小白个人Android面试准备
准备
整体知识框架

Java知识
Temp
static:是静态的意思;
final:是最后的意思;
区别:
1.final可以修饰类,方法和变量,但是static只能修饰方法和变量;
2.final可以修饰全局变量和局部变量,但是static只能修饰全局变量,不能修饰局部变量;
3.final不可以修饰代码块,但是static可以修饰代码块。
static与final的区别_static和final的区别-CSDN博客
作用域public/private/protected的具体区别_public protected private的作用域-CSDN博客
泛型
Java的泛型符号的名称不要求,个数也不要求,一般有T type,E element,K key,V value,Java的泛型是一个占位符,先给引用类型进行占位,泛型符号可以应用在类的声明处、接口声明、方法的声明
泛型类
ArrayList<E>和HashMap<K,V>就是泛型类
在类中声明了之后就需要在创建类的对象的时候就需要去确定类的声明处定义的泛型的具体类型,如果在构建对象的时候没有去确定类型,那么泛型的类型就是Object类型
1 | //定义泛型类 |
泛型接口
实现类去确定泛型的具体类型,实现类确定了具体类型后在新建实现类的对象的时候就不需要去指定泛型具体的类型了(是否需要去指定类型就看类名后是否存在泛型符号);如果实现类没有指定类型就当做Object来看
1 | public class Test { |
实现类也不确定类型,那么就让实现类也带泛型符号,让创建对象的时候再去确定泛型类型
1 | public class Test { |
ArrayList<E>和HashMap<K,V>都是实现了接口并且实现接口的时候没有直接确定泛型的类型,而直接带上泛型的符号,让用户新建对象的时候再去确定泛型的类型
泛型方法
在方法处可以直接使用泛型的声明符号并且类名处并没有出现泛型符号,并且需要在返回值类型处声明泛型符号,在调用方法处确定泛型类型,当然传参可以使用泛型符号,那么返回值也可以使用泛型符号,静态方法自然也可以使用泛型符号
1 | public class Test { |
public static <T> List<T> asList(T t)就是这种样式,并且返回值也是List类型并且里面为T类型
泛型上下限
这里有一个抽象类是Animal类,里面有一个抽象方法eat,就是相当于动物去吃什么东西,有一个饲养员的类,里面有一个fed方法就是去为动物,传入List<Animal>类型,那么如果一个集合定义为List<Dog>那么就不能传入Cat类型了,并且传入还会报错,那么这种情况饲养员的类里面的方法就不能写死,可以使用**?通配符,就可以传入任何类型的List,但是这时候会将List里面的对象都当成Object类型来看,那么就应该使用public void feed(List<? extends Animal> animals){}表示传入的List类型里面的对象是Animal类的子类或本身,这种是泛型的上限确定了,并且下限不确定,往下可以是Animal子类的子类**
pulic void method(List<? super Animals> animals){}确定下限,需要传的是Animal本身或者父类,这时候就要当做Object来看
javaBean的属性为何用private-set-get而不是直接用public?_java bean属性为什么不用public的-CSDN博客
Java特性
Java基础
JVM和垃圾回收GC
JVM
JVM就是虚拟机,java虚拟机阵营有Sun HotSpot VM、BEA JRockit VM(JDK1.8合并),java虚拟机是采用虚拟化技术,隔离出一块独立的子操作系统,使Java软件不受任何影响在虚拟机内进行执行。
JVM由三个主要的子系统构成:
- 类加载子系统:装载具有适合名称的类或接口
- 运行时数据区(内存结构):包含方法区、Java堆、Java栈、本地方法栈、指令计数器及其他隐含寄存器
- 执行引擎(解释器):负责执行包含在已装载的类或接口中的指令,分配给运行时数据区的字节码将由执行引擎执行。执行引擎读取字节码并逐段执行。当一个方法被调用多次,每次都需要重新解释。
JVM实现了Java的平台无关性
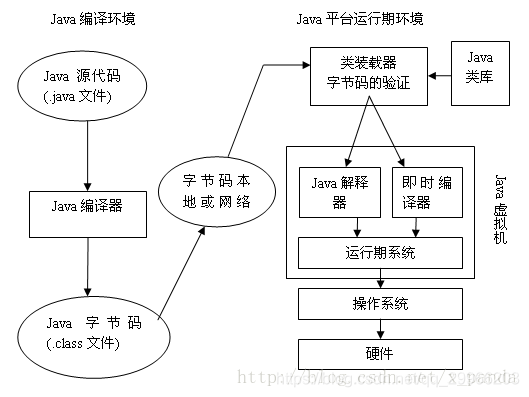
开发人员编写Java代码,并将Java源代码文件(.java文件)通过Java编译器进行编译后形成java字节码文件(.class文件),通过类加载子系统加载到运行时数据区(内存空间),再通过JVM执行引擎进行执行。

Java虚拟机(JVM) 处在核心的位置,是程序与底层操作系统和硬件无关的关键。它的下方是移植接口,移植接口由两部分组成:适配器和Java操作系统, 其中依赖于平台的部分称为适配器;JVM 通过移植接口在具体的平台和操作系统上实现;在JVM 的上方是Java的基本类库和扩展类库以及它们的API, 利用Java API编写的应用程序(application) 和小程序(Java applet) 可以在任何Java平台上运行而无需考虑底层平台, 就是因为有Java虚拟机(JVM)实现了程序与操作系统的分离,从而实现了Java 的平台无关性。
JVM在它的生存周期中有一个明确的任务,那就是运行Java程序,因此当Java程序启动的时候,就产生JVM的一个实例;当程序运行结束的时候,该实例也跟着消失了。
类加载子系统
类的加载
开发者编写Java代码(.java文件),之后编译成字节码(.class文件),类的加载指的是将类的.class文件中的二进制数据读入到内存中,将其放在运行时数据区的方法区内,然后在堆区创建一个java.lang.Class对象,用来封装类在方法区内的数据结构。类的加载的最终产品是位于堆区中的Class对象,Class对象封装了类在方法区内的数据结构,并且向Java程序员提供了访问方法区内的数据结构的接口。
类生命周期
类的生命周期包括加载、连接、初始化、使用和卸载:
- 加载,查找并加载类的二进制数据,在Java堆中也创建一个java.lang.Class类的对象
- 连接,连接又包含三块内容:验证、准备、初始化。1)验证,文件格式、元数据、字节码、符号引用验证;2)准备,为类的静态变量分配内存,并将其初始化为默认值;3)解析,把类中的符号引用转换为直接引用
- 初始化,为类的静态变量赋予正确的初始值
- 使用,new出对象程序中使用
- 卸载,执行垃圾回收
类加载器

类加载机制
全盘负责,当一个类加载器负责加载某个Class时,该Class所依赖的和引用的其他Class也将由该类加载器负责载入,除非显示使用另外一个类加载器来载入
父类委托,先让父类加载器试图加载该类,只有在父类加载器无法加载该类时才尝试从自己的类路径中加载该类
缓存机制,缓存机制将会保证所有加载过的Class都会被缓存,当程序中需要使用某个Class时,类加载器先从缓存区寻找该Class,只有缓存区不存在,系统才会读取该类对应的二进制数据,并将其转换成Class对象,存入缓存区。这就是为什么修改了Class后,必须重启JVM,程序的修改才会生效
JVM内存管理
下面这些都是运行时区内部的区域,前面是类加载器,后面是执行引擎和本地接口
Java堆(Heap)
堆是Java虚拟机所管理的内存中最大的一块。Java堆是被所有线程共享的一块内存区域,在虚拟机启动时创建。此内存区域的唯一目的就是存放对象实例,几乎所有的通过new创建的对象实例都在这里分配内存。当对象无法在该空间申请到内存时抛出OutOfMemoryEroor异常。同时也是垃圾收集器管理的主要区域。
Java的堆内存基于Generation算法(Generational Collector)划分为新生代、年老代和持久代。新生代又被进一步划分为Eden和Survivor区,最后Survivor由FromSpace(Survivor0)和ToSpace(Survivor1)组成。所有通过new创建的对象的内存都在堆中分配,其大小可以通过-Xmx和-Xms来控制。
分代收集,是基于这样一个事实:不同的对象的生命周期是不一样的。因此,可以将不同生命周期的对象分代,不同的代采取不同的回收算法进行垃圾回收(GC),以便提高回收效率。新生代(1/3堆空间)
几乎所有新生成的对象首先都是放在年轻代的。新生代内存按照8:1:1的比例分为一个Eden区和两个Survivor(Survivor0,Survivor1)区。大部分对象在Eden区中生成。当新对象生成,Eden Space申请失败(因为空间不足等),则会发起一次GC(Scavenge GC)。回收时先将Eden区存活对象复制到一个Survivor0区,然后清空Eden区,当这个Survivor0区也存放满了时,则将Eden区和Survivor0区存活对象复制到另一个Survivor1区,然后清空Eden和这个Survivor0区,此时Survivor0区是空的,然后将Survivor0区和Survivor1区交换,即保持Survivor1区为空, 如此往复。当Survivor1区不足以存放 Eden和Survivor0的存活对象时,就将存活对象直接存放到老年代。当对象在Survivor区躲过一次GC的话,其对象年龄便会加1,默认情况下,如果对象年龄达到15岁,就会移动到老年代中。若是老年代也满了就会触发一次Full GC,也就是新生代、老年代都进行回收。新生代大小可以由-Xmn来控制,也可以用-XX:SurvivorRatio来控制Eden和Survivor的比例。
老年代(2/3堆空间)
在年轻代中经历了N次垃圾回收后仍然存活的对象,就会被放到年老代中。因此,可以认为年老代中存放的都是一些生命周期较长的对象。内存比新生代也大很多(大概比例是1:2),当老年代内存满时触发Major GC即Full GC,Full GC发生频率比较低,老年代对象存活时间比较长,存活率标记高。一般来说,大对象会被直接分配到老年代。所谓的大对象是指需要大量连续存储空间的对象。
元数据(直接内存JDK1.8后)
不属于堆内存,属于内存空间。真正与堆隔离。方法区是类逻辑上的一个抽象模板,而元空间是方法区的实现,是真实存在的内存。
MinorGC(新生代的GC),如果OldGeneration满了就会产生FullGC,新生代和老年代都进行GC
方法区(Method Area)
方法区(Method Area)与Java堆一样,是各个线程共享的内存区域,类的所有字段和方法的字节码,以及一些特殊方法如构造函数,接口代码也在此定义。简单说,所有定义的方法的信息都保存在该区域,静态变量+常量+类信息(构造方法/接口定义)+运行时常量池都存在方法区中
程序计数器(Program Counter Register)
程序计数器(Program Counter Register)是一块较小的内存空间,它的作用可以看做是当前线程所执行的字节码的行号指示器。他是线程私有的。可看做一个指针,指向方法区中的方法字节码(用来存储指向下一跳指令的地址,也即将要执行的指令代码),由执行引擎读取下一条指令,是一个非常小的内存空间,几乎可以忽略不计。
每个方法在运行时都存储着一个独立的程序计数器,程序计数器是指定程序运行的行数指针。JVM栈(JVM Stacks)
与程序计数器一样,Java虚拟机栈(Java Virtual Machine Stacks)也是线程私有的,它的生命周期与线程相同。Java栈描述的是Java方法执行的内存模型:一个线程对应一个栈,每个方法被执行的时候都会同时创建一个栈帧(Stack Frame)用于存储局部变量表、操作数栈、动态链接、方法出口等信息。每一个方法被调用直至执行完成的过程,就对应着一个栈帧在虚拟机栈中从入栈到出栈的过程。不存在垃圾回收问题,只要线程已结束栈就出栈,生命周期与线程一致。
本地方法栈(Native Method Stacks)
线程私有,可理解为java中jni调用。用于支持native方法执行,存储了每个native方法调用的状态。本地方法栈(Native Method Stacks)与虚拟机栈所发挥的作用是非常相似的,其区别不过是虚拟机栈为虚拟机执行Java方法(也就是字节码)服务,而本地方法栈则是为虚拟机使用到的Native方法服务。执行引擎通过本地方法接口,利用本地方法库(C语言库)执行。
对象分配规则
对象优先分配在Eden区,如果Eden区没有足够的空间时,虚拟机执行一次Minor GC。
大对象直接进入老年代(大对象是指需要大量连续内存空间的对象)。这样做的目的是避免在Eden区和两个Survivor区之间发生大量的内存拷贝(新生代采用复制算法收集内存)。
长期存活的对象进入老年代。虚拟机为每个对象定义了一个年龄计数器,如果对象经过了1次Minor GC那么对象会进入Survivor区,之后每经过一次Minor GC那么对象的年龄加1,知道达到阀值对象进入老年区。
动态判断对象的年龄。如果Survivor区中相同年龄的所有对象大小的总和大于Survivor空间的一半,年龄大于或等于该年龄的对象可以直接进入老年代。
空间分配担保。每次进行Minor GC时,JVM会计算Survivor区移至老年区的对象的平均大小,如果这个值大于老年区的剩余值大小则进行一次Full GC,如果小于检查HandlePromotionFailure设置,如果true则只进行Monitor GC,如果false则进行Full GC。
Java代码编译和执行过程
这个过程包含了3个重要机制:
Java源码编译机制
- 分析和输入到符号表
- 注解处理
- 语义分析和生成class文件(最终class文件由结构数据,元数据,方法信息组成)
类加载机制
类执行机制
例子:调用java Math.class,即采用执行引擎去执行Java文件。开启一个进程,其中主线程以main方法为入口执行执行Math类文件。线程在运行时,JVM为每一个线程分配一个独立的java栈,java栈里存储着栈帧,每个栈帧存储着每个方法运行时的局部变量、数据。本例Math.java存储着两个栈帧,一个为指向main方法的栈帧,一个为指向math函数的栈帧。
GC算法 垃圾回收
垃圾回收(Garbage Collection)是Java虚拟机(JVM)垃圾回收器提供的一种用于在空闲时间不定时回收无任何对象引用的对象占据的内存空间的一种机制。 注意:垃圾回收回收的是无任何引用的对象占据的内存空间而不是对象本身。换言之,垃圾回收只会负责释放那些对象占有的内存。对象是个抽象的词,包括引用和其占据的内存空间。当对象没有任何引用时其占据的内存空间随即被收回备用,此时对象也就被销毁。但不能说是回收对象,可以理解为一种文字游戏。
引用:如果Reference类型的数据中存储的数值代表的是另外一块内存的起始地址,就称这块内存代表着一个引用。
垃圾:无任何对象引用的对象。
回收:清理“垃圾”占用的内存空间而非对象本身。
发生地点:一般发生在堆内存中,因为大部分的对象都储存在堆内存中。
发生时间:程序空闲时间不定时回收。
对象生命周期
创建阶段
创建阶段会为对象分配存储空间;开始构造对象;从超类到子类对static成员进行初始化;超类成员变量按照顺序初始化,递归调用超类的构造方法;子类成员变量按照顺序初始化,子类构造方法调用
一旦对象被创建并分配给某些对象赋值,这个对象的状态就切换到了应用状态
应用阶段
对象至少被一个强引用持有(强引用在后面享学的四种引用部分有写)
不可见阶段
程序本身不持有该对象任何强引用,虽然引用任然存在,这个阶段的对象可能被JVM等系统下的某些已装载的静态变量或线程或JNI等强引用者持有,这些特殊的强引用称为GC Root,存在着GC Root会导致对象内存泄露,无法被回收
不可达阶段
该对象不再被任何强引用所持有
收集阶段
当垃圾回收器发现该对象已经处于“不可达阶段”并且垃圾回收器已经对该对象的内存空间重新分配做好准备时,则对象进入了“收集阶段”。如果该对象已经重写了finalize()方法,则会去执行该方法的终端操作。(不要重载finalize()方法,这会影响JVM对象分配和回收速度;并且可能造成对象再次复活)
终结阶段
当对象执行完finalize()方法后仍然处于不可达状态时,则该对象进入终结阶段。在该阶段是等待垃圾回收器对该对象空间进行回收
对象空间重新分配阶段
垃圾回收器对该对象的所占用的内存空间进行回收或者再分配了,则该对象彻底消失了,称之为“对象空间重新分配阶段”。
判断对象是否是垃圾的算法
引用计数算法
堆中每个对象(不是引用)都有一个引用计数器。当一个对象被创建并初始化赋值后,该变量计数设置为1。每当有一个地方引用它时,计数器值就加1(a = b, b被引用,则b引用的对象计数+1)。当引用失效时(一个对象的某个引用超过了生命周期(出作用域后)或者被设置为一个新值时),计数器值就减1。任何引用计数为0的对象可以被当作垃圾收集。当一个对象被垃圾收集时,它引用的任何对象计数减1。
根搜索算法
首先了解一个概念:根集(Root Set)
所谓根集(Root Set)就是正在执行的Java程序可以访问的引用变量(注意:不是对象)的集合(包括局部变量、参数、类变量),程序可以使用引用变量访问对象的属性和调用对象的方法。 这种算法的基本思路:
(1)通过一系列名为“GC Roots”的对象作为起始点,寻找对应的引用节点。
(2)找到这些引用节点后,从这些节点开始向下继续寻找它们的引用节点。
(3)重复(2)。
(4)搜索所走过的路径称为引用链,当一个对象到GC Roots没有任何引用链相连时,就证明此对象是不可用的。
Java和C#中都是采用根搜索算法来判定对象是否存活的。
GC算法
标记清除算法
首先标记出所有需要回收的对象,在标记完成后统一回收掉所有被标记的对象。
标记从树根可达的对象,清除(清楚不可达的对象)。标记清除的时候有停止程序运行,如果不停止,此时如果存在新产生的对象,这个对象是树根可达的,但是没有被标记(标记已经完成了),会清除掉。
递归性能低,释放空间不连续容易导致内存碎片,会导致整个程序停止运行。
复制算法
把内存分成两块区域:空闲区域和活动区域,第一还是标记(标记谁是可达的对象),标记之后把可达的对象复制到空闲区,将空闲区变成活动区,同时把以前活动区对象1,4清除掉,变成空闲区。
速度快但耗费空间,假定活动区域全部是活动对象,这个时候进行交换的时候就相当于多占用了一倍空间,但是没啥用。
标记压缩算法
标记过程仍然与“标记-清除”算法一样,但后续步骤不是直接对可回收对象进行清理,而是让所有存活的对象都向一端移动,然后直接清理掉端边界以外的内存
分代收集算法,“分代收集”(Generational Collection)算法,把Java堆分为新生代和老年代,这样就可以根据各个年代的特点采用最适当的收集算法。
JVM采用的垃圾回收分代算法
分代GC在新生代的算法:采用了GC的复制算法,速度快,因为新生代一般是新对象,都是瞬态的用了可能很快被释放的对象。
分代GC在年老代的算法 标记/整理算法,GC后会执行压缩,整理到一个连续的空间,这样就维护着下一次分配对象的指针,下一次对象分配就可以采用碰撞指针技术,将新对象分配在第一个空闲的区域。
垃圾回收器
gc会引起所有代码停止,native代码可以执行,但是不能与jvm交互,执行垃圾收集算法的时候java应用程序除垃圾收集帮助器之外的其他所有线程都会被挂起
串行垃圾回收器
只使用一个单独的线程进行垃圾回收,通过冻结所有应用程序线程进行工作,所以可能不适合服务器环境。它最适合的是简单的命令行程序,是client级别默认的GC方式。
并行垃圾回收器
它是JVM的默认垃圾回收器。与串行垃圾回收器不同,它使用多线程进行垃圾回收。相似的是,当执行垃圾回收的时候它也会冻结所有的应用程序线程。适用于多CPU、对暂停时间要求较短的应用上,是server级别默认采用的GC方式。
并发标记扫描垃圾回收器
并发标记垃圾回收使用多线程扫描堆内存,标记需要清理的实例并且清理被标记过的实例。并发标记垃圾回收器只会在下面两种情况持有应用程序所有线程。相比并行垃圾回收器,并发标记扫描垃圾回收器使用更多的CPU来确保程序的吞吐量。如果我们可以为了更好的程序性能分配更多的CPU,那么并发标记上扫描垃圾回收器是更好的选择相比并发垃圾回收器。
GC分析 命令调优
JVM调优就是使Full GC不执行,使Minor GC尽可能少地执行,因为每一次Full GC都会使JVM停止运行
调优命令
jps,JVM Process Status Tool,显示指定系统内所有的HotSpot虚拟机进程。
jstat,JVM statistics Monitoring是用于监视虚拟机运行时状态信息的命令,它可以显示出虚拟机进程中的类装载、内存、垃圾收集、JIT编译等运行数据。
jmap,JVM Memory Map命令用于生成heap dump文件
jhat,JVM Heap Analysis Tool命令是与jmap搭配使用,用来分析jmap生成的dump,jhat内置了一个微型的HTTP/HTML服务器,生成dump的分析结果后,可以在浏览器中查看
jstack,用于生成java虚拟机当前时刻的线程快照。
jinfo,JVM Configuration info 这个命令作用是实时查看和调整虚拟机运行参数。
