, 那么:xy=abccba
$$
设A,B是字符表∑上符号串的集合,则A和B的乘积定义为:
$$
AB={xy|x∈ A, y∈ B},其中A^0 = {ε}。当n>=1时,A^n=A^{n-1}A=AA^{n-1}
$$
字符串V的闭包定义为:
$$
V^*=V^0 ∪ V^1 ∪ V^2 ∪ …,
V^+ = V^1 ∪ V^2 ∪ …, V^+ = V^* - {ε}
$$
例如:
$$
如果V={a,b} ,则:V^*={ε, a, b, aa, ab, bb, ba, aaa, …},V^+={a, b, aa, ab, bb, ba, aaa, …}
$$
形式语言(形式语法和自动机)
形式语言学(Formal Linguistics)(也称代数语言学),是一门研究语言的科学领域,它主要关注语言的结构、语法、语义、音系和语音等方面的形式性质。形式语言学使用数学符号和形式规则来描述和分析语言,旨在深入理解语言的本质和结构,以及解决语言相关的理论和应用问题。形式语法理论和自动机理论都属于形式语言理论的一部分。形式语言理论是自然语言描述和分析的基础(目的是试图用精确的数学模型(形式语言)来刻划自然语言),自动机理论在自然语言的词法分析、拼写检查、短语识别等很多方面都有广泛用途。
描述语言的三种途径
枚举法
把语言中的句子穷尽地枚举出来,对于含无限多个句子的语言不合适
文法(语法)描述
给出生成语言中所有句子的方法(文法),而且只生成合格的句子,形式文法是一种语言的文法是一种格式,说明什么句子在该语言中是合法的,并指明把词组合成短语和子句的规则。
自动机
对输入的语符序列进行检验,区别哪些是语言中的句子,哪些不是语言中的句子
文法用来生成语言的句子,属于形式语法理论;自动机用来识别语言的句子,属于自动机理论
- 形式语法特点
高度形式化和抽象化,是一套演绎系统。(从S出发,依靠有限数量的规则,在有限数量的词汇
的基础上,可以产生出无限数量的丰富多彩的句子或终端符序列。)
形式语法的类型(四种文法之间的关系是逐级包含关系,0型包含1型,1型包含2型,2型包含3型)
3型文法–正则文法
特点:与2型文法相比,多出的限制是规则右侧最多只能有一个非终端语符紧跟在终端语符的后面
$$
形式语法G=<V_N,V_T,P,S>
\ S:表示起始符, S∈V_N;V_N:非终端语符集;V_T:终端语符集,;P表示重写规则集,V=V_N∪V_T.
\ \ 如果文法G的规则集P中所有规则满足如下形式,则称该文法G为3型文法,形式如下:
\ A →Bx, 其中:A,B∈V_N;\ x ∈ V_T
$$
$$
例子:
\ G2=<V_N,V_T,P,S>,其中 V_N={S,A,B,C}, V_T={a,b,c}
\ P由下列规则组成:
S→ABC;\ A→aA;\ A→a;\ B→Bb;\ B→b
$$2型文法–上下文无关文法
特点:与1型文法相比,多出的限制是α和β必须是“空”的(因为规则的左边必须是非终结符),即非终结语符的改写不受它出现的语境制约。
$$
形式语法G=<V_N,V_T,P,S>
\ S:表示起始符, S∈V_N;V_N:非终端语符集;V_T:终端语符集,;P表示重写规则集,V=V_N∪V_T. \ \
如果P每个产生式可以描述为A→α,其中A是非终结符,α是空或多个终结符和非终结符的序列
\ \ 字符串中A被改写时,不需要上下文语境,体现
了上下文无关的含义(物理意义的理解)
$$
$$
例子:
\ G1=<V_N,V_T,P,S>
\ 其中 V_N={S,A,B,C}, V_T={a,b,c}
\ P由下列规则组成:S→ABC;\ A→aA;\ A→a;\ B→Bb;\ B→b
$$1型文法–上下文相关文法
特点:与0型文法相比,每条规则箭头的左侧只能有一个非终端语符被改写,而且它的改写与上下文有关.
$$
形式语法G=<V_N,V_T,P,S>