调优工具
jconsole,Java Monitoring and Management Console是从java5开始,在JDK中自带的java监控和管理控制台,用于对JVM中内存,线程和类等的监控
jvisualvm,jdk自带全能工具,可以分析内存快照、线程快照;监控内存变化、GC变化等。
MAT,Memory Analyzer Tool,一个基于Eclipse的内存分析工具,是一个快速、功能丰富的Java heap分析工具,它可以帮助我们查找内存泄漏和减少内存消耗
GChisto,一款专业分析gc日志的工具
减少GC开销的措施
- 不要显式调用System.gc():这不一定每次都触发GC,但是会触发也会增加GC的频率
- 减少临时对象的使用
- 对象不用时显式设置为null
- 尽量使用StringBuffer,而不用String来累加字符串:累加字符串会new有个String对象再进行累加操作,增加了许多临时对象
- 能用基本类型就不用引用对象:能用int,long等就不使用Integer和Long对象
- 减少使用静态对象变量:静态对象属于全局变量,不会被GC
- 分散对象创建或删除的时间:集中短时间内大量创建新的对象会导致突然需要大量的内存,JVM面临这种情况的时候就会主动进行GC
Java/Android多线程开发
基础知识
线程和进程的对比
- 概念:①进程是具有一定独立功能的程序关于某个数据集合上的一次运行活动,进程是系统进行资源分配和调度的一个独立单位,是系统进行资源分配的基本单位;②线程是进程的一个实体,是CPU调度和分配的基本单位(最小单位),是比进程更小的能独立运行的基本单位。
- 进程只能在一个时间干一件事,进程执行的过程如果阻塞就会挂起整个进程。
- 进程属于处理器这一层上提供的抽象;线程属于进程这个层面上提供的一层并发的抽象,线程用于提高进程的并发度。
- 一个线程可以创建和撤销另一个线程,同一个进程中的多个县城之间可以并发执行
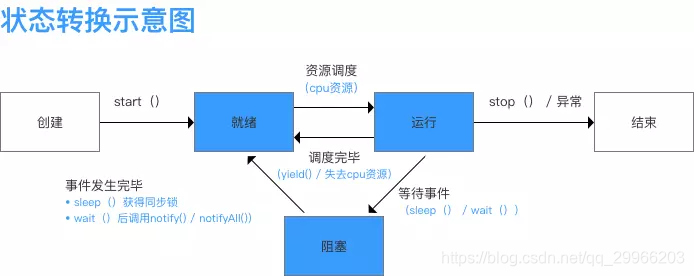
更复杂的
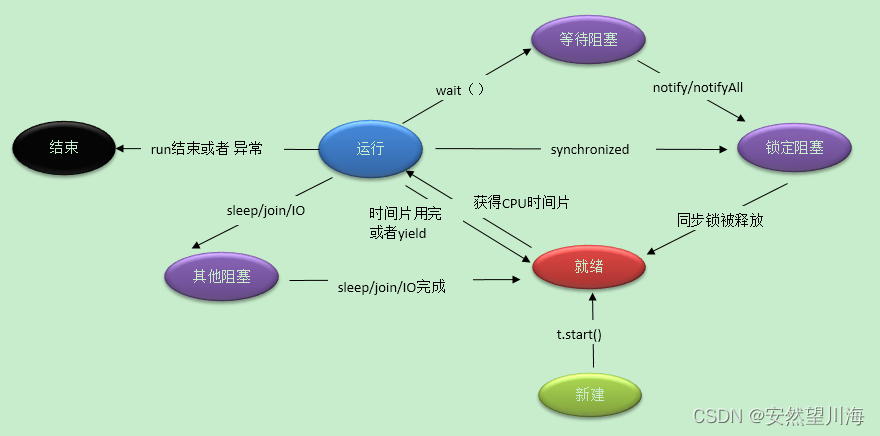
sleep和wait方法的区别
所属类不同:sleep是Thread类的方法;wait是Object类的方法
功能不同:sleep是线程控制自身流程的,调用sleep方法的过程中,线程不会释放锁;wait用于进程间的通信,调用这个方法,线程会放弃对象锁,进入等待此对象的等待锁定池,只有针对对象使用notify方法或者notifyAll后,本线程才会进入对象锁定池,准备获取对象锁进入就绪状态
Java线程状态及 wait、sleep、join、interrupt、yield等的区别 - March On - 博客园 (cnblogs.com)
守护线程
为其他线程提供一种通用服务,如垃圾回收线程
非守护线程
- 主线程(UI线程)
- 子线程(工作线程)
(区别在于虚拟机是否已退出,所有用户线程结束后就没有守护的必要,守护线程就会终止,虚拟机就会同样退出,反之,如果有任意的工作线程还在运行,守护线程就不会终止,虚拟机就不会退出,守护线程不属于不可或缺的存在)
线程优先级可分为10个级别,分别用Thread类常量表示,可通过setPriority(int grade)进行优先级设置,默认线程优先级是5,即 Thread.NORM_PRIORITY
多线程
一个程序(进程)运行时产生多个线程(任务)同时进行。
- 目的:
提高CPU资源的利用率:
避免阻塞(异步调用)
单个线程中的程序是顺序执行的,如果前面的操作发生了阻塞,就会影响到后面的操作
避免CPU空转
如果服务器只用单线程,处理完一条HTTP请求再处理下一条就会使CPU中存在大量空闲时间,处理一条请求还设计很多如数据库访问、磁盘IO等操作,这些操作的速度比CPU慢很多,等待这些响应的时候,CPU不能去处理新的请求,只能处于等待状态,服务器的性能就会很差劲
提升性能
多线程可以同时执行多个任务,对于可并发的任务而言,确实提高了性能
并发和并行
并行:多个cpu实例或者多台机器同时执行一段处理逻辑,是真正的同时。
并发:通过cpu调度算法,让用户看上去同时执行,实际上从cpu操作层面不是真正的同时。其实,多线程本质是并发执行程序。因为计算机任何特定时刻只能执行一个任务;多线程只是一种错觉:只是因为JVM快速调度资源来轮换线程,使得线程不断轮流执行,所以看起来好像在同时执行多个任务而已(异步执行)
线程安全
线程安全是指在并发的情况下,该代码被多个线程使用,但是线程的调度顺序不会影响任何的结果。这个时候使用多线程就只需要关心系统的内存和CPU是否够用即可,反之,线程不安全就会影响最终的结果。
同步和异步
同步:发送一个请求,等待返回再发送下一个请求,同步可以避免出现死锁,读脏数据的发生,可以保证安全性(死锁后面再看)
异步:发送一个请求,不等待返回,随时可以再发送下一个请求,异步可以提高效率,可以并发执行多项工作
Java中的同步指的是通过人为的控制和调度,保证共享资源的多线程访问成为线程安全,来保证结果的准确。如上面的代码简单加入@synchronized关键字
Android多线程编程原则
不能阻塞UI线程:单线程会导致主线程阻塞,出现ANR错误,阻塞超过5s会出现错误
不能在UI线程之外更新UI
解决方案就是1个主线程+n个子线程,耗时任务在子线程完成,更新UI的任务在主线程完成
线程调度
存在大量线程的时候,采用时间片轮转的方式调度线程,线程不可能做到绝对的并发,处于Runnable就绪状态的线程就可以进入线程队列中等待CPU资源,在采用时间片的系统中每个线程都有机会获得CPU的资源进行自身的线程操作,当线程使用CPU资源的时间到后,即使线程没有完成自己的全部操作也会被JVM中断当前线程的执行,把CPU使用权切换给下一个队列等待的线程,之后等待下一次轮回再从中断处继续执行。
线程同步
当线程A使用同步方法A时,其他线程必须等到线程A使用完同步方法A后才能使用,同步方法用Synchronized进行修饰
死锁发生的四个必要条件
互斥:每个资源要么已经分配给了一个进程,要么就是可用的。
占有和等待:已经得到了某个资源的进程可以再请求新的资源。
不可抢占:已经分配给一个进程的资源不能强制性地被抢占,它只能被占有它的进程显式地释放。
环路等待:有两个或者两个以上的进程组成一条环路,该环路中的每个进程都在等待下一个进程所占有的资源。
死锁的处理方法
鸵鸟策略
当发生死锁时不会对用户造成多大影响,或发生死锁的概率很低,可以采用鸵鸟策略(忽略死锁)。
大多数操作系统,包括 Unix,Linux 和 Windows,处理死锁问题的办法仅仅是忽略它。死锁检测与死锁恢复
死锁检测使用资源分配图的方式,从一个节点出发进行深度优先搜索如果最终形成一个环,就是访问到访问过的节点,就说明检测到死锁的发生
利用抢占恢复、回滚恢复、杀死进程恢复
死锁预防
破坏互斥条件:例如假脱机打印机技术允许若干个进程同时输出,唯一真正请求物理打印机的进程是打印机守护进程。
破坏占有和等待条件:一种实现方式是规定所有进程在开始执行前请求所需要的全部资源。
破坏不可抢占条件
破坏环路等待:给资源统一编号,进程只能按编号顺序来请求资源。
死锁避免
安全状态和银行家算法
如果没有死锁发生,并且即使所有进程突然请求对资源的最大需求,也仍然存在某种调度次序能够使得每一个进程运行完毕,则称该状态是安全的。
银行家算法要做的是判断对请求的满足是否会进入不安全状态,如果是,就拒绝请求;否则予以分配。
线程联合
线程A在占有CPU资源期间,通过调用**join()**方法中断自身线程执行,然后运行联合它的线程B,直到线程B执行完毕后线程A再重新排队等待CPU资源,这个过程称为线程A联合线程B
进程
定义
是进程实体的运行过程 & 系统进行资源分配和调度的一个独立单位
作用
使多个程序并发执行,以提高系统的资源利用率和调度的一个独立单位
状态及状态转换


进程和线程区别

多线程
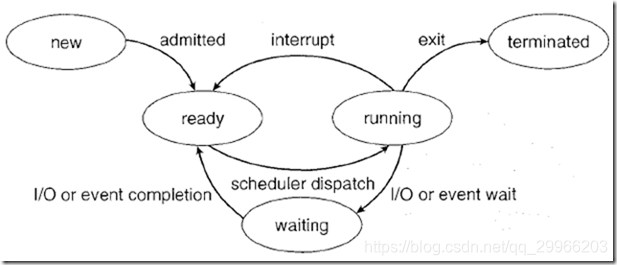
线程状态
分为两部分:
JVM层面
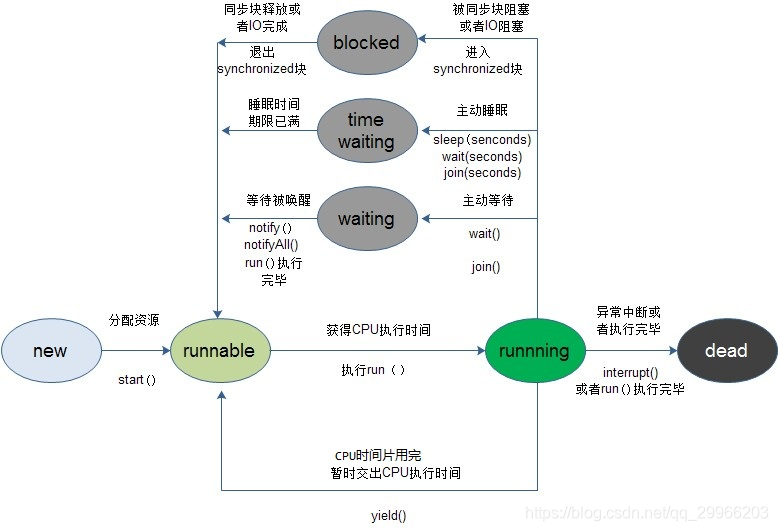
NEW新建状态
当用new操作符创建一个线程后,如Thread thread = new Thread(),此时线程处在新建状态。 当一个线程处于新建状态时,线程中的任务代码还没开始运行。
这里的开始执行具体指调用线程中start方法。(一个线程只能start一次,不能直接调用run方法,只有调用start方法才会开启新的执行线程,接着它会去调用run。在start之后,线程进入RUNNABLE状态,之后还可能会继续转换成其它状态。)RUNNABLE就绪状态(可执行状态)
也被称为“可执行状态”。一个新创建的线程并不自动开始运行,要执行线程,必须调用线程的start()方法。当调用了线程对象的start()方法即启动了线程,此时线程就处于就绪状态。
处于就绪状态的线程并不一定立即运行run()方法,线程还必须同其他就绪线程竞争CPU,只有获得CPU使用权才可以运行线程。比如在单核心CPU的计算机系统中,不可能同时运行多个线程,一个时刻只能有一个线程处于运行状态。对与多个处于就绪状态的线程是由Java运行时系统的线程调度程序(thread scheduler)来调度执行。
除了调用start()方法后让线程变成就绪状态,一个线程阻塞状态结束后也可以变成就绪状态,或者从运行状态变化到就绪状态。
对于Java虚拟机的RUNNABLE状态,包含OS的Ready、Running。(由于现在的时分(time-sharing)多任务(multi-task)操作系统架构通常都是用所谓的“时间分片”方式进行抢占式轮转调度,其中上下文切换过程很快,因此ready与running状态切换很快,对于RUNNABLE状态,就没有切换的意义了。)
以及部分waiting状态(即OS状态下的阻塞式I/O操作),这些状态可统一归纳为RUNNABLE状态的官方定义:
处于 runnable 状态下的线程正在 Java 虚拟机中执行,但它可能正在等待来自于操作系统的其它资源,比如处理器或者其他I/O设备等。(CPU、硬盘、网卡等资源,若在为线程服务,就认为线程在”执行”)BLOCKED阻塞状态
线程在获取锁失败时(因为锁被其它线程抢占),它会被加入锁的同步阻塞队列,然后线程进入阻塞状态(Blocked)。
线程同步机制用于解决多线程之间竞争关系——争夺锁。在ava 在语言级直接提供了同步的机制,也即是 synchronized 关键字,进程同步还需要了解死锁机制,前面有
(BLOCKED状态可以看做特殊的WAITING,表示等待同步锁的状态。)
1
2
3
4
5
6
7
8
9synchronized(expression) {……}
/*
它的机制是这样的:对表达式(expresssion)求值(值的类型须是引用类型(reference type)),获取它所代表的对象,然后尝试获取这个对象的锁:
如果能获取锁,则进入同步块执行,执行完后退出同步块,并归还对象的锁(异常退出也会归还);如果不能获取锁,则阻塞在这里,直到能够获取锁。如果一个线程在同步块中,则其他想进入该同步块的进程被阻塞,处于该同步块的Entry Set中,处于BLOCKED状态。*/
/*
BLOCKED状态官方定义如下:
一个正在阻塞等待一个监视器锁的线程处于这一状态。(A thread that is blocked waiting for a monitor lock is in this state.)
*/进入这个状态包括两种情况:
(1)进入(enter)同步块时阻塞
一个处于 blocked 状态的线程正在等待一个监视器锁以进入一个同步的块或方法。
监视器锁用于同步访问,以达到多线程间的互斥。所以一旦一个线程获取锁进入同步块,在其出来之前,如果其它线程想进入,就会因为获取不到锁而阻塞在同步块之外,这时的状态就是 BLOCKED。
(2)wait 之后重进入(reenter)同步块时阻塞
一个处于 blocked 状态的线程正在等待一个监视器锁,在其调用 Object.wait 方法之后,以再次进入一个同步的块或方法。
过程如下:- 调用 wait 方法必须在同步块中,即是要先获取锁并进入同步块,这是第一次 enter。
- 而调用 wait 之后则会释放该锁,并进入此锁的等待队列(wait set)中。
- 当收到其它线程的 notify 或 notifyAll 通知之后,等待线程并不能立即恢复执行,因为停止的地方是在同步块内,而锁已经释放了,所以它要重新获取锁才能再次进入(reenter)同步块,然后从上次 wait 的地方恢复执行。这是第二次 enter,所以叫 reenter。
- 但锁并不会优先给它,该线程还是要与其它线程去竞争锁,这一过程跟 enter 的过程其实是一样的,因此也可能因为锁已经被其它线程据有而导致 BLOCKED。
这两种情况可总结为:当因为获取不到锁而无法进入同步块时,线程处于 BLOCKED 状态。BLOCKED状态可以看做特殊的WAITING,表示等待同步锁的状态。如果有线程长时间处于 BLOCKED 状态,要考虑是否发生了死锁(deadlock)的状况。
WAITING等待状态
当线程的运行条件不满足时,通过锁的条件等待机制(调用锁对象的wait()或显示锁条件对象的await()方法)让线程进入等待状态(WAITING)。处于等待状态的线程将不会被cpu执行,除非线程的运行条件得到满足后,其可被其他线程唤醒,进入阻塞状态(Blocked)。调用不带超时的Thread.join()方法也会进入等待状态。
一个正在无限期等待另一个线程执行一个特别的动作的线程处于这一状态。
一个线程进入 WAITING 状态是因为调用了以下方法:不带时限的 Object.wait 方法
不带时限的 Thread.join 方法(该线程运行中但还没运行完并且运行过程中需要去运行其他线程再回来就使用这个,也叫线程联合,前面有写;这个方法和yield、sleep都是Thread中的方法,和synchronized 没关系,也不会释放锁)
然后会等其它线程执行一个特别的动作,比如:
- 一个调用了某个对象的 Object.wait 方法的线程会等待另一个线程调用此对象的 Object.notify() 或 Object.notifyAll()。
- 一个调用了 Thread.join 方法的线程会等待指定的线程结束。
进程协作
WAITING状态所涉及的不是一个线程的独角戏,相反,它涉及多个线程,具体地讲,这是多个线程间的一种协作机制。wait/notify与join都是线程间的一种协作机制。下面分别介绍wait/notify场景与join场景
(1)wait/notify场景
当获得锁的线程A进入同步块后发现条件不满足时,应该调用 wait()方法,这时线程A释放锁,并进入所谓的 wait set 中。这时,线程A不再活动,不再参与调度,因此不会浪费 CPU 资源,也不会去竞争锁了,这时的线程A状态即是 WAITING。
现在的问题是:线程A什么时候才能再次活动呢?显然,最佳的时机是当条件满足的时候。
(此时可能存在多个类似线程A这种条件不满足的线程无法执行,与线程B争夺锁资源从而导致饥饿状态)
当另一个线程B执行动作使线程A执行条件满足后,它还要执行一个特别的动作,也即是“通知(notify)”处于WAITING状态的线程A,即是把它从 wait set 中释放出来,重新进入到调度队列(ready queue)中。
如果是 notify,则选取所通知对象的 wait set 中的一个线程释放;
如果是 notifyAll,则释放所通知对象的 wait set 上的全部线程。
但被通知线程A并不能立即恢复执行,因为它当初中断的地方是在同步块内,而此刻它已经不持有锁,所以它需要再次尝试去获取锁(很可能面临其它线程的竞争),成功后才能在当初调用 wait 方法之后的地方恢复执行。(这也即是所谓的 “reenter after calling Object.wait”,即BLOCKED状态。)如果能获取锁,线程A就从 WAITING 状态变成 RUNNABLE 状态;
否则,从 wait set 出来,又进入 entry set,线程A就从 WAITING 状态又变成 BLOCKED 状态。
综上,这是一个协作机制,需要两个具有协作关系的线程A、B分别执行wait和notify。显然,这种协作关系的存在,线程A可以避免在条件不满足时的盲目尝试,也为线程B的顺利执行腾出了资源;同时,在条件满足时,又能及时得到通知。协作关系的存在使得彼此都能受益。
这里的协作机制也即经典的消费者-生产者问题
(2)join场景
从定义中可知,除了 wait/notify 外,调用 join 方法也会让线程处于 WAITING 状态。
join 的机制中并没有显式的 wait/notify 的调用,但可以视作是一种特殊的,隐式的 wait/notify 机制。
假如有 a,b 两个线程,在 a 线程中执行 b.join(),相当于让 a 去等待 b,此时 a 停止执行,等 b 执行完了,系统内部会隐式地通知 a,使 a 解除等待状态,恢复执行。
换言之,a 等待的条件是 “b 执行完毕”,b 完成后,系统会自动通知 a。TIMED_WAITING 限时等待状态
限时等待是WAITING等待状态的一种特例,主要是在时限参数和sleep方法的不同。线程在等待时我们将设定等待超时时间,如超过了我们设定的等待时间,等待线程将自动唤醒进入阻塞状态(Blocked)或就绪状态(Runnable) 。在调用Thread.sleep()方法、带有超时设定的Object.wait()方法、带有超时设定的Thread.join()方法等,线程会进入限时等待状态(TIMED_WAITING)。
一个正在限时等待另一个线程执行一个动作的线程处于这一状态。带指定的等待时间的等待线程所处的状态。一个线程处于这一状态是因为用一个指定的正的等待时间(为参数)调用了以下方法中的其一:
- Thread.sleep
- 带时限(timeout)的 Object.wait
- 带时限(timeout)的 Thread.join
(1)带参数的wait(n)
没有参数的wait()等价于wait(0),表示线程永久等下去,等到天荒地老,除非收到通知。这种完全将再次活动的命运交给通知者可能会导致该线程永远等下去,无法得到执行的机会(当通知者准备执行notify时因某种原因被杀死,持有的锁也释放,此时线程执行的条件满足了,但等待的线程却因收不到通知从而一直处于等待状态)
此时可设置带有参数的wait(1000),等待1秒,相当于等待两个通知,取决于哪个先到:如果在1000毫秒内,线程A收到了线程B的通知而唤醒,则这个闹钟随之失效;
如果超过了1000毫秒还没收到通知,则闹钟将线程A唤醒。
(2)sleep
进入 TIMED_WAITING 状态的另一种常见情形是调用的 sleep 方法,单独的线程也可以调用,不一定非要有协作关系。
这种情况下就是完全靠“自带闹钟”来通知。(sleep方法不会等待协作进程的通知)
sleep方法没有任何同步语义,与锁无关:sleep方法不会等待协作进程的通知,当线程调用sleep方法时带了锁,则sleep期间锁仍为线程所拥有。(3)带参数的join(n)
当前线程等待指定时间,如果等待的线程执行完了就直接继续运行,如果等待指定时间到了但等待执行的线程没有运行完也继续运行(join)
补充:wait 与 sleep 的区别与联系
wait和sleep均能使线程处于等待状态定义
wait方法定义在Object里面,基于对象锁,所有的对象都能使用
(Java里面每一个对象都有隐藏锁,也叫监视器(monitor)。当一个线程进入一个synchronized方法的时候它会获得一个当前对象的锁。)
sleep方法定义在Thread里面,是基于当前线程条件
wait必须在同步环境(synchronized方法)下使用,否则会报IllegalMonitorStateException异常
sleep方法可在任意条件下使用
功能
wait/notify一起使用,用于线程间的通信。wait用于让线程进入等待状态,notify则唤醒正在等待的线程。
sleep用于暂停当前线程的执行,它会在一定时间内释放CPU资源给其他线程执行,超过睡眠时间则会正常唤醒。
锁的持有
在同步环境中调用wait方法会释放当前持有的锁
调用sleep则不会释放锁,一直持有锁(直到睡眠结束)
(补充sleep和join,sleep和join都是Thread的方法,主要区别就是join的内部使用了synchronized和wait,wait会释放锁,但是sleep不会释放锁)
TERMINATED 死亡状态
线程执行完了(completed execution)或者因异常退出了run()方法(exited),该线程结束生命周期。
OS层面线程状态倾向于描述CPU
OS层面状态
JVM层面和OS层面状态对比
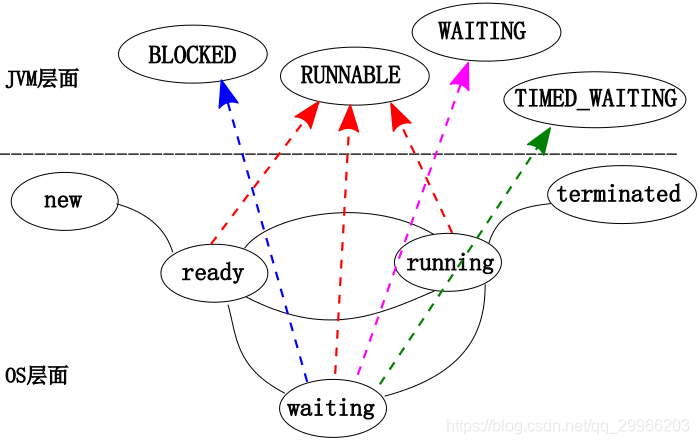
线程阻塞
特点
线程放弃CPU的使用,暂停运行。只有等阻塞原因消除后恢复运行;或是被其他线程中断导致该线程退出阻塞状态,同时跑出InterruptedException.
状态
BLOCKED状态 无法获取同步锁 :synchronic
WAITING状态(TIMED_WAITING状态) 不满足运行条件 :wait/notify、sleep,
RUNNABLE状态 正在JVM中执行,占用某个资源 :阻塞式 I/O 操作原因
(1)Thread.sleep(int millsecond) 调用 sleep 的线程会在一定时间内将 CPU 资源给其他线程执行,超过睡眠事件后唤醒。与是否持有同步锁无关。进程处于 TIMED_WAITING 状态
(2)线程执行一段同步代码(Synchronic)代码,但无法获取同步锁:同步锁用于实现线程同步执行,未获得同步锁而无法进入同步块的线程处于 BLOCKED 状态
(3)线程对象调用 wait 方法,进入同步块的线程发现运行条件不满足,此时会释放锁,并释放CPU,等待其他线程norify。此时线程处于 WAITING 状态
(4)执行阻塞式I/O操作,等待相关I/O设备(如键盘、网卡等),为了节省CPU资源,释放CPU。此时线程处于RUNNABLE状态。机制
(联系消费者和生产者)
Java基础 阻塞队列的方式实现等待唤醒机制,哪里体现了等待?哪里又体现了唤醒? - 嘎嘎鸭2 - 博客园 (cnblogs.com)
线程控制方法
基本线程相关的类(创建线程)
Thread类
1
2
3
4
5
6
7public class Thread implements Runnable{
private char name[];//表示Thread名字,可以通过Thread构造器中的参数指定线程的名字
private int priority;//线程的优先级(最大值为10,最小值为1,默认为5)
// 守护线程和用户线程的区别在于:守护线程依赖于创建它的线程,而用户线程则不依赖。举个简单的例子:如果在main线程中创建了一个守护线程,当main方法运行完毕之后,守护线程也会随着消亡。而用户线程则不会,用户线程会一直运行直到其运行完毕。在JVM中,像垃圾收集器线程就是守护线程。
private boolean daemon = false;//该线程是否为守护线程
private Runnable target;//要执行的任务
}1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31// start() 用来启动一个线程,实现多线程,当调用start方法后,系统会开启一个新线程用来执行用户定义的子任务,并为响应线程分配资源。这时线程处于就绪状态,但并没有运行,一旦得到cpu时间片,就开始执行run方法(run()称为线程体,包含要执行这个线程的内容,run()方法运行结束则线程终止)
public static Thread.start()
// run()方法是不需要用户来调用的,当通过start方法启动一个线程之后,当线程获得了CPU执行时间,便进入run方法体去执行具体的任务。注意,继承Thread类必须重写run方法,在run方法中定义具体要执行的任务。
public static Thread.run()
// 当前线程可转让cpu控制权,让别的就绪状态线程运行(切换)
// 调用yield方法会让当前线程交出CPU权限,让CPU去执行其他的线程。它跟sleep方法类似,同样不会释放锁。但是yield不能控制具体的交出CPU的时间,另外,yield方法只能让拥有相同优先级的线程有获取CPU执行时间的机会。
// 注意,调用yield方法并不会让线程进入阻塞状态,而是让线程重回就绪状态,它只需要等待重新获取CPU执行时间,这一点是和sleep方法不一样的。(和sleep一样,会继续执行原本的任务,而不是从头执行)
public static Thread.yield()
// sleep相当于让线程睡眠,交出CPU,让CPU去执行其他的任务。
// 但是有一点要非常注意,sleep方法不会释放锁(相当于一直持有该对象的锁),也就是说如果当前线程持有对某个对象的锁,则即使调用sleep方法,其他线程也无法访问这个对象。
// 还有一点要注意,如果调用了sleep方法,必须捕获InterruptedException异常或者将该异常向上层抛出。当线程睡眠时间满后,不一定会立即得到执行,因为此时可能CPU正在执行其他的任务。所以说调用sleep方法相当于让线程进入阻塞状态。
sleep(long millis) //参数为毫秒
sleep(long millis,int nanoseconds) //第一参数为毫秒,第二个参数为纳秒
// 在一个线程中调用other.join(),将等待other执行完后才继续本线程。
// 假如在main线程中,调用thread.join方法,则main方法会等待thread线程执行完毕或者等待一定的时间。如果调用的是无参join方法,则等待thread执行完毕,如果调用的是指定了时间参数的join方法,则等待一定的时间。
join()
join(long millis) //参数为毫秒
join(long millis,int nanoseconds) //第一参数为毫秒,第二个参数为纳秒
// interrupt()是Thread类的一个实例方法,用于中断本线程。这个方法被调用时,会立即将线程的中断标志设置为“true”。所以当中断处于“阻塞状态”的线程时,由于处于阻塞状态,中断标记会被设置为“false”,抛出一个 InterruptedException。所以我们在线程的循环外捕获这个异常,就可以退出线程了。
// interrupt()并不会中断处于“运行状态”的线程,它会把线程的“中断标记”设置为true,所以我们可以不断通过isInterrupted()来检测中断标记,从而在调用了interrupt()后终止线程,这也是通常我们对interrupt()的用法。
public interrupte()
一个类去继承Thread的时候必须重写该类的run方法,run方法代表了该线程要完成的任务,run方法可以称为可执行体
线程执行方法与状态的联系
中断机制
Java多线程3种中断方式和终止方式_implements runnable线程结束-CSDN博客
简单来说就是线程有一个标志位,用来标记中断,但实际上并没有中断线程,而是把中断的权利交给线程本身,可以借助下面几个重要方法去实现。interrupt()会让处于睡眠状态的线程抛出InterruptedException异常。
- public void interrupt();//每个线程都有个boolean类型的中断状态。当使用Thread的interrupt()方法时,线程的中断状态会被设置为true。
- public boolean isInterrupted();//判断线程是否被中断
- public static boolean interrupted(); // 清除中断标志,并返回原状态
1 | public class InterruptedExample { |
Runnable接口
1
2
3
4public class Thread implements Runnable {
//其他内容
}
//这是java的Thread类的定义,Runnable是一个接口,里面有run方法,那么就可以知道Thread是Runnable接口的实现类1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28public class RunnableThreadTest implements Runnable
{
private int i;
public void run()
{
for(i = 0;i <100;i++)
{
System.out.println(Thread.currentThread().getName()+" "+i);
}
}
public static void main(String[] args)
{
for(int i = 0;i < 100;i++)
{
System.out.println(Thread.currentThread().getName()+" "+i);
if(i==20)
{
RunnableThreadTest rtt = new RunnableThreadTest();
new Thread(rtt,"新线程1").start();
new Thread(rtt,"新线程2").start();
}
}
}
}Callable接口
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168public interface Callable<V> {
//concurrent包下的接口
V call() throws Exception;
}
public class CallableThreadTest implements Callable<Integer>
{
public static void main(String[] args)
{
// 创建Callable实现体的实例,使用FutureTask类包装Callable对象
CallableThreadTest ctt = new CallableThreadTest();
FutureTask<Integer> ft = new FutureTask<>(ctt);
for(int i = 0;i < 100;i++)
{
System.out.println(Thread.currentThread().getName()+" 的循环变量i的值"+i);
if(i==20)
{
//使用FutureTask对象作为Thread对象的target创建并启动新线程
new Thread(ft,"有返回值的线程").start();
}
}
try
{
//调用FutureTask对象的get()方法来获得子线程执行结束后的返回值
System.out.println("子线程的返回值:"+ft.get());
} catch (InterruptedException e)
{
e.printStackTrace();
} catch (ExecutionException e)
{
e.printStackTrace();
}
}
public Integer call() throws Exception
{
// call 方法即为线程的执行体,并且拥有返回值
int i = 0;
for(;i<100;i++)
{
System.out.println(Thread.currentThread().getName()+" "+i);
}
return i;
}
}
**上面三种创建线程的方式的对比**
线程类继承自Thread就不能再继承其他父类了,但是编写简单,如果要访问当前线程只需要使用this即可
对于Runnable和Callable接口那么父类就还可以继承其他类,但是编程稍微复杂,如果要访问当前线程就需要使用Thread.currentThread()方法。
##### 高级多线程控制类
Java1.5提供了一个非常高效实用的多线程包:java.util.concurrent, 提供了大量高级工具,可以帮助开发者编写高效、易维护、结构清晰的Java多线程程序。
- **ThreadLocal类**
- 实现
每个Thread都持有一个TreadLocalMap类型的变量(该类是一个轻量级的Map,功能与map一样,区别是桶里放的是entry而不是entry的链表。功能还是一个map。)以本身为key,以目标为value。
- 用处
当使用ThreadLocal维护变量时,ThreadLocal为每个使用该变量的线程提供独立的变量副本,副本之间相互独立,所以每一个线程都可以独立地改变自己的副本,而不会影响其它线程所对应的副本。常用于用户登录控制,如记录session信息。
- 常用方法
- ThreadLocal() : 创建一个线程本地变量
- get() : 返回此线程局部变量的当前线程副本中的值
- initialValue() : 返回此线程局部变量的当前线程的"初始值"
- set(T value) : 将此线程局部变量的当前线程副本中的值设置为value
- **原子类**
首先需要先知道CAS机制,看后面享学课堂学习多线程下面有写到CAS机制,这个是用来解决锁机制带来的性能问题的,只是保证简单的对数据的原子性操作直接使用synchronized显得杀鸡用牛刀了,毕竟加锁会带来很大的系统开销,但是使用volatile不能保证原子操作,那么就需要使用CAS机制,而原子变量类就是基于CAS实现的能够保障对共享变量进行read-modify-write更新操作, 例如自增操作“count++”
**原子变量类可以保证原子性和可见性,原子变量类的内部实现通常借助一个 volatile变量保证可见性, 并通过CAS保证原子性**
下面是原子变量类的分类
| 分组 | 类 |
| ---------- | ------------------------------------------------------------ |
| 基础数据型 | AtomicInteger, AtomicLong, AtomicBoolean |
| 数组型 | AtomicIntegerArray , AtomicLongArray, AtomicReferenceArray |
| 字段更新器 | AtomicIntegerFieldUpdater, AtomicLongFieldUpdater, AtomicReferenceFieldUpdater |
| 引用型 | AtomicReference, AtomicStampedReference, AtomicMarkableReference |
- **容器类**
- BlockingQueue
阻塞队列。该类是java.util.concurrent包下的重要类,通过对Queue的学习可以得知,这个queue是单向队列,可以在队列头添加元素和在队尾删除或取出元素。类似于一个管 道,特别适用于先进先出策略的一些应用场景。普通的queue接口主要实现有PriorityQueue(优先队列)。
除了传统的queue功能(表格左边的两列)之外,还提供了阻塞接口put和take,带超时功能的阻塞接口offer和poll。put会在队列满的时候阻塞,直到有空间时被唤醒;take在队 列空的时候阻塞,直到有东西拿的时候才被唤醒。用于生产者-消费者模型尤其好用,堪称神器。
- <a href="#ConcurrentHashMap">ConcurrentHashMap</a>
高效的线程安全哈希map。请对比hashTable , concurrentHashMap, HashMap
- **Semaphore**
信号量,Semaphore有单值和多值两种,前者只能被一个线程获得,后者可以被若干个线程获得,信号量是一个非负整数(表示可以并发访问公共资源的线程数),所有通过它的线程都会将该整数减一(可使用的公共资源数目-1),当该整数值为零时,所有试图通过它的线程都将处于等待状态。在信号量上我们定义两种操作: Wait(等待) 和 Release(释放)。 当一个线程调用Wait(等待)操作时,它要么通过然后将信号量减一(Semaphore>0);要么一直等下去(Semaphore<=0),直到信号量大于0或超时。Release(释放)实际上是在信号量上执行加操作,该操作之所以叫做“释放”是因为加操作实际上是释放了由信号量守护的公共资源。
在java中,还可以设置该信号量是否采用公平模式,如果以公平方式执行,则线程将会按到达的顺序(FIFO)执行,如果是非公平,则可以后请求的有可能排在队列的头部。
单个信号量的Semaphore对象可以实现互斥锁的功能,并且可以是由一个线程获得了“锁”,再由另一个线程释放“锁”,这可应用于死锁恢复的一些场合。
```java
Semaphore(int permits, boolean fair)
//创建具有给定的许可数和给定的公平设置的Semaphore。
public class Test {
public static void main(String[] args) {
//线程池
ExecutorService executor = Executors.newCachedThreadPool();
//定义信号量,只能5个线程同时访问
final Semaphore semaphore = new Semaphore(5);
//模拟20个线程同时访问
for (int i = 0; i < 20; i++) {
final int NO = i;
Runnable runnable = new Runnable() {
public void run() {
try {
//获取许可
semaphore.acquire();
//availablePermits()指的是当前信号灯库中有多少个可以被使用
System.out.println("线程" + Thread.currentThread().getName() +"进入,当前已有" + (5-semaphore.availablePermits()) + "个并发");
System.out.println("index:"+NO);
Thread.sleep(new Random().nextInt(1000)*10);
System.out.println("线程" + Thread.currentThread().getName() + "即将离开");
//访问完后,释放
semaphore.release();
} catch (Exception e) {
e.printStackTrace();
}
}
};
executor.execute(runnable);
}
// 退出线程池
executor.shutdown();
}
}
Java并发模型、线程安全、断点续传
这部分直接看博客对应部分吧,更像一个总结
并发工具
基础类:Synchronized、Volatile、Final
java.util.concurrent包:原子类(atomic)、显示锁(ReentrantLock)、同步模式(CountDownLatch)、线程安全容器(ConcurrentHashMap、CopyOnWriteArrayList、Queue、TransferQueue)
感谢Doug Lea在Java 5中提供了他里程碑式的杰作java.util.concurrent包,它的出现让Java的并发编程有了更多的选择和更好的工作方式。Doug Lea的杰作主要包括以下内容:
更好的线程安全的容器
线程池和相关的工具类
可选的非阻塞解决方案
显示的锁和信号量机制
Synchronized
synchronized 规定了同一个时刻只允许一条线程可以进入临界区(互斥性),同时还保证了共享变量的内存可见性。此规则决定了持有同一个对象锁的多个同步块只能串行执行。
Java中的每个对象都可以为锁。
- 普通同步方法,锁是当前实例对象。
- 静态同步方法,锁是当前类的class对象。
- 同步代码块,锁是括号中的对象。
synchronized 是应用于同步问题的人工线程调度工具。Java中的每个对象都有一个监视器,来监测并发代码的重入。在非多线程编码时该监视器不发挥作用,反之如果在synchronized 范围内(线程进入同步块),监视器发挥作用 ,线程获得内置锁。内置锁是一个互斥锁,以为着最多只有一个线程能够获取该锁。这个锁由JVM自动获取和释放,线程进入synchronized方法时获取该对象的锁,synchronized方法正常返回或者抛异常而终止,JVM会自动释放对象锁。这里也体现了用synchronized来加锁的1个好处,方法抛异常的时候,锁仍然可以由JVM来自动释放。
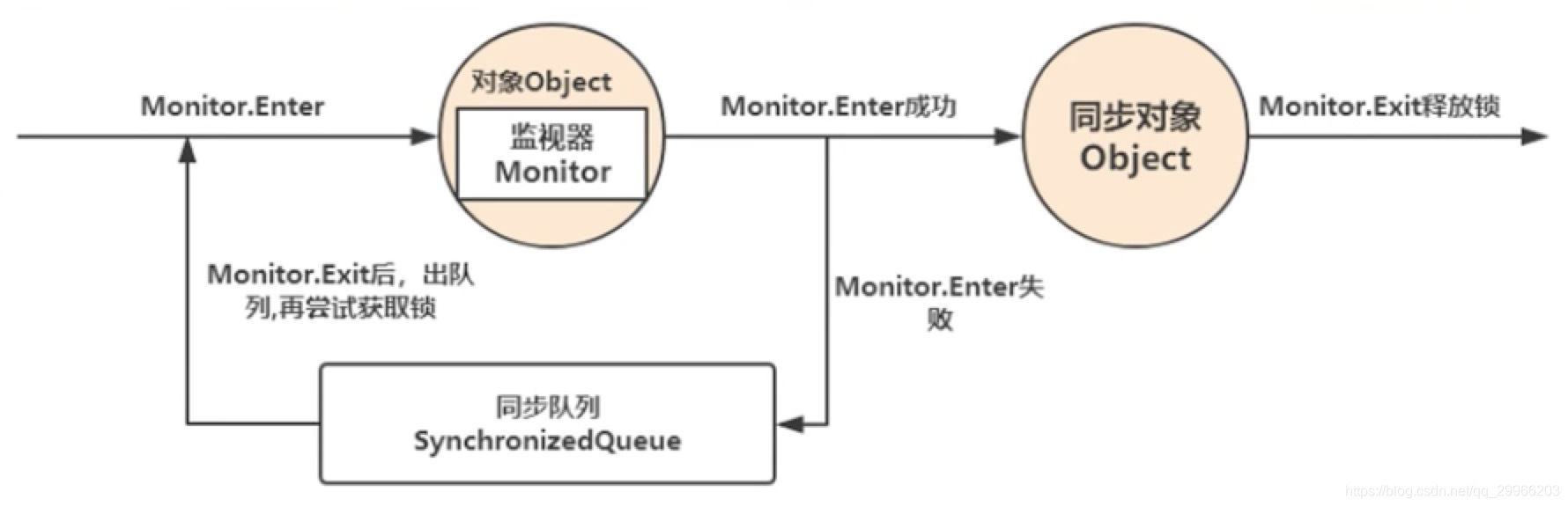
wait/notify必须存在于synchronized块中。并且,这三个关键字针对的是同一个监视器(某个对象的监视器)。
当某个线程wait之后,其他执行该同步快的线程可以进入该同步块执行。
当某个线程并不持有监视器的使用权时(如上图中5的状态,即脱离同步块)去wait或notify,会抛出java.lang.IllegalMonitorStateException。
在synchronized块中去调用另一个对象的wait/notify,因为不同对象的监视器不同,同样会抛出此异常。
synchronized的锁升级可以看后面享学课堂的多线程部分,里面有写到
线程可以通过两种方式锁住一个对象(懵逼):
- 通过膨胀一个处于无锁状态(状态位001)的对象获得该对象的锁;
- 对象处于膨胀状态(状态位00),但LockWord指向的monitor的Owner字段为NULL,则可以直接通过CAS原子指令尝试将Owner设置为自己的标识来获得锁。
获取锁(monitorenter)的大概过程:
对象处于无锁状态时(LockWord的值为hashCode等,状态位为001),线程首先从monitor列表中取得一个空闲的monitor,初始化Nest和Owner值为1和线程标识,一旦monitor准备好,通过CAS替换monitor起始地址到LockWord进行膨胀。如果存在其它线程竞争锁的情况而导致CAS失败,则回到monitorenter重新开始获取锁的过程即可。
对象已经膨胀,monitor中的Owner指向当前线程,这是重入锁的情况(reentrant),将Nest加1,不需要CAS操作,效率高。
对象已经膨胀,monitor中的Owner为NULL,此时多个线程通过CAS指令试图将Owner设置为自己的标识获得锁,竞争失败的线程则进入第4种情况。
对象已经膨胀,同时Owner指向别的线程,在调用操作系统的重量级的互斥锁之前自旋一定的次数,当达到一定的次数如果仍然没有获得锁,则开始准备进入阻塞状态,将rfThis值原子加1,由于在加1的过程中可能被其它线程破坏对象和monitor之间的联系,所以在加1后需要再进行一次比较确保lock word的值没有被改变,当发现被改变后则要重新进行monitorenter过程。同时再一次观察Owner是否为NULL,如果是则调用CAS参与竞争锁,锁竞争失败则进入到阻塞状态。
释放锁(monitorexit)的大概过程:
检查该对象是否处于膨胀状态并且该线程是这个锁的拥有者,如果发现不对则抛出异常。
检查Nest字段是否大于1,如果大于1则简单的将Nest减1并继续拥有锁,如果等于1,则进入到步骤3。
检查rfThis是否大于0,设置Owner为NULL然后唤醒一个正在阻塞或等待的线程再一次试图获取锁,如果等于0则进入到步骤4。
缩小(deflate)一个对象,通过将对象的LockWord置换回原来的HashCode等值来解除和monitor之间的关联来释放锁,同时将monitor放回到线程私有的可用monitor列表。
重入锁和非重入锁
1 | //不可重入锁 |
1 | //可重入锁 |
1 | public class Count{ |
java常用的可重入锁有synchronized和java.util.concurrent.locks.ReentrantLock
注意:
这里要区别,同一个对象的多方法都加入synchronized关键字时,线程A 访问 (synchronized)object.A,线程B 访问 (synchronized)object.B时,必须等线程A访问完A,线程B才能访问B;此结论同样适用于对于object中使用synchronized(this)同步代码块的场景;synchronized锁定的都是当前对象!