\ S:表示起始符, S∈V_N;V_N:非终端语符集;V_T:终端语符集,;P表示重写规则集,V=V_N∪V_T. \ \
如果文法中的所有规则满足如下形式,则称该文法G为1型文法,形式如下: \
αAβ →αγβ,其中:
A ∈V_N;\ α,β ∈ V^*(即V中零个或多个符号序列);\ 且γ至少包含一个字符
\ \ 字符串中A被改写时,需要上文语境α和下文语境β,体现了上下文相关的含义(物理意义的理解)
$$
$$
例子:
\ G1=<V_N,V_T,P,S>
\ 其中 V_N={S,A,B,C}, V_T={a,b,c}
\ P由下列规则组成:
S→ABC;\ A→a A | a;\ B→b B|b;\ BC→Bcc
\ 该文法所识别的语言为:
L(G)={a^nb^mc^2}, n>=1, m>=1
$$0型文法–无约束文法
特点:规则部分不加任何限制,可以生成任意句子
$$
形式语法G=<V_N,V_T,P,S> \
S:表示起始符, S∈V_N;V_N:非终端语符集;V_T:终端语符集,;P表示重写规则集,V=V_N∪V_T. \ \
如果文法中的所有规则满足如下形式,则称该文法G为0型文法,形式如下: \
α → β,其中: \
α ∈ V^+(V的正闭包,即V中一个或多个符号序列),\β∈V^*(V的自反闭包,即V中零个或多个符号序列)
$$
$$
例子(该文法将产生所有非负整数): \
G=<V_N,V_T,P,S>,其中 V_N={S,D}, V_T={0,1,2,3,…,9} \
P={S→D|SD;\ D→0|1|2|3|4|5|6|7|8|9}
\ 解析:S→D; S→SD→DD; S→SD→SDD→DDD…
$$
总结
从描述能力上说,上下文无关语法不足以描述自然语言,自然语言中上下文相关的情况非常常见; 从计算复杂度来说,上下文无关语法的复杂度是多项式的,其复杂度可以忍受。为弥补上下文无关语法描述能力的不足,需要加上一些其他手段扩充其描述能力。(这里主要涉及2型文法)3型文法生成句子是严格顺着一个方向扩展。
句法分析相关概念
**句法分析(syntatic parsing)**:自然语言处理中的关键技术之一,其基本任务是确定句子的句法结构或句子中词汇之间的依存关系。
句法分析器(Syntactic Parser):是自然语言处理(NLP)中的一个关键组件,用于分析文本的句法结构,即文本中单词和短语之间的语法关系。句法分析器的主要任务是确定文本中的句子是如何构建的,包括词法分析、短语结构分析和句法依存分析。
句法分析分类
句法结构分析(syntatic structure parsing)
- 成分结构分析(constituent structure parsing)
- 短语结构分析(phrase structure parsing)
依存关系分析(dependency parsing)
不同语法形式对应的句法分析不尽相同:基于短语结构语法的句法分析以及基于依存关系语法的依存句法分析
另一种分类
完全句法分析 或 完全短语结构分析:
获取整个句子的句法结构
Full syntactic parsing ;Full phrase structure parsing;Full parsing
浅层句法分析 (partial parsing)
获得局部成分(如名词短语)的句法分析
依存语法:又称从属关系语法,便于计算机对自然语言进行处理
所谓依存是指词与词之间支配与被支配的关系,是一种有方向的不对等关系.处于支配地位的成分成为支配者
(government,head),处于被支配地位的成分成为从属者(modifier,dependency)。在依存结构图中,依存语法的支配者和从属者被描述为head和dependency,支配和被支配的关系用带有方向的边来表示。
基于依存语法的依存句法分析
分析图片来源:语言云(语言技术平台云 LTP-Cloud)