lock 机制(单独使用)实现线程竞争
在多线程环境下,synchronized块中的方法获取了lock实例的monitor,如果实例相同,那么只有一个线程(通过竞争获取到lock实例的线程)能执行该块内容。
1 | //通过lock锁定 |
具体使用
synchronized关键字 - - 三种使用方法_synchronized关键字的三种使用方式-CSDN博客
1. 同步方法 synchronized关键字修饰的方法
对象锁
对象锁是用于对象实例方法,或者一个对象实例上的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38public class Main {
/**
* synchronized(对象)
* {
* 临界区
* }
*/
static int count = 0;
static final Object lock = new Object();
public static void main(String[] args) {
new Thread(new Runnable() {
public void run() {
for (int i = 0; i < 10; i++) {
synchronized (lock) {
count++;
System.out.println(count);
}
}
}
}).start();
new Thread(new Runnable() {
public void run() {
for (int i = 0; i < 10; i++) {
synchronized (lock) {
count--;
System.out.println(count);
}
}
}
}).start();
}
//最终结果为0,在线程1执行完后会释放锁让线程2执行
}类锁
类锁是用于类的静态方法或者一个类的class对象上的
其实类锁只是一个概念上的东西,并不是真实存在的,它只是用来帮助我们理解锁定实例方法和静态方法的区别的。我们都知道,java类可能会有很多个对象,但是只有1个Class对象,也就是说类的不同实例之间共享该类的Class对象。Class对象其实也仅仅是1个java对象,只不过有点特殊而已。由于每个java对象都有1个互斥锁,而类的静态方法是需要Class对象。所以所谓的类锁,不过是Class对象的锁而已。获取类的Class对象有好几种,最简单的就是MyClass.class的方式。
1
2
3
4
5
6
7
8
9pulbic class Something(){
public synchronized void isSyncA(){}
public synchronized voidisSyncB(){}
public static synchronizedvoid cSyncA(){}
public static synchronizedvoid cSyncB(){}
}
/*synchronized static是某个类的范围,synchronized static cSync{}防止多个线程同时访问这个类中的synchronized static 方法。它可以对类的所有对象实例起作用。
synchronized 是某实例的范围,synchronized isSync(){}防止多个线程同时访问这个实例中的synchronized 方法。
类锁和对象锁不是同1个东西,一个是类的Class对象的锁,一个是类的实例的锁。也就是说:1个线程访问静态synchronized的时候,允许另一个线程访问对象的实例synchronized方法。反过来也是成立的,因为他们需要的锁是不同的。*/
2. 同步代码块 synchronized关键字修饰的语句块
但用Synchronized修饰同步方法有缺陷:
当某个线程进入同步方法获得对象锁,那么其他线程访问这里对象的同步方法时,必须等待或者阻塞,这对高并发的系统是致命的,这很容易导致系统的崩溃。如果某个线程在同步方法里面发生了死循环,那么它就永远不会释放这个对象锁,那么其他线程就要永远的等待。这是一个致命的问题。
因此用synchronized修饰代码块,缩小同步范围,减少了风险。
因此采用同步代码块,被该关键字修饰的语句块会自动被加上内置锁,从而实现同步。
1 | synchronized(object){ |
1 | public class TestSynchronized |
线程获得对象锁的同时,也可以获得该类锁,即同时获得两个锁,这是允许的
3. wait/notify 机制实现线程协作
wait/notify机制:在Java中,可以通过配合调用Object对象的wait()方法和notify()方法或notifyAll()方法来实现线程间的通信。
由于 wait()、notify/notifyAll() 在synchronized 代码块执行,说明当前线程一定是获取了锁的。
当线程执行wait()方法时候,会将当前进程阻塞,释放当前的锁,然后让出CPU,进入等待状态。(直到接到通知或被中断为止)
只有当 notify/notifyAll() 被执行时候,才会唤醒一个或多个正处于等待状态的线程,从wait()方法中继续往下执行。
要注意
notify唤醒阻塞的线程后,线程会接着上次的执行继续往下执行。
wait/notify必须在同步方法或同步快中调用。wait()方法释放当前线程的锁,因此如果当前线程没有持有适当的锁,则抛出IllegalMonitorStateException异常。notify()方法调用前,线程也必须要获得该对象的对象级别锁,的如果调用notify()时没有持有适当的锁,也会抛出IllegalMonitorStateException。
notify与notifyall区别与联系
notify 与 notifyall 都是用于唤醒被 wait 的线程
notify 调用后,如果有多个线程等待,则线程规划器任意挑选出其中一个wait()状态的线程来发出通知,并使它等待获取该对象的对象锁。但不惊动其他同样在等待被该对象notify的线程们。当第一个获得了该对象锁的wait线程运行完毕以后,它会释放掉该对象锁,此时如果该对象没有再次使用notify语句,则即便该对象已经空闲,其他wait状态等待的线程由于没有得到该对象的通知,会继续阻塞在wait状态,直到这个对象发出一个notify或notifyAll。
notifyAll使所有原来在该对象上wait的线程统统退出wait的状态(即全部被唤醒,不再等待notify或notifyAll,但由于此时还没有获取到该对象锁,因此还不能继续往下执行),变成等待获取该对象上的锁,一旦该对象锁被释放(notifyAll线程退出调用了notifyAll的synchronized代码块的时候),他们就会去竞争。如果其中一个线程获得了该对象锁,它就会继续往下执行,在它退出synchronized代码块,释放锁后,其他的已经被唤醒的线程将会继续竞争获取该锁,一直进行下去,直到所有被唤醒的线程都执行完毕。
notify后,当前线程不会马上释放该对象锁,wait所在的线程并不能马上获取该对象锁,要等到程序退出synchronized代码块后,当前线程才会释放锁,wait所在的线程也才可以通过竞争获取该对象锁
1 | /** |
Volatile
Java多线程内存模式与重排序
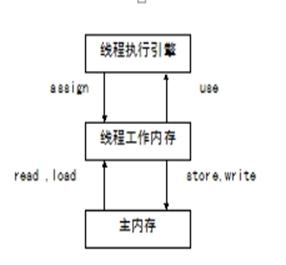
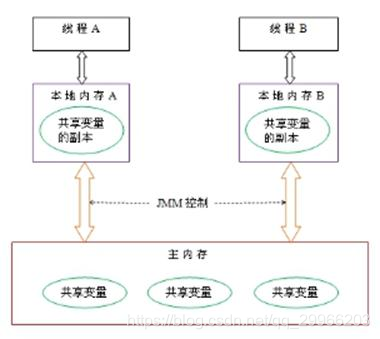
在JAVA多线程环境下,对于每个Java线程除了共享的虚拟机栈外和Java堆之外,还存在一个独立私有的工作内存,工作内存存放主存中变量的值的拷贝。每个线程独立运行,彼此之间都不可见,线程的私有堆内存中保留了一份主内存的拷贝,只有在特定需求的情况下才会与主存做交互(复制/刷新)。
当数据从主内存复制到工作存储时,必须出现两个动作:第一,由主内存执行的读(read)操作;第二,由工作内存执行的相应的load操作;当数据从工作内存拷贝到主内存时,也出现两个操作:第一个,由工作内存执行的存储(store)操作;第二,由主内存执行的相应的写(write)操作
每一个操作都是原子的,即执行期间不会被中断。
对于普通变量,一个线程中更新的值,不能马上反应在其他变量中。
如果需要在其他线程中立即可见,需要使用 volatile 关键字。
正常变量就是下面的流程,volatile的不同,享学课堂多线程那里有图
重排序:
在有些场景下多线程访问程序变量会表现出与程序制定的顺序不一样。因为编译器可以以优化的名义改变每个独立线程的顺序,从而使处理器不按原来的顺序执行线程。一个Java程序在从源代码到最终实际执行的指令序列之间,会经历一系列的重排序过程。
对于多线程共享同一内存区域这一情况,使得每个线程不知道其他线程对数据做了怎样的修改(数据修改位于线程的私有内存中,具有不可见性),从而导致执行结果不正确。因此必须要解决这一同步问题。
原理
volatile二三事2—非原子性_volatile非原子性-CSDN博客
对于非volatile变量进行读写时,每个写成先从主存拷贝变量到线程缓存中,执行完操作再保存到主存中。需要进行load/save操作。
而volatile变量保证每次读写变量都是不经过缓存而是直接从内存读写数据。省去了load/save操作。volatile变量不会将对该变量的操作与其他内存操作一起重排序,能及时更新到主存;且因该变量存储在主存上,所以总会返回最新写入的值。
因此volatile定义的变量具有以下特性:
保证此变量对所有的线程的可见性。
当一个线程修改了这个变量的值,volatile 保证了新值能立即同步到主内存,以及每次使用前立即从主内存更新。因此使用volatile修饰域相当于告诉JVM该域会被其他线程更新,volatile修饰域一旦改变,相当于告诉所有其他线程该域的变化。但非volatile变量的值在线程间传递均需要通过主内存完成,看到的数据可能不是最新的数据。
禁止指令重排序优化。
有volatile修饰的变量,赋值后多执行了一个“load and save”操作,这个操作相当于一个内存屏障(指令重排序时不能把后面的指令重排序到内存屏障之前的位置)
性能较低
volatile 的读性能消耗与普通变量几乎相同,但是写操作稍慢,因为它需要在本地代码中插入许多内存屏障指令来保证处理器不乱序执行。
轻量级sychronized
在访问volatile变量时不会执行加锁操作,因此也就不会使执行线程阻塞,因此volatile变量是一种比sychronized关键字更轻量级的同步机制。
1
2
3
4
5
6
7
8
9
10
11
12class Bank {
//需要同步的变量加上volatile
private volatile int account = 100;
public int getAccount() {
return account;
}
//这里不再需要synchronized
public void save(int money) {
account += money;
}
}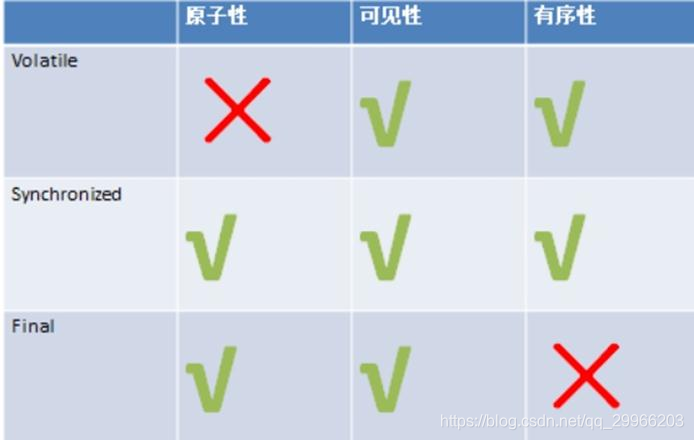
final不可变
作用于类、方法、成员变量、局部变量。初始化完成后的不可变对象,其它线程可见。常量不会改变不会因为其它线程产生影响。Final修饰的引用类型的地址不变,同时需要保证引用类型各个成员和操作的线程安全问题。因为引用类型成员可能是可变的。
synchronized同步
作用域代码块、方法上。通过线程互斥,同一时间的同样操作只允许一个线程操作。通过字节码指令实现。
Volatile 修饰域
volatile 修饰的变量的变化保证对其它线程立即可见。
volatile变量的写,先发生于读。每次使用volatile修饰的变量个线程都会刷新保证变量一致性。但同步之前各线程可能仍有操作。如:各个根据volatile变量初始值分别进行一些列操作,然后再同步写赋值。每个线程的操作有先后,当一个最早的线程给线程赋值时,其它线程同步。但这时其它线程可能根据初始值做了改变,同步的结果导致其它线程工作结果丢失。根据volatile的语意使用条件:运算结果不依赖变量的当前值。
volatile禁止指令重排优化。
这个语意导致写操作会慢一些。因为读操作跟这个没关系。
ReentrantLock
可以看花里花哨后面的补充的五种锁机制以及不同锁的种类(操作系统课程有提到)
- ReentrantLock
- ReentrantReadWriteLock.ReadLock
- ReentrantReadWriteLock.WriteLock
主要目的是和synchronized一样, 两者都是为了解决同步问题,处理资源争端而产生的技术。功能类似但有一些区别。区别如下:
lock更灵活,可以自由定义多把锁的枷锁解锁顺序(synchronized要按照先加的后解顺序)
提供多种加锁方案,lock 阻塞式, trylock 无阻塞式, lockInterruptily 可打断式, 还有trylock的带超时时间版本。
本质上和监视器锁(即synchronized是一样的)
能力越大,责任越大,必须控制好加锁和解锁,否则会导致灾难。
和Condition类的结合。
性能更高
1 | class Bank { |
ReenreantLock & Synchronized 的选择
| 比较类型 | Synchronized | ReenreantLock |
|---|---|---|
| 锁的实现 | JVM | JDK |
| 等待可中断:当持有锁的线程长期不释放锁的时候,正在等待的线程可以选择放弃等待,改为处理其他事情 | 不可中断 | 可中断 |
| 公平锁:公平锁是指多个线程在等待同一个锁时,必须按照申请锁的时间顺序来依次获得锁。 | 非公平 | 公平/非公平(默认) |
除非需要使用 ReentrantLock 的高级功能,否则优先使用 synchronized。这是因为 synchronized 是 JVM 实现的一种锁机制,JVM 原生地支持它,而 ReentrantLock 不是所有的 JDK 版本都支持。并且使用 synchronized 不用担心没有释放锁而导致死锁问题,因为 JVM 会确保锁的释放。
总结:Synchronized & ReentrantLock & Volatile 区别
(1)Synchronized &Volatile 区别
AbstractQueuedSynchronizer通过构造一个基于阻塞的CLH队列容纳所有的阻塞线程,而对该队列的操作均通过Lock-Free(CAS)操作,但对已经获得锁的线程而言,ReentrantLock实现了偏向锁的功能。
synchronized的底层也是一个基于CAS操作的等待队列,但JVM实现的更精细,把等待队列分为ContentionList和EntryList,目的是为了降低线程的出列速度;当然也实现了偏向锁,从数据结构来说二者设计没有本质区别。但synchronized还实现了自旋锁,并针对不同的系统和硬件体系进行了优化,而Lock则完全依靠系统阻塞挂起等待线程。
当然Lock比synchronized更适合在应用层扩展,可以继承AbstractQueuedSynchronizer定义各种实现,比如实现读写锁(ReadWriteLock),公平或不公平锁;同时,Lock对应的Condition也比wait/notify要方便的多、灵活的多。
(2)Synchronized & ReentrantLock 区别
volatile本质是在告诉jvm当前变量在寄存器(工作内存)中的值是不确定的,需要从主存中读取; synchronized则是锁定当前变量,只有当前线程可以访问该变量,其他线程被阻塞住。
volatile仅能使用在变量级别;synchronized则可以使用在变量、方法、和类级别的
volatile仅能实现变量的修改可见性,不能保证原子性;而synchronized则可以保证变量的修改可见性和原子性
volatile不会造成线程的阻塞;synchronized可能会造成线程的阻塞。
volatile标记的变量不会被编译器优化;synchronized标记的变量可以被编译器优化
线程池
简介
Executor接口是Executor框架的一个最基本的接口,Executor框架的大部分类都直接或间接地实现了此接口,具体实现为
ThreadPoolExecutor类。 只有一个方法void execute(Runnable command);,在未来某个时间执行给定的命令。该命令可能在新的线程、已入池的线程或者正调用的线程中执行,这由 Executor 实现决定。使用原因
频繁创建线程和销毁线程,会很大程度上影响处理的效率(创建一个线程,执行完就销毁的时间是大于直接让一个线程直接执行任务的时间的,那么就可以借助线程池去利用闲置的线程去执行新的任务,而避免频繁创建和销毁线程)
线程并发数过多就会导致抢占资源从而导致阻塞
借助线程池可以帮助我们控制最大的线程并发数量,避免因为系统资源不足而产生阻塞的问题。
对线程进行简单的管理
比如延时执行和定时循环执行等策略就可以利用线程池进行良好的实现
线程池的构造

核心线程数量(corePoolSize)
如果新添加任务的时候,当前运行的线程没有达到核心线程数量(corePoolSize),就会创建新的线程来执行添加的任务。并且,当线程当中运行的线程没有达到corePoolSize的时候,即使线程一直空闲着,也不会被销毁。
任务队列(runnableTaskQueue)
运行的线程数量>=核心线程数量,就会把任务添加到这个队列当中。
最大线程数量(maximumPoolSize)
一个线程池当中总的线程数量(maximunPoolSize)为:核心线程数量+空闲线程(可以理解空闲线程为临时工)的数量
最大线程数量可以理解为,此时线程池已经无法再次容纳更多的线程了。如果在工作队列已经满了的情况下面,创建新的线程将使得当前运行的线程超出maximunPoolSize,将触发拒绝策略。反之,如果创建新的线程没有使得当前运行的线程超过maximunPoolSize,那么线程池就会继续创建新的线程来执行任务。
SynchronousQueue
这个队列接收到任务的时候,会直接提交给线程处理,而不保留它,如果所有线程都在工作怎么办?那就新建一个线程来处理这个任务!所以为了保证不出现<线程数达到了maximumPoolSize而不能新建线程>的错误,使用这个类型队列的时候,maximumPoolSize一般指定成Integer.MAX_VALUE,即无限大
LinkedBlockingQueue
这个队列接收到任务的时候,如果当前线程数小于核心线程数,则新建线程(核心线程)处理任务;如果当前线程数等于核心线程数,则进入队列等待。由于这个队列没有最大值限制,即所有超过核心线程数的任务都将被添加到队列中,这也就导致了maximumPoolSize的设定失效,因为总线程数永远不会超过corePoolSize
ArrayBlockingQueue
可以限定队列的长度,接收到任务的时候,如果没有达到corePoolSize的值,则新建线程(核心线程)执行任务,如果达到了,则入队等候,如果队列已满,则新建线程(非核心线程)执行任务,又如果总线程数到了maximumPoolSize,并且队列也满了,则发生错误
DelayQueue
队列内元素必须实现Delayed接口,这就意味着你传进去的任务必须先实现Delayed接口。这个队列接收到任务时,首先先入队,只有达到了指定的延时时间,才会执行任务
keepAliveTime
这个属性生效的时间在于,当运行的线程数量超过corePoolSize,并且当有线程处于空闲状态的时间超过KeepAliveTime之后,将会被销毁。
unit
空闲线程存活时间单位,也就是keepAliveTime的单位
ThreadFactory
线程工厂,线程池创建一个新的线程时候使用的”工厂”,这个涉及到”工厂模式”.
RejectedExceptionHandler(饱和策略,也称为拒绝策略)
当队列和线程池都已经满了,说明线程池处于饱和状态,那么必须采取一系列策略来处理新提交的任务。下面,一共有4种拒绝策略:
- 直接抛出异常(默认)
- 只用调用者所在线程执行任务(不再提交任务,执行者提交任务的线程来执行自己提交的任务)
- 丢弃队列中最近一个任务
- 不处理最新提交的任务
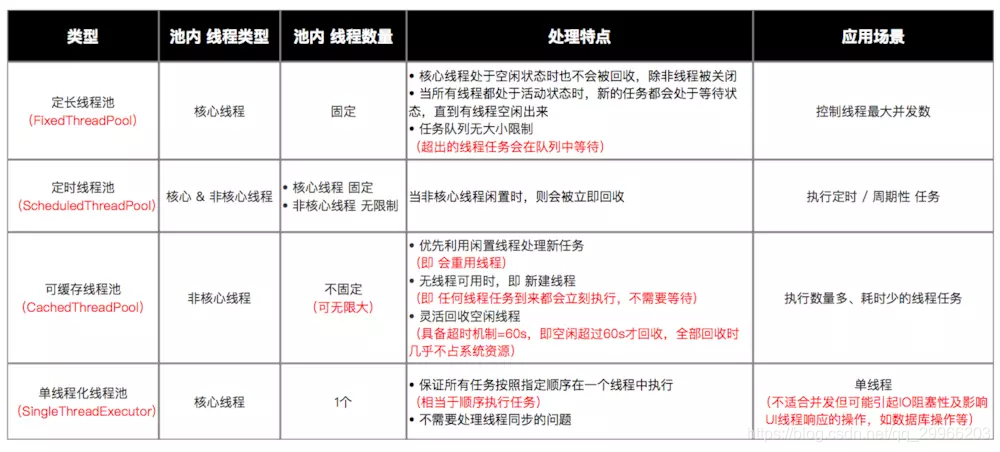
线程池的类型(下面不同类型的线程池都是直接或间接配置ThreadPoolExecutor的参数实现的)
CachedThreadPool() 可缓存线程池
线程数无限制;有空闲线程则复用空闲线程,无则新建线程;一定程度地减少频繁创建和销毁线程,减少系统开销
1
2
3
4
5
6
7
8ExecutorService cachedThreadPool = Executors.newCachedThreadPool();
//源码
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}FixedThreadPool()
可以控制线程最大并发数(同时执行的线程数);超出的线程在队列中等待
1
2
3
4
5
6
7
8
9
10
11
12//nThreads => 最大线程数即maximumPoolSize
ExecutorService fixedThreadPool = Executors.newFixedThreadPool(int nThreads);
//threadFactory => 创建线程的方法,这就是我叫你别理他的那个星期六!你还看!
ExecutorService fixedThreadPool = Executors.newFixedThreadPool(int nThreads, ThreadFactory threadFactory);
//源码
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}ScheduledThreadPool()
支持定时及周期性任务执行
1
2
3
4
5
6
7
8
9
10
11
12
13
14ExecutorService scheduledThreadPool = Executors.newScheduledThreadPool(int corePoolSize);
//源码
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) {
return new ScheduledThreadPoolExecutor(corePoolSize);
}
//ScheduledThreadPoolExecutor():
public ScheduledThreadPoolExecutor(int corePoolSize) {
super(corePoolSize, Integer.MAX_VALUE,
DEFAULT_KEEPALIVE_MILLIS, MILLISECONDS,
new DelayedWorkQueue());
}SingleThreadExecutor() 单线程化的线程池
只能有一个工作线程执行任务;所有任务按指定顺序执行
1
2
3
4
5
6
7
8
9ExecutorService singleThreadPool = Executors.newSingleThreadPool();
//源码
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
线程池的停止
Executor框架提供了Java线程池的能力,ExecutorService扩展了Executor,提供了管理线程生命周期的关键能力。其中,ExecutorService.submit返回了Future对象来描述一个线程任务,它有一个cancel()方法。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41public class InterruptByFuture {
public static void main(String[] args) throws Exception {
ExecutorService es = Executors.newSingleThreadExecutor();
Future<?> task = es.submit(new MyThread());
try {
//限定时间获取结果
task.get(5, TimeUnit.SECONDS);
} catch (TimeoutException e) {
//超时触发线程中止
System.out.println("thread over time");
} catch (ExecutionException e) {
throw e;
} finally {
boolean mayInterruptIfRunning = true;
task.cancel(mayInterruptIfRunning);
}
}
private static class MyThread extends Thread {
public void run() {
while (!Thread.currentThread().isInterrupted()) {
try {
System.out.println("count");
Thread.sleep(1000);
} catch (InterruptedException e) {
System.out.println("interrupt");
Thread.currentThread().interrupt();
}
}
System.out.println("thread stop");
}
public void cancel() {
interrupt();
}
}
}Future的get方法可以传入时间,如果限定时间内没有得到结果,将会抛出TimeoutException。此时,可以调用Future的cancel()方法,对任务所在线程发出中断请求。
cancel()有个参数mayInterruptIfRunning,表示任务是否能够接收到中断。
mayInterruptIfRunning=true时,任务如果在某个线程中运行,那么这个线程能够被中断;
mayInterruptIfRunning=false时,任务如果还未启动,就不要运行它,应用于不处理中断的任务
要注意,mayInterruptIfRunning=true表示线程能接收中断,但线程是否实现了中断不得而知。线程要正确响应中断,才能真正被cancel。
线程池的shutdownNow()会尝试停止池内所有在执行的线程,原理也是发出中断请求。
生产者-消费者模型实现
Java多线程实现生产消费模型的5种方式_java 线程 生产 消费-CSDN博客
采用wait()和notify()的结合方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116package Multithreading;
import java.util.ArrayList;
import java.util.List;
public class ProducerConsumerDemo1 {
/**
* 生产者
*/
static class Producer implements Runnable {
private Produce produce;
public Producer(Produce produce) {
this.produce = produce;
}
public void run() {
while (true) {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
produce.produce();
}
}
}
/**
* 消费者
*/
static class Consumer implements Runnable {
private Produce produce;
public Consumer(Produce produce) {
this.produce = produce;
}
public void run() {
while (true) {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
produce.consume();
}
}
}
/**
* 缓冲区
*/
static class Produce {
private final int MAX_SIZE = 10;
private List<Object> list = new ArrayList<>();
/**
* 生产产品
*/
public void produce() {
synchronized (list) {
while (list.size() >= MAX_SIZE) {
System.out.println("生产者" + Thread.currentThread().getName() + "仓库满了");
try {
list.wait();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
//没满
list.add(new Object());
System.out.println("生产者" + Thread.currentThread().getName() + "生产了一个产品,现有" + list.size() + "件产品");
list.notifyAll();
}
}
/**
* 消费产品
*/
public void consume() {
synchronized (list) {
while (list.isEmpty()) {
System.out.println("消费者是" + Thread.currentThread().getName() + "仓库容量为空");
try {
list.wait();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
// 不是空可以进行消费
list.remove(0);
System.out.println("消费者" + Thread.currentThread().getName() + "消费了一个产品,现在还剩有产品" + list.size());
list.notifyAll();
}
}
}
public static void main(String[] args) {
Produce produce = new Produce();
new Thread(new Producer(produce)).start();
new Thread(new Producer(produce)).start();
new Thread(new Producer(produce)).start();
new Thread(new Consumer(produce)).start();
new Thread(new Consumer(produce)).start();
new Thread(new Consumer(produce)).start();
}
}1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58/**
* 使用wait()和notify()实现
*/
public class First {
static final int size = 10;
static Queue<String> queue = new ArrayDeque<>(size);
static final Object lock = new Object();
public static void main(String[] args) {
// 生产者线程
new Thread(() -> {
for (int i = 0; i < 30; i++) {
try {
Thread.sleep(100);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
String good = "产品" + i;
synchronized (lock) {
while (queue.size() == size) {
try {
lock.wait();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
queue.add(good);
System.out.println(good + "生产放入");
lock.notifyAll();
}
}
}).start();
// 消费者线程
new Thread(() -> {
while (true) {
try {
Thread.sleep(100);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
synchronized (lock) {
while (queue.isEmpty()) {
try {
lock.wait();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
String msg = queue.poll();
System.out.println(msg + "已消费");
lock.notifyAll();
}
}
}).start();
可重入锁ReentrantLock的实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83/**
* 可重入锁ReentrantLock的实现
*/
public class Second {
static final Lock lock = new ReentrantLock();
/**
* 任意一个Java对象,都拥有一组监视器方法(定义在Object类中),主要包括wait,notify,notifyAll方法,这些方法与synchornized关键字相配合,可以实现等待/通知模式。
* Condition接口也提供了类似的Object的监视器方法,与Lock配合可以实现等待/通知模式。
*/
static final Condition empty = lock.newCondition();
static final Condition full = lock.newCondition();
static final int size = 10;
static final Queue<String> queue = new ArrayDeque<>(size);
public static void main(String[] args) {
//生产者
new Thread(new Runnable() {
public void run() {
try {
Thread.sleep(100);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
for (int i = 0; i < 20; i++) {
//上锁,同步,跟synchronized作用差不多
lock.lock();
try {
if (queue.size() == size) {
try {
//满了,阻塞
full.await();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
String msg = "生产消息:" + i;
queue.add(msg);
System.out.println(msg);
//signal方法把在当前Condition对象的等待队列里的等待最久的线程,转移到当前Lock的等待队列里
empty.signal();//不为空
} finally {
//一定会走到这里,释放锁
lock.unlock();
}
}
}
}).start();
//消费者
new Thread(new Runnable() {
public void run() {
try {
Thread.sleep(100);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
while (true) {
lock.lock();
try {
if (queue.isEmpty()) {
//空了阻塞
try {
empty.await();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
} else {
String msg = queue.remove();
System.out.println(msg + "已消费");
//未满
full.signal();
}
} finally {
lock.unlock();
}
}
}
}).start();
}
}阻塞队列BlockingQueue实现
BlockingQueue接口的一些方法
操作 抛异常 特定值 阻塞 超时 插入 add(o) offer(o) put(o) offer(o, timeout, timeunit) 移除 remove(o) poll(o) take(o) poll(timeout, timeunit) 检查 element(o) peek(o) BlockingQueue提供了多个实现类,常用的有:
ArrayBlockingQueue:基于数组实现的有界阻塞队列;
LinkedBlockingQueue:基于链表实现的有界或无界阻塞队列;
PriorityBlockingQueue:基于优先级堆实现的无界阻塞队列;
SynchronousQueue:不存储元素的阻塞队列,每个插入操作必须等待一个相应的删除操作。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49/**
* 阻塞队列BlockingQueue实现
*/
public class Third {
public static void main(String[] args) {
BlockingQueue<String> queue = new ArrayBlockingQueue<>(10);
new Thread(new Runnable() {
public void run() {
for (int i = 0; i < 30; i++) {
try {
Thread.sleep(100);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
String msg = "消息:" + i;
try {
queue.put(msg);
System.out.println(msg + " 已发送");
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
}).start();
new Thread(new Runnable() {
public void run() {
while (true){
try {
Thread.sleep(100);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
try {
String msg = queue.take();
System.out.println(msg + "已消费");
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
}).start();
}
}信号量Semaphore的实现
信号量可以控制访问相应资源的线程的数量,从而实现生产消费模型
- 构造方法:Semaphore的构造方法接受一个整数参数,表示许可证的数量。该参数决定了同时可以有多少个线程能够获取许可证。
- 获取许可证:调用acquire()方法可以尝试获取一个许可证,如果许可证可用,线程会立即获取许可证并继续执行;否则线程会被阻塞,直到有许可证可用为止。
- 释放许可证:调用release()方法可以释放一个许可证,使其可供其他线程获取。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49/**
* 阻塞队列BlockingQueue实现
*/
public class Third {
public static void main(String[] args) {
BlockingQueue<String> queue = new ArrayBlockingQueue<>(10);
new Thread(new Runnable() {
public void run() {
for (int i = 0; i < 30; i++) {
try {
Thread.sleep(100);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
String msg = "消息:" + i;
try {
queue.put(msg);
System.out.println(msg + " 已发送");
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
}).start();
new Thread(new Runnable() {
public void run() {
while (true){
try {
Thread.sleep(100);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
try {
String msg = queue.take();
System.out.println(msg + "已消费");
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
}).start();
}
}使用消息队列
这个是取巧的办法,直接使用现成的消息中间件服务(如RocketMq、RabbitMq、Kafka等),分分钟搞定。手动微笑
花里胡哨问题补充
volatile部分CPU缓存一致性协议
volatile部分指令重排的类型和原理
指令重排看上面部分+最下面多线程部分
CAS原理和ABA问题
ThreadLocal原理和内存泄露
Object的wait和notify代码和场景相关问题
concurrent包下
想精通Java并发?五种锁机制是你必懂的! (baidu.com)
线程的wait和sleep方法的区别_线程的wait和sleep区别-CSDN博客
设计模式
| 重载 | 重写 | |
|---|---|---|
| 位置 | 所有重载函数必须在同一个类中 | 继承关系中,子类重写父类的方法 |
| 特点 | 函数名相同,参数列表不同,其他无关 | 函数名相同、参数列表相同、子类的返回值类型小鱼等于父类返回值类型 |
七大设计原则
单一职责原则
一个类=只有一个引起它变化的原因。(只负责担任一个职责)
如果一个类的职责过多,即耦合度太高=一个职责变化会影响到其他的职责
开放封闭原则
一个实体(类、函数、模块等)应该对外扩展开放,对内修改关闭
1、即每次发生变化时,要通过添加新的代码来增强现有类型的行为,而不是修改原有的代码。
2、符合开放封闭原则的最好方式是提供一个固有的接口,然后让所有可能发生变化的类实现该接口,让固定的接口与相关对象进行交互。里氏代替原则
子类必须替换掉它们的父类型
1、在软件开发过程中,子类替换父类后,程序的行为是一样的。
2、只有当子类替换掉父类后软件的功能不受影响时,父类才能真正地被复用,而子类也可以在父类的基础上添加新的行为。依赖倒置原则
细节应该依赖于抽象,而抽象不应该依赖于细节。