基于短语结构语法的句法分析
短语结构语法,如基于上下文无关语法的短语结构树句法分析。(主要涉及上下文无关语法)

基本策略
一个句法分析可以表述为一个搜索过程,搜索空间是语法规则,搜索过程是检查各种语法规则所有可能的组合方式,目的是最终找到一种组合,其中的语法规则能够生成一棵用来表示句子结构的句法树。
句法分析常用策略有:
- 自顶向下分析法(这里讲解);
- 自底向上分析法;
- 左角分析法;
- 其他策略。
句法分析的过程也可以理解为句法树的构造过程;所谓自顶向下分析法也就是先构造句法树的根结点,再逐步向下扩展,直到叶结点;所谓自底向上分析法也就是先构造句法树的叶结点,再逐步向上合并,直到根结点。
自顶向下算法描述:
1.初始当前状态为((s) 1)记为C,候选状态为空;
2.当算法未失败且算法未成功,则重复:
(1)若C是空字符列且词位置到了句尾,则算法成功,返回。
(2)若当前状态和候选状态都为空,且词未知未到句尾,则算法失败,返回。否则,产生新状态:
• 若C中字符列的第一个字符是句子中下一个词的词类,则从字符列中移去第一个字符,并修改词位置,修改后的状态为当前状态,记为C,转(2)。
• 若C中字符列的第一个字符是非终止符β,用语法中能重写β的每个规则产生新状态,产生的第一个状态为当
前状态(记为C),产生的其它状态加入到候选状态的栈顶,转(2).
• 否则,回溯,从候选状态中取出栈顶作为当前状态。
自顶向下分析算法示例:
| 初始状态 | 候选状态 | comment备注 |
|---|---|---|
| ((S)1) | ||
| ((NP VP)1) | ||
| ((ART N VP)1) | ((ART ADJ N VP)1) | 匹配the,修改初始状态为下一行初始状态 |
| ((N VP)2) | 匹配old | |
| ((VP)3) | ||
| ((V)3) | ((V NP)3) | 匹配man |
| (()4) | 为空但是未到词尾,回溯,从候选状态栈弹出一个状态 | |
| ((V NP)3) | 匹配man | |
| ((NP)4) | 匹配失败,回溯 | |
| ((ART ADJ N VP)1) | 匹配the | |
| ((ADJ N VP)2) | 匹配old | |
| ((N VP)3) | 匹配man | |
| ((VP)4) | ||
| ((V)4) | ((V NP)4) | 匹配cried |
| (()5) | 成功 |
基于规则的句法分析
使用手工定义的语法规则和规则匹配算法来分析句子结构。这需要领域专家手动创建规则,因此适用于特定领域或语言。上面的自顶向上就是一种基于规则的句法分析。
缺点:
计算量大,情况复杂,一些情况下回溯可能很多,不太合理
Top-Down Parsing: 从起始符开始搜索派生空间
Bottom-up Parsing:从终止符开始,反向搜索派生空间
• 属于全搜索,时间复杂度高,不够灵活
基于统计的句法分析
用统计方法和机器学习算法从大量已标注的语料库中学习语法结构。常见的方法包括基于PCFG(Probabilistic Context-Free Grammar)的方法和基于依存关系的方法。
分析:
自顶向下算法最坏情况下需要回溯多次,算法优化方面依然是使用基于使用动态规划思想的句法分析算法,这类算法有CKY、Earley Parser、Chart Parsers,这里主要介绍的是CKY算法。
CKY (Cocke-Kasami-Younger)
基于自底向上的句法分析算法CKY,该算法需要首先规范化语法。
Earley Parser
基于自顶向下的句法分析算法Earley算法,该算法部需要规范化语法。
Chart Parsers
线图算法,它在图表中完整保留短语,并且可以组合自顶向下和自底向上搜索策略。
CKY算法
相关内容:
上下文无关文法(CFG)
乔姆斯基范式(Chomsky normal form,CNF)
在该范式中,产生式只有2个非终端语符或者1个终端语符。
思想:
为了方便实现自底向上的运算,CKY算法首先需要将CFG文法转换为乔布斯基范式
详细思路可以通过下面博客查看,下面记录一下老师上课讲的乔布斯基范式CNF的转换
$$
给定一个句子s = w_1,w_2,…,w_3,和一个上下文无关文法PCFG,G=(T,S,R,P)
\ 定义一个跨越单词i到j的概率最大的语法成分π:π(i,j,X)(i,j∈1…N,X∈N),
\ 目标是找到一个属于π[1,n,s]中所有树中概率最大的那棵。
\ \ CYK算法用于PCFG下的句法分析:
\ ·基本定义:for\ all\ i=1,…,n,X∈N
\ π(i,i,X)=q(X→w_i) (if\ X → w_i 没有出现在语法中,则定义q(X → w_i)=0)
\ ·递归定义:for\ all\ i=1,…,n, j=(i+1),…,n, X ∈N
\ π(i,j,X)=max(q(X→YZ)×π(i,k,Y)×π(k+1,j,Z)) (i≤k≤j−1)
$$
乔布斯基范式CNF的转换:
- 递归删除空
- 递归删除一元
- 对于规则中右边有超过2个非终结符时,则引入新的非终结符来处理
(注意递归的概念)
将NP以空替换其他规则(递归删除空)
注意一次只能改写一个