依赖倒置的本质原则就是 :通过抽象(接口或抽象类)使各个类或模块实现彼此独立,互不影响,实现模块间的松耦合。- 每个类尽量都要有接口或抽象类,或者抽象类和接口两者都具备。
- 变量的显示类型尽量是接口或者抽象类。
- 任何类尽量不从具体类派生。
- 尽量不要覆写基类的方法
- 结合里氏替换原则。 父类出现的地方子类就能出现
所谓的的 “面向接口编程,而不是面向实现编程”。这样可以降低客户与具体实现的耦合。
接口隔离原则
使用多个专门功能的接口,而不是使用单一的总接口。
不要让一个单一的接口承担过多的职责,而应把每个职责分离到多个专门的接口中,进行接口分离。
合成复用原则
在一个新的对象里面使用一些已有的对象,使之成为新对象的一部分。
新对象通过向这些对象的委派达到复用已用功能的目的。简单地说,就是要尽量使用合成/聚合,尽量不要使用继承。
最少知识原则(迪米特法则)
一个模块或对象应尽量少的与其他实体之间发生相互作用,使得系统功能模块相对独立,这样当一个模块修改时,影响的模块就会越少,扩展起来更加容易。
1、关于迪米特法则的其他描述:只与你直接的朋友们通信;不要跟“陌生人”说话。
2、外观模式(Facade Pattern)和中介者模式(Mediator Pattern)就使用了迪米特法则。
三大类设计模式(23种)

创建型
对类的实例化进行抽象。封装了具体类的信息,隐藏了类的实例化过程
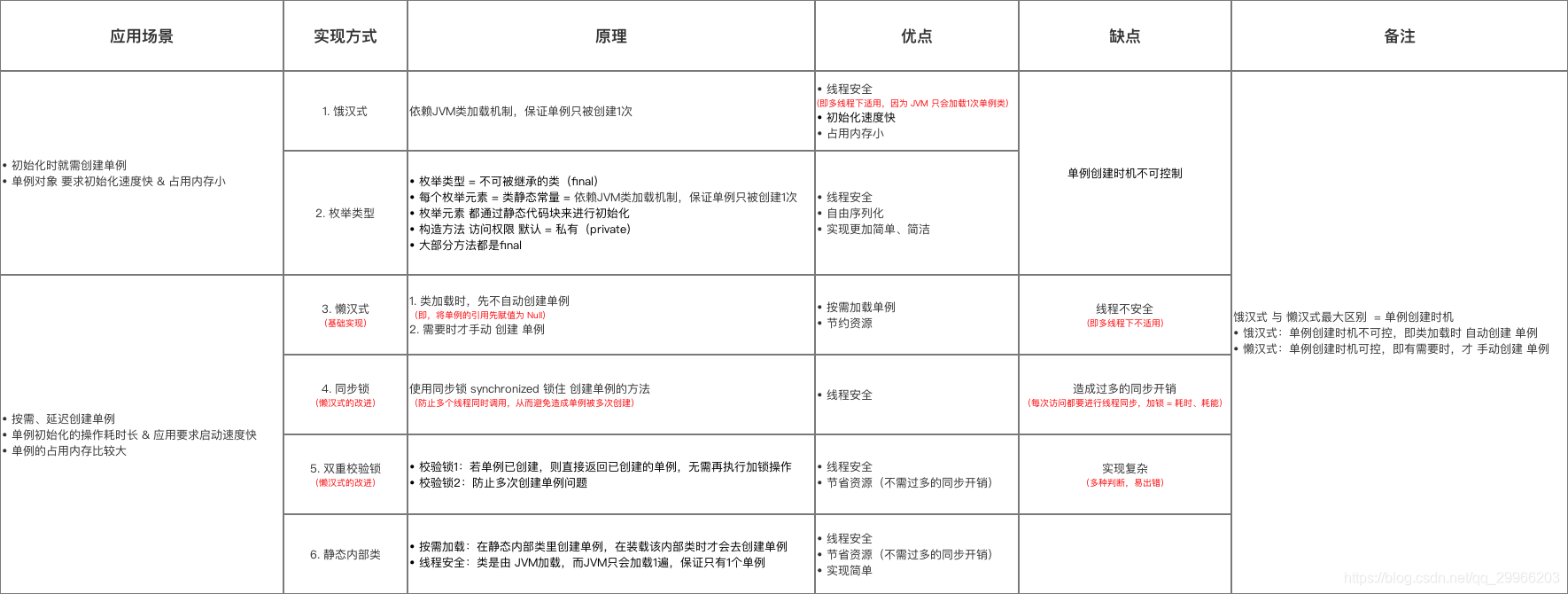
单例模式(Singleton)
单例类必须自己创建自己的唯一实例:把类的构造方法私有化,内部进行实例化,不让外部调用构造方法实例化
单例类必须给所有其他对象提供这一实例:定义共有方法提供该类全局唯一访问点,外部通过调用getInstance()方法来返回唯一实例1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106package DesignPatterns;
public class SingleExample {
/**
* 1. 饿汉式
* 最简单的单例实现方式。依赖JVM类加载机制,保证单例只会被创建1次,即线程安全。
* JVM在类的初始化阶段(即 在Class被加载后、被线程使用前),会执行类的初始化,
* 在执行类的初始化期间,JVM会去获取一个锁。这个锁可以同步多个线程对同一个类的初始化
*/
/* private static SingleExample instance = new SingleExample();
//函数构造权限为私有权限,其他地方无法创建
private SingleExample(){
}
public static SingleExample getInstance() {
return instance;
}*/
/**
* 2. 懒汉式(按需、延迟创建单例)
* 最简单的单例实现方式。有需要时才手动创建单例,即 线程不安全。
*/
/* private static SingleExample instance = null;
//函数构造权限为私有权限,其他地方无法创建
private SingleExample(){
}
public static SingleExample newInstance() {
// 先判断单例是否为空,以避免重复创建
if( instance == null){
instance = new SingleExample();
}
return instance;
}*/
/**
* 针对懒汉式优化1
* 使用同步锁
*/
/* private static SingleExample instance = null;
//函数构造权限为私有权限,其他地方无法创建
private SingleExample(){
}
public static synchronized SingleExample newInstance() {
// 先判断单例是否为空,以避免重复创建
if( instance == null){
instance = new SingleExample();
}
return instance;
}*/
/**
* 针对懒汉式优化2
* 同时也针对同步锁的优化,因为同步锁每次访问都要进行线程同步(即 调用synchronized锁),造成过多的同步开销(加锁 = 耗时、耗能)
* 双重校验锁
*/
private static SingleExample instance = null;
//函数构造权限为私有权限,其他地方无法创建
private SingleExample(){
}
public static SingleExample newInstance() {
// 先判断单例是否为空,以避免重复创建
if(instance == null){
synchronized (SingleExample.class){
if (instance == null){
instance = new SingleExample();
}
}
}
return instance;
}
// 说明
// 校验锁1:第1个if
// 作用:若单例已创建,则直接返回已创建的单例,无需再执行加锁操作
// 即直接跳到执行 return ourInstance
// 校验锁2:第2个 if
// 作用:防止多次创建单例问题
// 原理
// 1. 线程A调用newInstance(),当运行到②位置时,此时线程B也调用了newInstance()
// 2. 因线程A并没有执行instance = new Singleton();,此时instance仍为空,因此线程B能突破第1层 if 判断,运行到①位置等待synchronized中的A线程执行完毕
// 3. 当线程A释放同步锁时,单例已创建,即instance已非空
// 4. 此时线程B 从①开始执行到位置②。此时第2层 if 判断 = 为空(单例已创建),因此也不会创建多余的实例
}
- 简单工厂模式(SimpleFactory Pattern)
通过在工厂类定义一个静态方法负责生产产品对象实例。(类似现实生活中工厂生产产品)
将“类实例化的操作”与“使用对象的操作”分开,让使用者不用知道具体参数就可以实例化出所需要的“产品”类,从而避免了在客户端代码中显式指定,实现了解耦。即使用者可直接消费产品而不需要知道其生产(实例化)的细节。
优点:将创建实例的工作与使用实例的工作分开,使用者不必关心类对象如何创建,实现了解耦;
把初始化实例时的工作放到工厂里进行,使代码更容易维护。 更符合面向对象的原则 & 面向接口编程,而不是面向实现编程。
缺点:工厂类集中了所有实例(产品)的创建逻辑,一旦这个工厂不能正常工作,整个系统都会受到影响;
违背“开放 - 关闭原则”,一旦添加新产品就不得不修改工厂类的逻辑,这样就会造成工厂逻辑过于复杂。
简单工厂模式由于使用了静态工厂方法,静态方法不能被继承和重写,会造成工厂角色无法形成基于继承的等级结构。
1 | /** |
- 工厂方法模式(Factory Method)
工厂方法模式可理解为多态工厂模式,通过定义工厂父类负责定义创建对象的公共接口,而子类则负责生成具体的对象。将类的实例化(具体产品的创建)延迟到工厂类的子类(具体工厂)中完成,即由子类来决定该实例化(创建)哪一个类。
解决了简单工厂的缺点,在保留了简单工厂的封装优点的同时,让扩展变得简单,让继承变得可行,增加了多态性的体现。
(添加新产品时,除了增加新产品类外,还要提供与之对应的具体工厂类,系统类的个数将成对增加,在一定程度上增加了系统的复杂度;同时,有更多的类需要编译和运行,会给系统带来一些额外的开销;
由于考虑到系统的可扩展性,需要引入抽象层,在客户端代码中均使用抽象层进行定义,增加了系统的抽象性和理解难度,且在实现时可能需要用到DOM、反射等技术,增加了系统的实现难度。
虽然保证了工厂方法内的对修改关闭,但对于使用工厂方法的类,如果要更换另外一种产品,仍然需要修改实例化的具体工厂类;一个具体工厂只能创建一种具体产品)
1 | /** |
- 抽象工厂模式(Abastract Factory)
抽象工厂模式,即Abstract Factory Pattern,提供一个创建一系列相关或相互依赖对象的接口,而无须指定它们具体的类;具体的工厂负责实现具体的产品实例。
抽象工厂模式与工厂方法模式最大的区别:抽象工厂中每个工厂可以创建多种类的产品;而工厂方法每个工厂只能创建一类。
允许使用抽象的接口来创建一组相关产品,而不需要知道或关心实际生产出的具体产品是什么,这样就可以从具体产品中被解耦。
可解决工厂模式缺点:每个工厂只能创建一类产品。
1 | /** |
简单工厂 : 用来生产同一等级结构中的任意产品。(不支持拓展增加产品)
工厂方法 :用来生产同一等级结构中的固定产品。(支持拓展增加产品)
抽象工厂 :用来生产不同产品族的全部产品。(不支持拓展增加产品;支持增加产品族)
- 建造者模式(Builder Pattern)
适用于一个类内部数据结构过于复杂时(用于很多数据,且组织装配复杂),通过构建者模式可以对类中的数据按部就班地创建与设置。即Builder模式可以将一个类的构建和表示进行分离。
创建者模式又叫建造者模式,是将一个复杂的对象的构建与它的表示分离,使
得同样的构建过程可以创建不同的表示。创建者模式隐藏了复杂对象的创建过程,它把复杂对象的创建过程加以抽象,通过子类继承或者重载的方式,动态地创建具有复合属性的对象。
如果一个类构造器需要传入很多参数的时候就可以使用Builder进行重构
1 | /** |
- 原型模式(Prototype Pattern)
原型模式(Prototype Pattern)是用于创建重复的对象,同时又能保证性能。这种类型的设计模式属于创建型模式,它提供了一种创建对象的最佳方式。
这种模式是实现了一个原型接口,该接口用于创建当前对象的克隆。当直接创建对象的代价比较大时,则采用这种模式。例如,一个对象需要在一个高代价的数据库操作之后被创建。我们可以缓存该对象,在下一个请求时返回它的克隆,在需要的时候更新数据库,以此来减少数据库调用。
适用于:
类初始化需要消耗非常多的资源,这个资源包括数据、硬件资源等,通过原型拷贝避免这些消耗。
通过new产生一个对象需要非常繁琐的数据准备或访问权限,这时可以使用原型模式。
一个对象需要供给其他对象访问,而且各个对象都需要修改其值时,可以拷贝多个对象供调用者访问,即保护性拷贝。
浅拷贝和深拷贝
浅拷贝又叫影子拷贝,上面我们在拷贝文档时并没有把原文档中的字段都重新构造了一遍,而只是拷贝了引用,也就是副文档的字段引用原始文档的字段,这样的话修改副文档中的内容就会连原始文档也改掉了,这就是浅拷贝
深拷贝就是在浅拷贝的基础上,对于引用类型的字段也要采用拷贝的形式,比如上面的images,而像String、int这些基本数据类型则没关系
所以在运用原型模式时建议大家还是用深拷贝,下面我们把上面的浅拷贝改成深拷贝
1 | public class WordDocument implements Cloneable { |
1 | //Intent中的原型模式 |
我们常用的Intent,ArrayList等
登录模块中保存的用户信息类需要通过服务器更新用户信息,但是有很多地方需要调用,需要设置为对其他用到的模块只读,这个时候可以考虑用原型模式进行保护性拷贝
结构型
- 适配器模式(Adapter)
系统需要使用现有的类,而此类的接口不符合系统的需要,即接口不兼容
想要建立一个可以重复使用的类,用于与一些彼此之间没有太大关联的一些类,包括一些可能在将来引进的一些类一起工作
需要一个统一的输出接口,而输入端的接口不可预知
优点: 1、可以让任何两个没有关联的类一起运行。 2、提高了类的复用。 3、增加了类的透明度。 4、灵活性好。
缺点: 1、过多地使用适配器,会让系统非常零乱,不易整体进行把握。比如,明明看到调用的是 A 接口,其实内部被适配成了 B 接口的实现,一个系统如果太多出现这种情况,无异于一场灾难。因此如果不是很有必要,可以不使用适配器,而是直接对系统进行重构。 2.由于 JAVA 至多继承一个类,所以至多只能适配一个适配者类,而且目标类必须是抽象类。
使用场景:有动机地修改一个正常运行的系统的接口,这时应该考虑使用适配器模式。
注意事项:适配器不是在详细设计时添加的,而是解决正在服役的项目的问题。
1 | /** |
- 桥梁模式(Bridge)
看的有点懵逼,回头再看
- 代理模式
看的有点懵逼,回头再看
- 装饰模式(Decorate)
动态的给一个对象添加一些额外的职责。就增加功能来说,装饰模式比生成子类(继承)更为灵活的方案。
装饰模式主要在于扩展了类的功能。装饰模式通过在被装饰组件的方法执行之前或之后加入新的方法来实现功能的扩展.
具体应用:Android源码中的ContextWrapper
1 | /** |
- 外观模式(Facade Pattern)
外观模式(Facade Pattern)隐藏系统的复杂性,并向客户端提供了一个客户端可以访问系统的接口。这种类型的设计模式属于结构型模式,它向现有的系统添加一个接口,来隐藏系统的复杂性。
这种模式涉及到一个单一的类,该类提供了客户端请求的简化方法和对现有系统类方法的委托调用。
用于为子系统中的一组接口提供一个一致的界面,外观模式定义了一个高层接口,这个接口使得这一子系统更加容易使用。
1 | //相机功能接口 |
应用:很多的第三方SDK,比如友盟统计;我们平时开发过程中封装的模块,比如网络模块、ImageLoader模块等
行为型
- 模板方法模式(Template Method)
定义一个模板结构,将具体内容延迟到子类去实现。在不改变模板结构的前提下在子类中重新定义模板中的内容。
模板方法模式是基于”继承“的;
- 观察者模式(Observer Pattern)
| 角色 | 说明 |
|---|---|
| 抽象主题/被观察者(Observable) | 抽象主题把所有的观察者对象的引用保存在一个集合里,每个主题可以有任意数量的观察者,抽象主题提供接口,可以增加和删除观察者对象 |
| 具体的主题(具体的被观察者) | 也就是抽象主题的子类,该角色将有关状态存入具体观察者对象,在具体主题内部状态发生改变时,通知所有注册过的观察者 |
| 抽象观察者 | 观察者的抽象类,定义了一个更新的接口 |
| 具体观察者 | 实现了抽象观察者的更新接口,在被观察者状态发生变化时更新自身的状态 |
观察者模式通过将主题和观察者解耦,实现了对象之间的松耦合。当主题的状态发生改变时,所有依赖于它的观察者都会收到通知并进行相应的更新。
1 | /** |
- 状态模式(State Pattern)
在状态模式(State Pattern)中,类的行为是基于它的状态改变的。这种类型的设计模式属于行为型模式。在状态模式中,我们创建表示各种状态的对象和一个行为随着状态对象改变而改变的 context 对象。
当代码中包含着大量与对象状态有关的条件语句。此时对象行为依赖于它的状态(属性),并可以根据它的状态改变它的相关行为。
优点: 1、封装了转换规则。 2、枚举可能的状态,在枚举状态之前需要确定状态种类。 3、将所有与某个状态有关的行为放到一个类中,并且可以方便地增加新的状态,只需要改变对象状态即可改变对象的行为。 4、允许状态转换逻辑与状态对象合成一体,而不是某一个巨大的条件语句块。 5、可以让多个环境对象共享一个状态对象,从而减少系统中对象的个数。
缺点: 1、状态模式的使用必然会增加系统类和对象的个数。 2、状态模式的结构与实现都较为复杂,如果使用不当将导致程序结构和代码的混乱。 3、状态模式对”开闭原则”的支持并不太好,对于可以切换状态的状态模式,增加新的状态类需要修改那些负责状态转换的源代码,否则无法切换到新增状态,而且修改某个状态类的行为也需修改对应类的源代码。
使用场景: 1、行为随状态改变而改变的场景。 2、条件、分支语句的代替者。
注意事项:在行为受状态约束的时候使用状态模式,而且状态不超过 5 个。
1 | /** |
- 策略模式(Stratege Pattern)
状态模式和策略模式的结构几乎完全一样,但它们的目的、本质却完全不一样。状态模式的行为是平行的、不可替换的,策略模式的行为是彼此独立、可相互替换的。用一句话来表述,状态模式把对象的行为包装在不同的状态对象里,每一个状态对象都有一个共同的抽象状态基类。状态模式的意图是让一个对象在其内部状态发生改变的时候,其行为也随之改变
状态模式:状态模式关注对象的内部状态改变,并相应地改变对象的行为。它将状态的管理和对象的行为解耦,使得状态变化不会导致对象行为的复杂性增加。
策略模式:策略模式关注对象的行为的变化,并提供了一种灵活的方式来选择不同的行为或算法。它将算法的选择和使用从对象中解耦,使得算法的变化不会影响到对象的使用者。
1 | /** |
- 责任链模式(Chain of Responsibility Pattern)
职责链上的处理者负责处理请求,客户只需要将请求发送到职责链上即可,无须关心请求的处理细节和请求的传递,所以职责链将请求的发送者和请求的处理者解耦了。
优点: 1、降低耦合度。它将请求的发送者和接收者解耦。 2、简化了对象。使得对象不需要知道链的结构。 3、增强给对象指派职责的灵活性。通过改变链内的成员或者调动它们的次序,允许动态地新增或者删除责任。 4、增加新的请求处理类很方便。
缺点: 1、不能保证请求一定被接收。 2、系统性能将受到一定影响,而且在进行代码调试时不太方便,可能会造成循环调用。 3、可能不容易观察运行时的特征,有碍于除错。
使用场景: 1、有多个对象可以处理同一个请求,具体哪个对象处理该请求由运行时刻自动确定。 2、在不明确指定接收者的情况下,向多个对象中的一个提交一个请求。 3、可动态指定一组对象处理请求。
1 | /** |
Android知识
四大组件
Activity
看到讲解Activity启动过程的部分,时间有限没有细看,后面回头看
Activity的四种启动方式浅看了,后面回头
完全退出应用部分了解
onRestoreInstanceState的bundle参数也会传递到onCreate方法中,你也可以选择在onCreate方法中做数据还原。
只有有id的组件自动保存状态
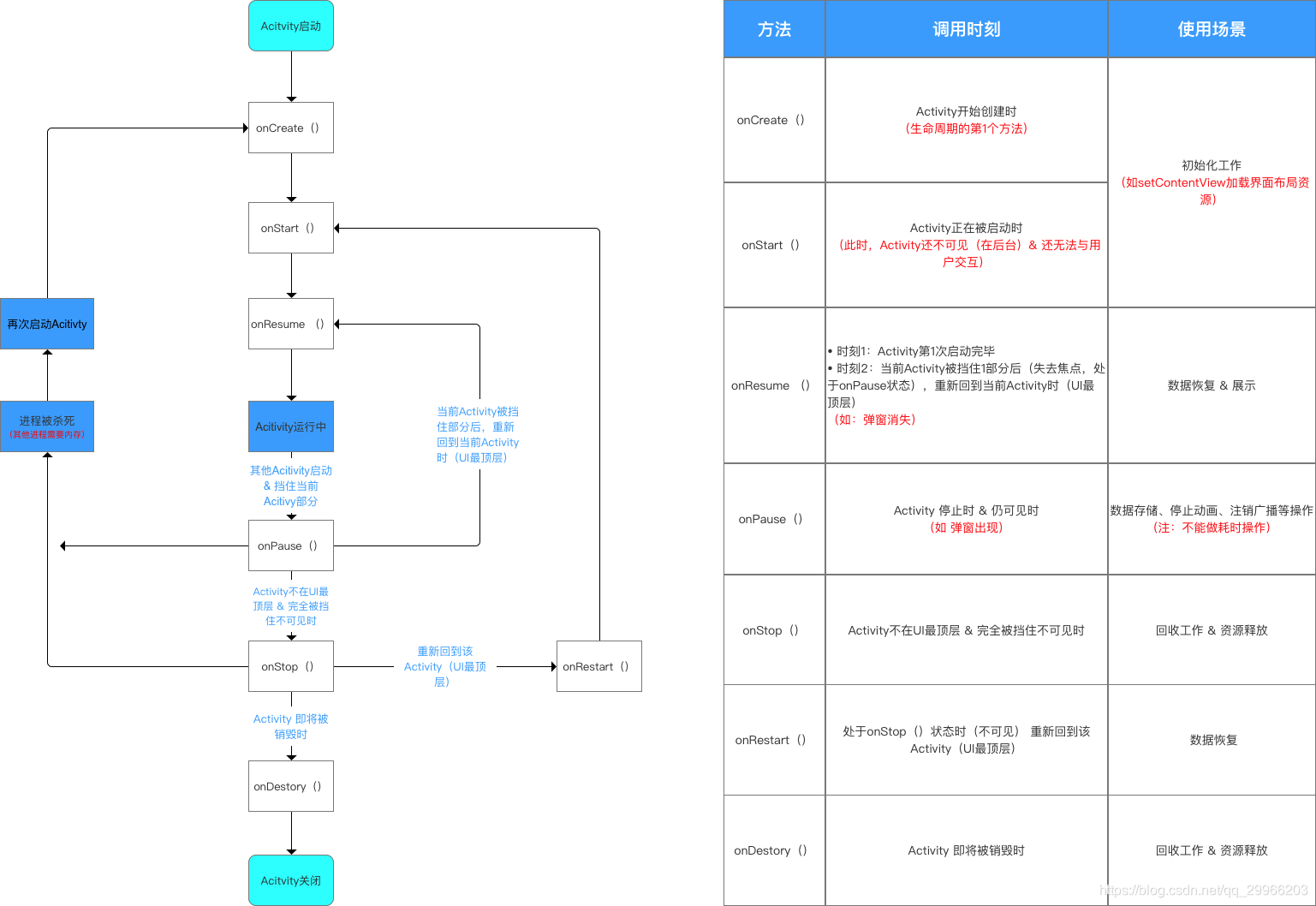
四种状态,七个方法
活动状态(Running/Active)、暂停状态(Paused)、停止状态(Stopped)、销毁状态(Killed)
onCreate、onStart、onResume、onPause、onStop、onDestory、onRestart
启动Activity流程图

Android系统重要组件AMS_android ams-CSDN博客
保存状态的生命周期图

Service
生命周期
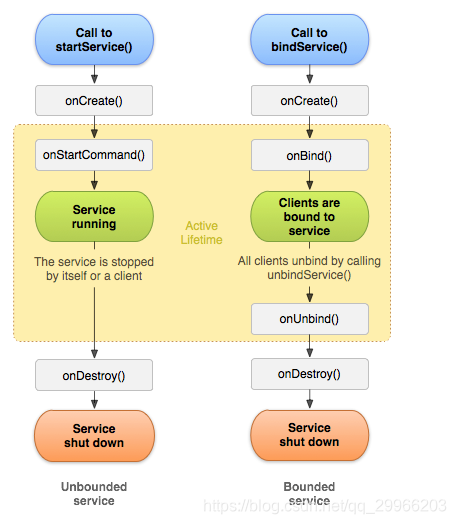
生命周期常用方法
1、4个手动调用方法
startService() 启动服务
stopService() 关闭服务
bindService() 绑定服务
unbindService() 解绑服务
2、5个内部自动调用方法
onCreat() 创建服务
onStartCommand() 开始服务
onDestroy() 销毁服务
onBind() 绑定服务
onUnbind() 解绑服务
startService()和bindService()的区别_startservice和bindservice区别-CSDN博客
简而言之就是不使用具体的Service里面的方法就不需要绑定Service,只需要让他自己在后台运行即可,要使用里面的具体方法就需要绑定Service,在onBind的回调会返回IBinder对象,就能调用Service里面的方法,另外,只要使用了bindService,不管之后是否解绑和停止服务,都可以调用服务中的方法,Service是UI线程
分类
可通信服务和不可通信服务
ServiceConnection()
前台服务和后台服务
本地服务和远程服务
AndroidManifest.xml中Service元素常见属性
1、android:name: 服务类名。可以是完整的包名+类名。也可使用. 代替包名。
2、android:exported: 其他应用能否访问该服务,如果不能,则只有本应用或有相同用户ID的应用能访问。默认为false。
3、android:process: 服务所运行的进程名。默认是在当前进程下运行,与包名一致。
4、android:permission: 申请使用该服务的权限,如果没有配置下相关权限,服务将不执行
IntentService
这是一个基于消息的服务,每次启动该服务并不是马上处理你的工作,而是首先会创建对应的Looper,Handler并且在MessageQueue中添加的附带客户Intent的Message对象,当Looper发现有Message的时候接着得到Intent对象通过在onHandleIntent((Intent)msg.obj)中调用你的处理程序,处理完后即会停止自己的服务,意思是Intent的生命周期跟你的处理的任务是一致的,所以这个类用下载任务中非常好,下载任务结束后服务自身就会结束退出。
IntentService与service的区别
IntentService是继承并处理异步请求的一个类,在IntentService内有一个工作线程来处理耗时操作,启动IntentService的方式和启动传统的Service一样,同时,当任务执行完后,IntentService会自动停止,而不需要我们手动去控制或stopSelf()。
另外,可以启动IntentService多次,而每一个耗时操作会以工作队列的方式在IntentService的onHandleIntent回调方法中执行,并且,每次只会执行一个工作线程,执行完第一个再执行第二个,以此类推。它本质上就是一个封装了HandlerThread+Handler的异步框架
BroadcastReceiver
系统广播(BoardcastReceiver)源码分析
广播接受者BoardcastReceiver,并重写onReceive()方法,通过Binder 机制在AMS注册
广播发送者 通过Binder 机制向AMS发送广播
AMS根据广播发送者要求,在已注册列表中,寻找合适的广播接收器(寻找依据:IntentFilter)并将广播发送到合适的广播接受者相应的消息循环队列中
广播接受者通过消息循环,拿到此广播,并回调onReceive()方法。
其中广播发送者与广播接受者的执行是异步的,即广播发送者不会关心有无接受者接收&也不确定接受者何时才能接收到。
本地广播(LocalBoardcastManager)的源码
构造函数是基于主线程的Looper新建了一个Handler,handleMessage中会调用接收器对广播的信息进行处理,也是LocalBroadcastManager 的核心部分
注册接收器部分,mReceivers 存储广播和过滤器信息,以BroadcastReceiver作为 key,IntentFilter链表作为 value。mReceivers 是接收器和IntentFilter的对应表,主要作用是方便在unregisterReceiver(…)取消注册,同时作为对象锁限制注册接收器、发送广播、取消接收器注册等几个过程的并发访问。
mActions 以Action为 key,注册这个Action的BroadcastReceiver链表为 value。mActions 的主要作用是方便在广播发送后快速得到可以接收它的BroadcastReceiver。
发送广播部分,先根据Action从mActions中取出ReceiverRecord列表,循环每个ReceiverRecord判断 filter 和 intent 中的 action、type、scheme、data、categoried 是否 match(intentFilter的match机制),是的话则保存到receivers列表中,发送 what 为MSG_EXEC_PENDING_BROADCASTS的消息,通过 Handler 去处理。
消息处理部分,mPendingBroadcasts转换为数组BroadcastRecord,循环每个receiver,调用其onReceive函数,这样便完成了广播的核心逻辑。
取消注册部分,从mReceivers及mActions中移除相应元素。
(1) LocalBroadcastManager 的核心实现实际还是 Handler,只是利用到了 IntentFilter 的 match 功能,至于 BroadcastReceiver 换成其他接口也无所谓,顺便利用了现成的类和概念而已。
(2) 因为是 Handler 实现的应用内的通信,自然安全性更好,效率更高。
本地广播发送的广播只在自身app传播。不必担心隐私数据泄露。
其他app无法对该app发送广播。不必担心安全漏洞的利用。
本地广播更加高效、安全。
高效:因为它内部是通过Handler实现的,它的sendBroadcast()方法含义并非和系统的sendBroadcast()一样,它的sendBroadcast()方法其实就是通过Handler发送了一个Message而已。
安全:既然它是通过Handler实现广播发送的,那么相比系统广播通过Binder机制实现那肯定更加高效,同时使用Handler来实现,别的app无法向我们应用发送该广播,而我们app内部发送的广播也不会离开我们的app。
LocalBroadcast内部协作主要是靠两个Map集合:mReceivers和mActions,当然还有一个List集合mPendingBroadcasts,这个主要存储待
ContentProvider
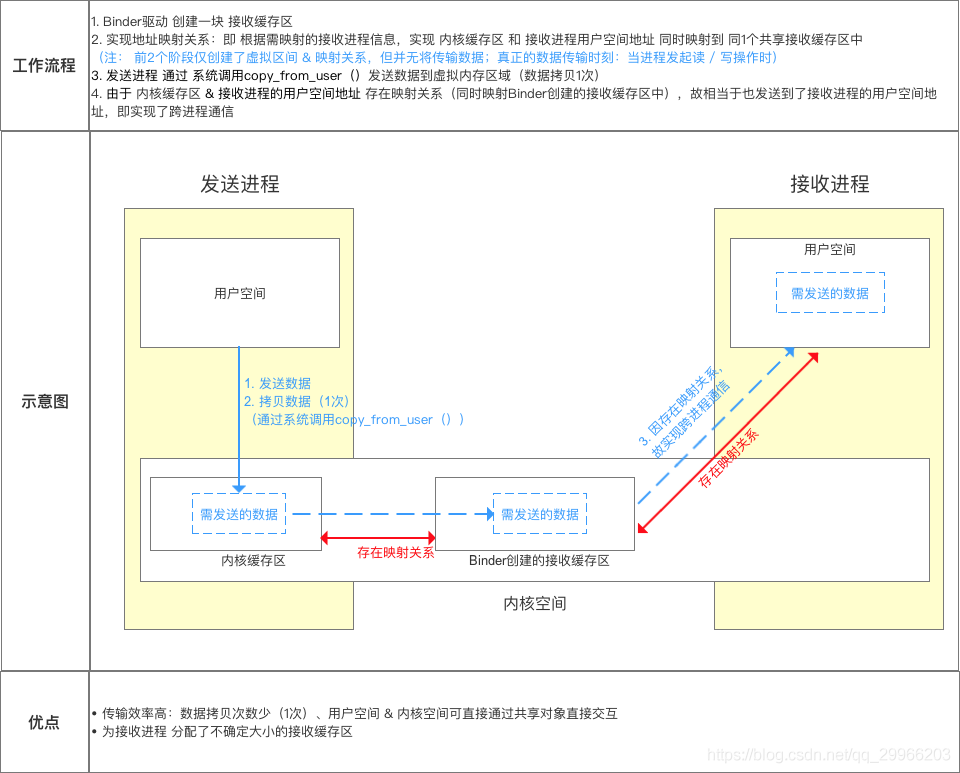
Android中的Binder机制
Binder是一种Android中实现跨进程通信(IPC)的方式
ContentProvider类
ContentProvider主要以表格形式组织数据(表、记录、字段)
1 | public Uri insert(Uri uri, ContentValues values)// 外部进程向 ContentProvider 中添加数据 |
ContentResolver类
统一管理不同 ContentProvider间的操作
1 | // 外部进程向 ContentProvider 中添加数据 |
ContentUris类
操作URI
1 | //withAppendedId()作用:向URI追加一个id |
UriMatcher类
- 在ContentProvider中注册URI
- 根据URI匹配ContentProvider对应的数据表
1 | // 步骤1:初始化UriMatcher对象 |
ContentObserver类
观察 Uri引起 ContentProvider 中的数据变化 & 通知外界(即访问该数据访问者):当ContentProvider 中的数据发生变化(增、删 & 改)时,就会触发该 ContentObserver类通知数据变化
适用场景:需要频繁检测的数据库或者某个数据是否发生改变,如果使用线程去操作,很不经济而且很耗时 。
1 | // 步骤1:注册内容观察者ContentObserver |
1 | //用来观察系统里短消息的数据库变化 ”表“内容观察者,只要信息数据库发生变化,都会触发该ContentObserver 派生类 |
看具体样例
其他补充
Intent
Android中提供了Intent机制来协助应用间的交互与通讯,或者采用更准确的说法是,Intent不仅可用于应用程序之间,也可用于应用程序内部的activity, service和broadcast receiver之间的交互。Intent这个英语单词的本意是“目的、意向、意图”。
Intent是一种运行时绑定(runtime binding)机制,它能在程序运行的过程中连接两个不同的组件。Intent负责对应应用中一次操作的动作、动作涉及数据、附加数据进行描述,通过Intent,你的程序可以向Android表达某种请求或者意愿,Android会根据意愿的内容选择适当的组件来响应。因此,Intent在这里起着一个媒体中介的作用,专门提供组件互相调用的相关信息,实现调用者与被调用者之间的解耦。
Intent_intent-filter多个action-CSDN博客
Activity跳转作用
显式意图和隐式意图
隐式
1 | <activity android:name="net.loonggg.intent.SecondActivity" > |
1 | public void start(View view) { |
setData、setDataAndType、setType 这三种方法只能单独使用,不可共用。 intent.setData(data)和intent.setType(type)注意这两个方法会互相清除,意思就是:如果先设置setData(data)后设置setType(type),那么后设置的setType(type)会把前面setData(data)设置的内容清除掉,而且会报错,反之一样,所以如果既要设置类型与数据,那么使用setDataAndType(data,type)这个方法。
Intent传输数据作用
基本数据类型
Bundle类型
Serializable和Parcelable
Serializable的作用是为了保存对象的属性到本地文件、数据库、网络流、rmi以方便数据传输,当然这种传输可以是程序内的也可以是两个程序间的。
对于对于Serializable,类只需要实现Serializable接口,并提供一个序列化版本id(serialVersionUID)即可
(Java的序列化机制是通过在运行时判断类的serialVersionUID来验证版本一致性的。在进行反序列化时,JVM会把传来的字节流中的serialVersionUID与本地相应实体(类)的serialVersionUID进行比较,如果相同就认为是一致的,可以进行反序列化,否则就会出现序列化版本不一致的异常。添加serialVersionUID使得在序列化时保持版本的兼容性,即在版本升级时反序列化仍保持对象的唯一性。)
Android的Parcelable的设计初衷是因为Serializable效率过慢,为了在程序内不同组件间以及不同Android程序间(AIDL)高效的传输数据而设计,这些数据仅在内存中存在,Parcelable是通过IBinder通信的消息的载体。
Parcelable的性能比Serializable好,在内存开销方面较小,所以在内存间数据传输时推荐使用Parcelable,如activity间传输数据,而Serializable可将数据持久化方便保存,所以在需要保存或网络传输数据时选择Serializable,因为android不同版本Parcelable可能不同,所以不推荐使用Parcelable进行数据持久化。
总结:所以在传递对象时对于需要传递的对象的序列化选择可以加以区分,需要数据持久化的建议实现Serializable接口,只在内存间数据传输时推荐使用Parcelable。
Application
实现
创建模式:单例模式
整个应用程序只有一个Application对象,每个App都有一个Application实例
实例模式:全局实例
不同组件都可以获得Application对象且都是同一对象
生命周期:等于Android App的生命周期
Fragment
生命周期
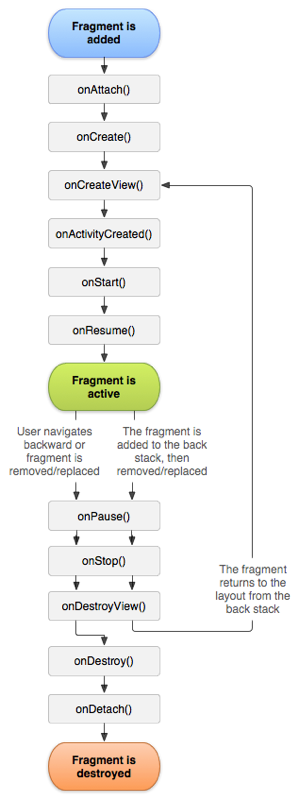
1、 onAttach:Fragment和Activity建立关联的时候调用,可以获得对应的Context或Activity,这里拿到的Activity是mHost.getActivity()
2、 onCreate:Fragment对象初始创建,用于执行初始化操作。
由于Fragment的onCreate调用时,关联的Activity可能没有创建好,所以不要有依赖外部Activity布局的操作。依赖Activity的操作可以放在onActivityCreate中。
3、 onCreateView:为Fragment创建视图(加载布局)时调用(给当前的fragment绘制UI布局,可以使用线程更新UI)
4、 onActivityCreated:当与Fragment关联的Activity中的onCreate方法执行完后调用(表示activity执行onCreate方法完成了的时候会调用此方法)
这个方法里做些和布局、状态恢复有关的操作,如
onViewStateRestored(Bundle)用于一个Fragment在从就状态回复,获取saveInstanceState恢复状态。
以上4步同步于Activity的onCreate
5、 onStart:Fragment可见时调用,将Fragment对象显示给用户。同步于Activity的onStart
6、 onResume:Fragment对象可见并可与用户交互时调用。同步于Activity的onResume
7、 onPause:Fragment对象与用户不再交互。同步于Activity的onPause
8、 onStop:Fragment对象不再显示给用户。同步于Activity的onStop
9、 onDestroyView:Fragment中的布局被移除时调用(表示fragment销毁相关联的UI布局)
10、onDestroy:Fragment状态清理完成
11、 onDetach:Fragment和Activity解除关联的时候调用(脱离activity)
fragment被创建
onAttach()–>onCreate()–>onCreateView()–>onActivityCreated()
fragment显示
onStart()–>onResume()
fragment进入后台模式(进入后台只走到onDestroyView())
onPause()–>onStop()–>onDestroyView()
fragment被销毁(持有它的activity被销毁)
onPause()–>onStop()–>onDestroyView()–>onDestroy()–>onDetach()
fragment重新恢复
onCreateView()–>onActivityCreated()–>onStart()–>onResume()
与Activity生命周期对比
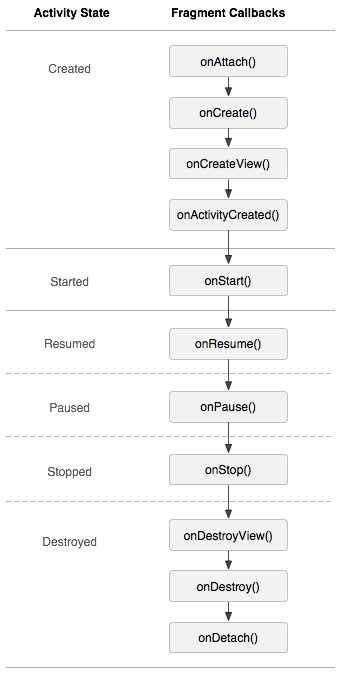
当activity处于Resumed状态时,可以自由地添加和移除fragment,也即是说,只有activity在Resumed状态时,fragment的状态可以独立改变。
但是,当activity离开Resumed状态,fragment的生命周期被activity控制。
事实上,Fragment的生命周期除了它第一次创建或销毁之外,都是由Activity启动。
也就是在Activity启动会执行onCreate(),Fragment会执行onAttach()->onCreate()->onCreateView()->onActivityCreated(),后面其他的生命周期方法Fragment都跟在Activity后面,Activity执行那么Fragment也会执行相应的代码
特别的:
正常销毁(后退键返回)
Activity:onPause()
Fragment:onPause()
Activity:onSaveInstanceState()
Fragment:onSaveInstanceState()
Activity:onStop()
Fragment:onStop()
Activity:onStop()
Fragment:onStop()
特殊部分
Fragment:onDestroyView()
Activity:onDestroy()
Fragment:onDestroy()
Fragment:onDetach()
后台意外销毁和返回(横竖屏切换)
Activity:onPause()
Fragment:onPause()
Activity:onSaveInstanceState()
Fragment:onSaveInstanceState()
Activity:onStop()
Fragment:onStop()
Fragment:onDestroyView()
Activity:onDestroy()
Fragment:onDestroy()
Fragment:onDetach()
Activity:onCreate()
Fragment:onAttach()->onCreate()->onCreateView()->onActivityCreated()
Activity:onStart()
Fragment:onStart()
Activity:onRestoreInstanceState()
Activity:onResume()
Fragment:onResume()
Activity会额外执行一个还原状态的方法onRestoreInstanceState,介于onStart和onResume之间
切换Fragment的方法
通过add、hide、show方式切换Fragment时所有的view都会保存在内存,不会销毁与重建(构建好后切换只需自动调用**onHiddenChanged()**方法)(add后只是隐藏而不是销毁视图再重建,对于使用频率很高的Fragement,使用该方式的性能会更高)
通过 replace 方法进行替换的时,Fragment 都是进行了销毁,重建的过程,相当于走了一整套的生命周期(切换会自动走所有的生命周期)
使用ViewPager(构建好后切换自动调用setUserVisVleHint(true),true就显示,false不可见进行切换,进行懒加载要调用了onCreateView()方法进行标记判断,加标志位)
使用ViewPager与Fragment切换时,Fragment会进行预加载操作,即所有的Fragment都会提前初始化setUserVisVleHint()方法在 Fragment 1 第一次加载的时候不走,只有在切换的时候 走该方法。
主动调用 setUserVisibleHint()方法来控制第一次不会调用setUserVisibleHint方法的问题setUserVisibleHint()方法优先onCreateView方法,当onCreateView方法调用后还会再次调用setUserVisibleHint方法。此时要对是否调用了onCreateView()方法进行标记判断。
一些相关类和接口
- FragmentManager 是一个抽象类,定义了一些和 Fragment 相关的操作和内部类/接口。
1 | public abstract FragmentTransaction beginTransaction();//开启一系列对 Fragments 的操作 |
BackStackEntry:Fragment 后退栈中的一个元素。
onBackStackChangedListener:后退栈变动监听器,回退栈中有变化时调用。
FragmentLifecycleCallbacks: FragmentManager 中所有的 Fragment 生命周期监听。
FragmentManager 定义的任务是由 FragmentManagerImpl 实现的。
FragmentTransaction事务
通过FragmentManager获取FragmentTransaction,beginTransaction() 返回一个新的 BackStackRecord (BackStackRecord 既是对 Fragment 进行操作的事务的真正实现,也是 FragmentManager 中的回退栈的实现),继承自FragmentTransaction
commit() 在主线程中异步执行,其实也是 Handler 抛出任务,等待主线程调度执行。(commit() 需要在宿主 Activity 保存状态之前调用,否则会报错。
这是因为如果 Activity 出现异常需要恢复状态,在保存状态之后的 commit() 将会丢失,这和调用的初衷不符,所以会报错。)commitAllowingStateLoss() 也是异步执行,但它的不同之处在于,允许在 Activity 保存状态之后调用,也就是说它遇到状态丢失不会报错。
因此我们一般在界面状态出错是可以接受的情况下使用它。
这种方式是不安全的,因为事务提交时Activity可能还没有恢复,会丢失提交的事务。commitNow() 是同步执行的,立即提交任务。
前面提到 FragmentManager.executePendingTransactions() 也可以实现立即提交事务。但我们一般建议使用 commitNow(), 因为另外那位是一下子执行所有待执行的任务,可能会把当前所有的事务都一下子执行了,这有可能有副作用。
和 commit() 一样,commitNow() 也必须在 Activity 保存状态前调用,否则会抛异常。此外,这个方法提交的事务可能不会被添加到 FragmentManger 的后退栈,因为你这样直接提交,有可能影响其他异步执行任务在栈中的顺序。
commitNowAllowingStateLoss()同步执行
对比
Fragment
其实是对 View 的封装,它持有 view, containerView, fragmentManager, childFragmentManager 等信息
FragmentManager
是一个抽象类,它定义了对一个 Activity/Fragment 中 添加进来的 Fragment 列表、Fragment 回退栈的操作、管理方法,还定义了获取事务对象的方法,具体实现在 FragmentImpl 中
FragmentTransation
定义了对 Fragment 添加、替换、隐藏等操作,还有四种提交方法,具体实现是在 BackStackRecord 中
添加到Activity方法
xml直接静态添加fragment标签,name指定具体的Fragment
xml使用占位符进行动态添加,如FragmentLayout,在java代码中进行添加
Fragment 内部有一个 childFragmentManager,通过它管理子 Fragment。在添加子 Fragment 时,把子 Fragment 的布局 add 到父 Fragment 即可。
与Activity通信
Bundle通信
接口回调
Fragment之间通信
- 通过FragmentManager标签获得Fragment对象
在MenuFragment中的ListView条目点击事件中通过标签获取到MainFragment,并调用对应的setData()方法,将数据设置进去,从而达到数据传递的目的。
1 | lv.setOnItemClickListener(new AdapterView.OnItemClickListener() { |
- 采用接口回调的方式
- 第三方开源框架EventBus
getFragmentManager,getSupportFragmentManager ,getChildFragmentManager三者之间的区别
getFragmentManager()所得到的是所在fragment 的父容器的管理器。
getChildFragmentManager()所得到的是在fragment 里面子容器的管理器。
getSupportFragmentManager()主要用于支持 3.0以下android系统API版本,3.0以上系统可以直接调用getFragmentManager()
注:getFragmentManager到的是activity对所包含fragment的Manager,而如果是fragment嵌套fragment,那么就需要利用getChildFragmentManager()
ViewPager的适配器区别,现在用ViewPager2了,只有一个适配器了
ViewPager有PagerAdapter和FragmentStatePagerAdapter
使用FragmentPagerAdapter 时,Fragment对象会一直存留在内存中,所以当有大量的显示页时,就不适合用FragmentPagerAdapter了,FragmentPagerAdapter 适用于只有少数的page情况,像选项卡。
原因:步长外的页面会调用destroyItem,但只有onDestroyView调用了,没有调用onDestory,也没有调用onDetach,所以fragment只是把上面的view销毁了,fragment并没有销毁,下次再创建的时候,只会调用onCreateView和onActivityCreated
当使用FragmentStatePagerAdapter 时,如果Fragment不显示,那么Fragment对象会被销毁,(滑过后会保存当前界面,以及下一个界面和上一个界面(如果有),最多保存3个,其他会被销毁掉)
原因:会真正销毁(同时销毁view和fragment,调用onDestroyView以及其后面的所有销毁方法),重建时会从最初的onAttach开始一直到onActivityCreated。但在回调onDestroy()方法之前会回调onSaveInstanceState(Bundle outState)方法来保存Fragment的状态,下次Fragment显示时通过onCreate(Bundle savedInstanceState)把存储的状态值取出来,FragmentStatePagerAdapter 比较适合页面比较多的情况,像一个页面的ListView 。
ViewPager2只有FragmentStateAdapter,继承自RecyclerView.Adapter
具体实例看回自己之前的学习笔记
ViewPager加载Fragmet情况下实现懒加载
首先需要几个标志位
1 | boolean mIsPrepare = false; //视图还没准备好=>onCreateView |
在onCreateView中确保View已经准备好,将mIsPrepare设置为true,在setUserVisibleHint中确保当前可见后设置mIsVisible为true,第一次加载完毕后则将mIsFirstLoad置为false,避免重复加载
在onDestroyView中进行默认值的初始化,保证Fragment销毁后进行默认值的初始化
卡顿优化
优化方案一:设置缓存页面数
viewPager.setOffscreenPageLimit(int limit) 能够有效地一次性缓存多个Fragment,这样就能够解决在之后每次切换时不会创建实例对象,看起来也会流畅。但是这样的做法,最大的缺点就是容易造成第一次启动时非常缓慢!如果第一次启动时间满足要求的话,就使用这种简单地办法吧。
优化方案二:避免Fragment的销毁
不管是FragmentStatePagerAdapter还是FragmentPagerAdapter,其中都有一个方法可以被覆写:
1 |
|
把中间的代码注释掉就行了,这样就可以避免Fragment的销毁过程,一般情况下能够这样使用,但是容易出现一个问题,如果注释掉,一旦Activity被回收进入异常销毁状态,Fragment就无法恢复之前的状态,因此这种方法也是有纰漏和局限性的。
- 优化方案三:避免重复创建View
优化Viewpager和Fragment的方法就是尽可能地避免Fragment频繁创建,当然,最为耗时的都是View的创建。所以更加优秀的优化方案,就是在Fragment中缓存自身有关的View,防止onCreateView函数的频繁执行
1 | public class MyFragment extends Fragment { |