紫色部分表示用NP->empty将原来的S->NP VP替换成了S->VP
递归处理一元

像这里第一个一元就是
S->VP,第一个要处理的就是这个,可以得到右边紫色的结果,最后所有的结果如下

接着就是处理第二个一元S->V,之后同理一直处理一元


处理完的结果如下:

递归处理三元及以上结果

分析
$$
时间复杂度:
\有 (n(n+1)/2) = O(n^2) 格子
\有 O(n) 个可能的分裂点
\总的时间复杂度为 O(n^3)
\并且可能存在多个句法树的情况,没有局部最优的概念,下面引进的概率就是解决相关问题的
$$
概率CKY统计句法分析算法
相关概念
上下文无关文法CFG
概率上下文无关文法PCFG
理解
无概率的CFG分析符合语法的句子,答案只有两个:是或不是;基于概率上下文无关文法PCFG,则是分析符合语法的句子的可能性,即为一个概率值。
扩展CKY句法分析算法
这个其实就是上面的概率CKY统计句法分析算法在书写代码中的变种,这里主要讲这种。
在这种算法书写思路中一元可以整合进入算法,虽然使得语法有点凌乱,但是并不增加算法的复杂度,空也可以整合进入算法,和一元一样,并不增加算法的复杂度
理解和分析(可以看看其中例题的分析过程)
这份博客的作者应该是广外毕业的,毕竟昵称很直接
个人代码
1 | # 核心类 |
1 | # 测试用例 |
1 | # 允许结果如图 |
这里最终输出的句法树可能有点难理解,这里解释一下,就是层次遍历的去看,第一层节点为S,第二层为NP VP,第三层为NP NP V NP,以此类推,最中每层都跟上层形成二叉树的连接即可,None为空,也就是不存在,后面带括号的,如V(fish)表示V后直接再接一个fish即可
总结
CKY算法在PCFG下的改进算法(PCKY),其优点在于:
存储局部最优语法成分;
搜索空间减少;
获得结果更为准确的句法树。
缺点:依赖于上下文无关文法PCFG,而大规模这样的语法实际是比较难以人工标注的。
最后,基于同一个语句生成的不同句法分析树哪个更符合语言需求就是后面的语义分析
语义分析
应用部分
2023自然语言处理大作业
本文算法
算法概述
中文纠错算法
本系统中使用的中文文本纠错算法会根据输入词语返回词频最高的正确词语,也就是概率最大的可经过编辑操作获取到词语。
本算法结合了编辑距离算法思想,也就是一个拼写错误的字符串可以通过插入、删除、替换、交换转换成另一个可能为拼写正确的字符串;并且定义了一个规则,两个词语的拼音完全一样则优先级最高;两个词语第一个字的拼音完全一样则优先级次之,其余则优先级最低,再根据优先级高低去寻找词典中存在且词频最高的单词返回,这个单词就是返回的拼写正确的词语。
倒排索引搜索
本系统使用的倒排索引搜索算法主要是构建一个按照TF-IDF进行打分的倒排索引文件,而后对于每个搜索的词语在倒排索引文件中进行搜索,找到相关内容出现的page以及按照打分进行排序。
本算法首先会在对内容进行分词后统计词频生成倒排索引文件,而后会对每个词语索引进行TF-IDF打分,生成最终倒排索引文件。
算法各模块描述
中文纠错算法
中文纠错算法本质就是拼写检查,其中最重要的思想就是莱文斯坦距离,又称Levenshtein距离,是编辑距离的一种。指两个字串之间,由一个转成另一个所需的最少编辑操作次数。允许的编辑操作包括将一个字符替换成另一个字符,插入一个字符,删除一个字符。莱文斯坦距离以俄国科学家Vladimir levenshtein命名,他于1965年发明了这个算法。
$$
在数学上,两个字符串a,b的莱文斯坦距离记作lev_{a,b}(|a|,|b|)
$$
$$
lev_{a,b}(i,j)=\begin{cases}
\quad \quad \quad max(i,j)\quad \quad \quad \quad \quad \quad if min(i,j)=0,\
min
\begin{cases}
lev_{a,b}(i-1,j)+1\\
lev_{a,b}(i,j-1)+1\\
lev_{a,b}(i-1,j-1)+1_{(a_i≠b_j)}
\end{cases}
otherwise
\end{cases}
$$
$$
这里,|a|和|b|分别表示字符串a和b的长度,1_{(a_i≠b_j)}是当a_i≠b_j时值为1,否则值为0的示性函数。
\这样,lev_{a,b}(i,j)是a的前i个字符和b的前j个字符之间的距离。
$$
下面是本算法的具体流程:
①第一步:
首先需要读取数据集,第一个读取的数据集是词频词典phrase_freq,该词典中包含了许多的词语以及搜索的频次;第二个读取的数据集是中文字典cn_words_dict,该字典包含所有的中文汉字。
②第二步:
对于需要纠正的单词按照下标按照下标切分成为前后两块,L和R,其实就是分治思想,根据不同长度的词语会有许多组合,保存在splits列表中;
之后遍历删除R的第一个字,也就是删除其中任意一个字的所有组合保存到deletes列表中;
之后将满足长度的R的两个字进行交换,也就是其中两个字进行交换的所有组合保存到transposes列表中;
之后从字典中取一个字替换R中第一个字,也就是取一个字和其中任意一个字进行替换的所有组合保存到replaces列表中;
之后从字典中取出一个字去插入到L和R之间,也就是往词语中插入一个字的所有组合保存到inserts列表中;
最后通过set(deletes+transposes+replaces+inserts)借助Python的特性完成去重,得到所有可能的正确组合。
③第三步:
在得到所有可能的正确组合后,遍历并通过Pinyin库取得所有可能正确组合中的组合的拼音,并按照本系统定义的规则,与拼写错误的词语的拼音进行比较,
如果两者拼音相等则把该预测组合加入到一级数组,
剩余的组合中,如果两者的第一个字的拼音相等则把该预测组合加入到二级数组,
剩余的组合则直接全部加入到三级数组中。
④第四步:
从一级数组到三级数组进行遍历,对于每级数组都从词频词典phrase_freq查找是否存在该词语,遍历完成后保存频次最大且在词频词典中存在的词,这个就是一个拼写错误的词语进行纠正后的词语。
⑤第五步:
对于一个句子输入错误进行纠错,则会使用jieba库进行中文分词,得到分词列表,如果有的分词不能直接通过词频词典phrase_freq查询得到,那么就可以认定为拼写错误,就执行第二步到第四步得到正确拼写的词语。最后没有拼写错误的词语以及纠正错误的词语进行拼接就是正确的句子。
倒排索引搜索
倒排索引
倒排索引(Inverted index) 倒排索引是一种将词项映射到文档的数据结构,这与传统关系型数据库的工作方式不同。可以把倒排索引当做面向词项的而不是面向文档的数据结构。(倒排索引源于实际应用中需要根据属性的值来查找记录。这种索引表中的每一项都包括一个属性值和具有该属性值的各记录的地址。由于不是由记录来确定属性值,而是由属性值来确定记录的位置,因而称为倒排索引(inverted index))
倒排索引:Inverted index,指的是将文档内容中的单词作为索引,将包含该词的文档 ID 作为记录的结构。

TF-IDF
TF-IDF(term frequency–inverse document frequency)是一种用于资讯检索与资讯探勘的常用加权术。TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。TF-IDF加权的各种形式常被搜寻引擎应用,作为文件与用户查询之间相关程度的度量或评级。TF-IDF的主要思想是:如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。TF-IDF实际上是:TF * IDF,TF词频(Term Frequency),IDF反文档频率(Inverse Document Frequency)。TF表示词条在文档d中出现的频率。IDF的主要思想是:如果包含词条t的文档越少,也就是n越小,IDF越大,则说明词条t具有很好的类别区分能力。如果某一类文档C中包含词条t的文档数为m,而其它类包含t的文档总数为k,显然所有包含t的文档数n=m+k,当m大的时候,n也大,按照IDF公式得到的IDF的值会小,就说明该词条t类别区分能力不强。
$$
词频tf_{t,d}表示词t出现在文档d中的次数,则\
w_{t,d}=\begin{cases}
1+log_{10}tf_{t,d}\ ,\quad if\ tf_{t,d}>0\
\quad\quad\quad 0 \ ,\quad\quad\quad otherwise
\end{cases}
$$
$$
文档频率df_t是指包含词t的文档的总数,\
逆文档频率的定义为:\
idf_t = log_{10}(\frac{N}{df_t})
$$
$$
那么一个词t的tf-idf权重值为:\
tf-idf_{t,d}=(1+logtf_{t,d})×log_{10}(\frac{N}{df_t})
$$
下面是本算法的具体流程:
①第一步:
首先定义一个cut_word函数,这个函数对文本做一些处理,用空格替换阿拉伯数字、以及各种符号,然后对处理后的文本调用jieba库进行分词,分词后才能进行相关的处理。
②第二步:
首先从数据库读入全部相关的文件,其中每行数据包含标题title、作者author、文章text、翻译translation,并检查翻译字段是否为空,为空则不进行分词,不为空才进行分词,并且对标题、作者和文章都进行分词处理,并用回车区分不同内容并进行拼接,之后再进行第三步生成倒排索引文件(没有进行TF-IDF打分)。
③第三步:
这一步主要就是生成倒排索引的核心步骤之一。
遍历第二步经过处理的列表,经过分词处理的文本进行切割得到所有出现的词语,借助这些词语借助Counter类统计TF词频,并保存在index字典中,如果字典中的键存在这个词语就说明统计过,则可以直接在原本的值后面拼接出现的文本page和在当前page出现的频率,没有就新加键并保存值,倒排索引生成完成,保存在index字典中。
④第四步:
这一步主要就是使用TF/IDF打分机制进行每个词语的打分,构建最后的倒排索引。
在原本的倒排索引文件的基础上,遍历每个词语,根据键名可以拿到每个词语,而键对应的值就对应每个词语在某篇文章出现的频次tf,可以根据计算得出权重w=1.0 + math.log(tf),而后可以根据值这个列表的长度得到当前词语出现文章的数量df,而所有文章的数量record_count可以直接获取到,那么idf=math.log10(record_count / df),计算完成后保存即可。
到这里为止,TF/IDF进行打分的倒排索引文件就完成了,后续索引文件即可,对于每次查询可以根据倒排索引快速找到按照分值排序的所有的相关古诗内容。
算法细节
数据集
古诗内容相关数据集
其中最重要的数据集就是文章内容相关的数据集了,这份数据集中包含了每首古诗的标题、作者、古诗内容、古诗翻译、作者生活朝代以及更加详细阅读跳转链接。这份数据集是队内组员书写爬虫获取到的数据,进行相关数据处理得到。
下面是存放在数据库中的数据集部分内容:

这份数据集是用来构建倒排索引文件的重要数据集,对于其中的古诗标题、作者、文本和翻译我们会使用结巴中文分词库进行分词处理,而后统计所有词语的频次,并记录每个词语在不同文档出现的频次(这里的文档包括古诗标题、作者、文本和翻译)以及文档的编号,而后会借助统计信息完成TF-IDF打分,并记录打分值,完成倒排索引文件的构建。
下面就是最终生成的倒排索引文件的部分内容:

完成拼写检查中编辑距离处理所需数据集
处理编辑距离是完成拼写检查的重要步骤之一,首先需要中文汉字字典,按照单字进行删除、转换、交换、插入操作错误字符串,得到可能正确字符串,再进行后面的比对。
下面是中文汉字字典的部分(收录了3500个中文汉字):

再得到可能正确字符串后就需要进行比对并且需要一个打分机制,我们的系统自定义了规则进行一个预先的排名,而后再对频次进行比较,这里就需要一个搜索词语频次的数据集,其中记录着可能搜索结果和搜索频次(其中也记录着词性,但这在本系统中并没有运用到)。
下面是词频词典的部分(其中有340000多种搜索的可能以及词频):

中文纠错算法细节
本系统的作文纠错算法中和核心之一就是编辑距离的处理,下面是对一些重要代码的介绍,对于传入的错误拼写词语,会从中文字典中依次去除所有的字,进行删除、调换、转换、插入的操作生成所有的可能正确拼写词语,依次存放在deletes、transposes、replaces、inserts中,之后借助set的特性进行去重。

之后便是对于不同可能正确结果的操作进行一个规则的处理,对于错误拼写词语和可能正确词语的拼音进行对比,两者拼音完全相等就存放在一级列表,只有第一个字的拼音相等就存放在二级列表,其余的存放在三级列表中。

之后便从不同级别的列表依次去寻找,在级别高的列表中找到则返回,对于同一级别的列表就会调用下面的find_max方法进行查找,对比查找词频词典中的词语,找到词频最大的返回,就对拼写错误的词语进行了纠错。

对于需要纠错的句子就只需要调用结巴中文分词库对其进行分词,根据每个词进行处理,若能直接在词频词典中找到则说明没有拼写错误,若查找不到则对每个词调用上面的方法进行纠错,最后局部纠错完成后将所有词语拼接成句子就是对句子的纠错了。