onCreateView中将会对rootView进行null判断,如果为null,说明还没有缓存当前的View,因此会进行过缓存,反之则直接利用。当然,最为重要的是需要在onDestroyView() 方法中及时地移除rootView,因为每一个View只能拥有一个Parent,如果不移除,将会重复加载而导致程序崩溃。
其实ViewPager+Fragment的方式,ViewPager中显示的就是Fragment中所创建的View,Fragment只是一个控制器,并不会直接显示于ViewPager之中,这一点容易被忽略。
Fragment的坑,如何解决
内存重启:内存重启本质就是Android系统(而非开发人员手动)杀死进程并重启进程的过程。会在进程结束前调用onSaveInstanceState保存Activity现场状态,同时会在进程创建后恢复。(屏幕旋转等配置变化也会赵成当前的Activity重启)
- 在系统要把app资源回收之前,系统会把Activity的状态保存下来,Activity的FragmentManager负责把Activity中的Fragment保存起来。
- 在“内存重启”后,Activity的恢复是从栈顶逐步恢复,Fragment会在宿主Activity的onCreate方法调用后紧接着恢复(从onAttach生命周期开始)
getActivity()空指针
- 内存重启/pop了Fragment后Fragment的异步任务仍在执行,且执行时调用了getActivity方法,此时会报空指针异常。
- 调用了getActivity()时,当前的Fragment已经onDetach()了宿主Activity。
避免在Fragment已onDetach后再去调用宿主Activity。在Fragment基类里设置一个Activity mActivity的全局变量,在onAttach(Activity activity)里赋值,使用mActivity代替getActivity(),保证Fragment即使onDetach后,仍持有Activity的引用(有引起内存泄露的风险,但是异步任务没停止的情况下,本身就可能已内存漏,相比Crash,这种做法“安全”些)
异常:Can not perform this action after onSaveInstanceState
- Activity在调用onSaveInstanceState()保存当前Activity的状态后,直到Activity状态恢复之前,你commit 一个FragmentTransaction,就会抛出该异常——导致Activity状态丢失
- 当框架调用onSaveInstanceState()的时候,它会向这个方法传递一个Bundle参数,Activity可以用这个参数来保存页面、对话框、Fragments和视图的状态。当onSaveInstanceState返回时,会将一个Bundle对象序列化之后通过Binder接口传递给系统服务进程,并安全的保存起来。当系统晚一点想要重启Activity的时候, 它会把之前的Bundle对象传递回应用,并用来恢复Activity之前的状态。
所以为什么会抛出之前的异常呢?问题的根源在于Bundle这个对象仅仅是Activity在onSaveInstanceState()方法被调用那一刻的快照。这就意味着当你如果在onSaveInstanceState()之后再调用FragmentTransaction.commit()的话,由于这次Transaction没有被作为Activity状态的一部分来保存,自然也就丢失掉了。从用户的角度来说,Transaction的遗失就导致意外的UI状态丢失。那么为了维护良好的用户体验,Android系统会不惜一切代价的避免页面状态的丢失,所以在这种情况发生的时候就直接抛出了IllegalStateException。
解决方案直接看博客里面的吧第二章 Fragment_fragment的含义和作用-CSDN博客
布局
六大布局
LinearLayout线性布局
LinearLayout容器中的组件一个挨一个排列,通过控制android:orientation属性,可控制各组件是横向排列还是纵向排列。
RelativeLayout相对布局
相对布局可以让子控件相对于兄弟控件或父控件进行布局,可以设置子控件相对于兄弟控件或父控件进行上下左右对齐。
RelativeLayout能替换一些嵌套视图,当我们用LinearLayout来实现一个简单的布局但又使用了过多的嵌套时,就可以考虑使用RelativeLayout重新布局。FrameLayout帧布局
帧布局或叫层布局,从屏幕左上角按照层次堆叠方式布局,后面的控件覆盖前面的控件。帧布局为每个加入其中的组件创建一个空白的区域(称为一帧),每个子组件占据一帧,这些帧会根据gravity属性执行自动对齐。
该布局在开发中设计地图经常用到,因为是按层次方式布局,我们需要实现层面显示的样式时就可以
采用这种布局方式,比如我们要实现一个类似百度地图的布局,我们移动的标志是在一个图层的上面。
TableLayout表格布局TableLayout继承自Linearout,本质上仍然是线性布局管理器。表格布局采用行、列的形式来管理UI组件,并不需要明确地声明包含多少行、多少列,而是通过添加TableRow、其他组件来控制表格的行数和列数。
GridLayout网格布局
GridLayout把整个容器划分为rows × columns个网格,每个网格可以放置一个组件。提供了setRowCount(int)和setColumnCount(int)方法来控制该网格的行和列的数量。
AbsoluteLayout绝对布局(过时)
新的还有ConstraintLayout约束布局
RelativeLayout和LinearLayout性能对比
通过网上的很多实验结果我们得之,两者绘制同样的界面时layout和draw的过程时间消耗相差无几,关键在于measure过程RelativeLayout比LinearLayout慢了一些。故从RelativeLayout和LinearLayout的onMeasure过程来探索耗时问题的根源。
根据源码我们发现RelativeLayout会根据2次排列的结果对子View各做一次measure。首先RelativeLayout中子View的排列方式是基于彼此的依赖关系,而这个依赖关系可能和Xml布局中View的顺序不同,在确定每个子View的位置的时候,需要先给所有的子View排序一下。又因为RelativeLayout允许ViewB在横向上依赖ViewA,ViewA在纵向上依赖B。所以需要横向纵向分别进行一次排序测量。
同时需要注意的是View.measure()方法存在以下优化:
1 | public final void measure(int widthMeasureSpec, int heightMeasureSpec) { |
即如果我们或者我们的子View没有要求强制刷新,而父View给子View传入的值也没有变化(也就是说子View的位置没变化),就不会做无谓的测量。RelativeLayout在onMeasure中做横向测量时,纵向的测量结果尚未完成,只好暂时使用myHeight传入子View系统。这样会导致在子View的高度和RelativeLayout的高度不相同时(设置了Margin),上述优化会失效,在View系统足够复杂时,效率问题就会很明显。
源码中已经标注了一些注释,需要注意的是在每次对child测量完毕后,都会调用child.getMeasuredHeight()获取该子视图最终的高度,并将这个高度添加到mTotalLength中。但是getMeasuredHeight暂时避开了lp.weight>0且高度为0子View,因为后面会将把剩余高度按weight分配给相应的子View。因此可以得出以下结论:
(1)如果我们在LinearLayout中不使用weight属性,将只进行一次measure的过程。
(2)如果使用了weight属性,LinearLayout在第一次测量时获取所有子View的高度,之后再将剩余高度根据weight加到weight>0的子View上。
由此可见,weight属性对性能是有影响的。
结论
1、RelativeLayout慢于LinearLayout是因为它会让子View调用2次measure过程,而LinearLayout只需一次,但是有weight属性存在时,LinearLayout也需要两次measure。
2、RelativeLayout的子View如果高度和RelativeLayout不同,会导致RelativeLayout在onMeasure()方法中做横向测量时,纵向的测量结果尚未完成,只好暂时使用自己的高度传入子View系统。而父View给子View传入的值也没有变化就不会做无谓的测量的优化会失效,解决办法就是可以使用padding代替margin以优化此问题。
3、在不响应层级深度的情况下,使用Linearlayout而不是RelativeLayout。
4、新建一个Android项目SDK会为我们自动生成的avtivity_main.xml布局文件,然后它的根节点默认是RelativeLayout?
DecorView的层级深度已知且固定的,上面一个标题栏,下面一个内容栏,采用RelativeLayout并不会降低层级深度,因此这种情况下使用LinearLayout效率更高。
5、作为顶级View的DecorView就是个垂直方向的LinearLayout,上面是标题栏,下面是内容栏,我们常用的setContentView()方法就是给内容栏设置布局?
为开发者默认新建RelativeLayout是希望开发者能采用尽量少的View层级,很多效果是需要多层LinearLayout的嵌套,这必然不如一层的RelativeLayout性能更好。因此我们应该尽量减少布局嵌套,减少层级结构,使用比如viewStub,include等技巧。可以进行较大的布局优化。
布局优化方案
减少层级,越简单越好,减少overdraw,就能更好的突出性能
Android系统是如何处理UI组件的更新操作的?
1、Android需要把XML布局文件转换成GPU能够识别并绘制的对象。这个操作是在DisplayList的帮助下完成的。DisplayList持有所有将要交给GPU绘制到屏幕上的数据信息。
2、CPU负责把UI组件计算成Polygons,Texture纹理,然后交给GPU进行栅格化渲染。
3、GPU进行栅格化渲染。(栅格化:把组件拆分到不同的像素上进行显示)
4、硬件展示在屏幕上。
需要注意的是:任何时候View中的绘制内容发生变化时,都会重新执行创建DisplayList,渲染DisplayList,更新到屏幕上等一系列操作。这个流程的表现性能取决于View的复杂程度,View的状态变化以及渲染管道的执行性能
Overdraw(过度绘制):描述的是屏幕上的某个像素在同一帧的时间内被绘制了多次。在多层次的UI结构里面,如果不可见的UI也在做绘制的操作,就会导致某些像素区域被绘制了多次,浪费大量的CPU以及GPU资源。(可以通过开发者选项,打开Show GPU Overdraw的选项,观察UI上的Overdraw情况)
所以我们需要尽量减少Overdraw。
include、merge、ViewStub标签
include标签常用于将布局中的公共部分提取出来,那么就可以直接include进去了。
merge标签是作为include标签的一种辅助扩展来使用,它的主要作用是为了防止在引用布局文件时产生多余的布局嵌套,Android渲染需要消耗时间,布局越复杂,性能就越差。如上述include标签引入了之前的LinearLayout之后导致了界面多了一个层级。这个时候用merge的话,就可以减少一个层级。(直接在include进来的布局部分使用,这样include的布局就不带LinearLayout标签了,减少嵌套)
ViewStub标签,viewstub是view的子类。他是一个轻量级View, 隐藏的,没有尺寸的View。他可以用来在程序运行时简单的填充布局文件。
检测布局深度的方法
- Dump UI Hierarchy for UI Atomator,分析UI层级
从Android Studio中启动Android Device Monitor: Tools -> Android -> Android Device Monitor.
- HierachyViewer
依次点击菜单Tools>Android>Android Device Monitor
启动Android Device Monitor成功之后,在新的的窗口中点击切换视图图标,选择Hierarchy View
自定义组件、动画
存储
网络
计网部分
具体要背,计网已经忘光了,先直接看了面试问题部分,看理解版本
直接看博客,记重点先
作为Android开发者,需要对数据链路层的TCP/IP,UDP协议非常了解。
如何发起一次完整的HTTP的请求流程_发送http请求-CSDN博客
HTTP
基于 TCP 传输协议的 HTTP 协议,由于是通过 四元组(源IP、源端口、目的 IP、目的端口)确定一条 TCP 连接
历代http优化及原因
http 各版本问题和优化_http-server版本-CSDN博客
HTTP1.1采用持久连接:只要任意一端没有明确提出断开连接,则保持 TCP 连接状态。旨在建立一次 TCP 连接后进行多次请求和响应的交互
HTTP1.0采用非持久连接:每个连接只能处理一个请求-响应事务请求方法、响应码
常用的为PUT和GET,HTTP协议定义了八种请求类型
状态码:
状态代码有三位数字组成,第一个数字定义了响应的类别,共分五种类别:
1xx:指示信息–表示请求已接收,继续处理
2xx:成功–表示请求已被成功接收、理解、接受
3xx:重定向–要完成请求必须进行更进一步的操作
4xx:客户端错误–请求有语法错误或请求无法实现
5xx:服务器端错误–服务器未能实现合法的请求
- Cookie和Session区别
存放位置不同
存取方式不同: Cookie中只能保存ASCII字符串,Session中可以保存任意类型的数据,甚至Java Bean乃至任何Java类、对象等。
安全性不同
有效期上的不同:Cookie的过期时间可以被设置很长。Session依赖于名为JSESSIONI的Cookie,其过期时间默认为-1,只要关闭了浏览器窗口,该Session就会过期,因此Session不能完成信息永久有效。如果Session的超时时间过长,服务器累计的Session就会越多,越容易导致内存溢出。
对服务器造成的压力不同:每个用户都会产生一个session,如果并发访问的用户过多,就会产生非常多的session,耗费大量的内存。因此,诸如Google、Baidu这样的网站,不太可能运用Session来追踪客户会话。
浏览器支持不同:Cookie运行在浏览器端,若浏览器不支持Cookie,需要运用Session和URL地址重写。
跨域支持不同: Cookie支持跨域访问(设置domain属性实现跨子域),Session不支持跨域访问
Token、Cookie&Session联系
在Web领域基于Token的身份验证随处可见。在大多数使用Web API的互联网公司中,tokens 是多用户下处理认证的最佳方式。大部分你见到过的API和Web应用都使用tokens。例如Facebook, Twitter, Google+, GitHub等。
具有以下几点特性:
1、无状态、可扩展
2、支持移动设备
3、跨程序调用
4、安全
socket
即套接字,是通信的基石,是应用层 与 TCP/IP 协议族通信的中间软件抽象层,本质为一个封装了 TCP / IP协议族 的编程接口(API)(不是协议,是一个编程调用接口,通过socket才能实现http协议,属于传输层)网络上的两个程序通过Socket实现一个双向的通信连接从而进行数据交换。
Socket是网络通信过程中端点的抽象表示,包含进行网络通信必须的五种信息:连接使用协议、(本地主机IP地址,本地进程的协议端口)、(远地主机IP地址,远地进程协议端口)。
Socket一般成对出现,一对套接字(其中一个运行在服务端一个运行在客户端)
- 原理
Socket是面向客户/服务器模型而设计的,针对客户和服务器程序提供不同的Socket系统调用。客户随机申请一个Socket,系统为之分配一个Socket号;服务器拥有全局公认的Socket,任何客户都可以向它发出连接请求和信息请求。
应用层通过传输层进行数据通信时,TCP会遇到同时为多个应用程序提供并发服务的问题,多个TCP连接多个应用程序进程可能需要通过同一个TCP协议端口传输数据,为了区别不同的应用程序进程和连接,许多计算机操作系统为应用程序与TCP/IP协议交互提供了套接字(socket)接口,应用层可以和传输层通过socket接口区分来自于不同应用进程或网络连接的通信,实现数据传输的并发服务。
即Socket相当于一个封装了TCP/IP协议的API,提供了程序内部与外界通信的端口,并为通信双方提供了数据传输通道。Socket类型为流套接字(streamsocket)和数据报套接字(datagramsocket)。流套接字将TCP作为其端对端协议,提供了一个可信赖的字节流服务。数据报套接字使用UDP协议,提供数据打包发送服务。

socket和HTTP的区别
Socket是套接字,对TCP/IP协议的封装。对端(IP地址和端口)的抽象表示。
HTTP协议是通信协议,是利用TCP在Web服务器和浏览器之间数据传输的协议。
Socket和HTTP协议本质上就不同。SOCKET本质对TCP/IP的封装,从而提供给程序员做网络通信的接口(即端口通信)。可理解为HTTP是一辆轿车模型框架,提供了所有封装和数据传递的形式;Socket是发动机,提供了网络通信的能力。Socket:属于传输层,因为 TCP / IP协议属于传输层,解决的是数据如何在网络中传输的问题。
HTTP协议:属于 应用层,解决的是如何包装数据。
HTTPS
超文本传输协议HTTP协议被用于在web浏览器和网站服务器之间传递信息。HTTP协议以明文方式发送内容,不提供任何方式的数据加密,如果攻击者截取了web浏览器和网站服务器之间的传输报文,就可以直接读懂其中的信息,因此HTTP协议不适合传输一些敏感信息,比如信用卡号,密码等。
为了解决HTTP协议的这一缺陷,需要使用使用另一种协议,安全套接字层超文本传输协议HTTPS。HTTPS在HTTP的基础上加入SSL(Secure Sockets Layer 安全套接字层)协议,SSL依靠证书来验证服务器的身份,为浏览器和服务器之间的通信加密。
相关定义
HTTPS(Hyper Text Transfer Protocol over Secure Socket Layer)是以安全为目标的Http通道,可理解为HTTP的加强版。实现原理是再HTTP下加入SSL层,SSL负责加密和解密数据(HTTPS = HTTP + SSL)
HTTPS的特点在于:
内容加密:采用混合加密技术,中间者无法直接查看明文内容。
混合加密:结合对称加密和非对称加密技术。客户端使用对称密钥对传输数据进行加密, 然后用非对称密钥对对称密钥进行加密。所以网络上传输的数据是被对称加密过的密文和用非对称加密后的密钥。因此即使被黑客截取。由于没有私钥,所以无法获取加密明文的密钥,也无法获取明文数据。
验证身份:确保浏览器访问的网站是经过CA验证的可信任网站。
数据完整性:防止传输的内容被中间人冒充或篡改。原理
发送方将对称加密的密钥通过非对称加密的公钥进行加密,接收方使用私钥进行解密得到对称加密的密钥,再通过对称加密交换数据。Https协议通过对称加密(传输快,传输交换数据)和非对称加密(安全,传输密钥)结合处理实现的。
和HTTP区别
定义上:
HTTP:超文本传输协议,是一个基于请求与响应,无状态的,应用层的协议,常基于TCP/IP协议传输数据,互联网上应用最为广泛的一种网络协议,所有的WWW文件都必须遵守这个标准。设计HTTP的初衷是为了提供一种发布和接收HTML页面的方法。
HTTPS:HTTPS是身披SSL外壳的HTTP。HTTPS是一种通过计算机网络进行安全通信的传输协议,经由HTTP进行通信,利用SSL/TLS建立全信道,加密数据包。HTTPS使用的主要目的是提供对网站服务器的身份认证,同时保护交换数据的隐私与完整性。
HTTPS协议需要CA申请证书(交费)(权威机构颁发证书——安全|自己生成的证书——不安全)
HTTP是超文本传输协议,信息是明文传输。HTTPS协议是SSL+HTTP协议构建的可进行加密传输、身份认证的安全的网络协议
HTTP和HTTPS使用不同连接方式,端口也不同(http:80,https:443)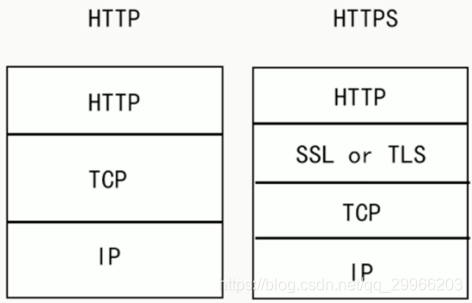
加密算法
见SSL和TLS下面
hash摘要
摘要算法(Hash算法):是一种单向算法,用户可以通过hash算法对目标信息生成特定长度的唯一hash值,却不能通过hash值重新得到目标信息,常用在不可还原的密码存储、信息完成性校验,如MD5、SHA等。CRC与MD5、SHA1等相比一般用作通信数据的校验,检错能力和安全性低,CRC计算结果是一个数值,叫做CRC值。(摘要算法用于解决 HTTP 传输数据容易被篡改的问题)
ca证书
CA(Certificate Authority,证书授权)是由认证机构服务者签发,是数字签名的技术基础保障,也是网上实体身份的证明,能够证明某一实体的身份及其公钥的合法性,证明该实体与公钥二者之间的匹配关系。
证书是公钥的载体,证书上的公钥与实体身份相绑定。现,一个是签名证书行的PKI机制一般为双证书机制,即一个实体应具有两个证书、两个密钥对,其中一个是加密证书,一个是签名证书,而加密证书原则上是不能用于签名的。
在电子商务系统中,所有实体的证书都是由证书授权中心即CA中心颁发并签名的。一个完整的、安全的电子商务系统必须建立一个完整的、合理的CA体系。CA体系由证书审批部门和证书操作部门组成。证书原理:数字证书在用户公钥后附加了用户信息及CA的签名。公钥是密钥对的一部分,另一部分是私钥。公钥公之于众,谁都可以使用。私钥只有自己知道。由公钥加密的信息只能由与之相对应的私钥解密。为确保只有某个人才能阅读自己的信件,发送者要用收件人的公钥加密信件;收件人便可用自己的私钥解密信件。同样,为证实发件人的身份,发送者要用自己的私钥对信件进行签名;收件人可使用发送者的公钥对签名进行验证,以确认发送者的身份。
在线交易中您可使用数字证书验证对方身份。用数字证书加密信息,可以确保只有接收者才能解密、阅读原文,信息在传递过程中的保密性和完整性。有了数字证书网上安全才得以实现,电子邮件、在线交易和信用卡购物的安全才能得到保证。建立连接过程

前面5步就是https握手过程
破解:中间人攻击(协议中间人攻击)
在密码学和计算机安全领域中,中间人攻击(Man-in-the-middle attack,缩写:MITM)是指攻击者与通讯的两端分别建立独立的联系,并交换其所收到的数据,使通讯的两端认为他们正在通过一个私密的连接与对方直接对话,但事实上整个会话都被攻击者完全控制。在中间人攻击中,攻击者可以拦截通讯双方的通话并插入新的内容。在许多情况下这是很简单的(例如,在一个未加密的 Wi-Fi 无线接入点的接受范围内的中间人攻击者,可以将自己作为一个中间人插入这个网络)。
简单来说攻击者就是一个介入通信的传话员,攻击者知道通信双方的所有通信内容,而且可以任意增加、删除、修改双方的通信内容,而双方对此并不知情。
而中间人攻击不仅仅局限于针对 HTTPS,对于开放性的连接,中间人攻击非常容易。比如在一个未加密的 Wi-Fi 网络中,一个攻击者可以很容易地将自己插入双方的通信之中以截取或者修改通信的内容。
在现实中,有多种方式可以确定某个实体的身份,比如个人的签名 / 私章、组织的公章、甚至古时的信物。大部分情况下,只需要在信件最后盖上签上自己的名字或者盖上组织的公章,那么接收者就可以确定这封信件就来自于他所声称的那个人 / 组织。在二进制的世界中,可以使用数字签名来确保某段消息 / 某份文件确实是由他所声称的那个实体所发出来的。
不过有个问题,如果中间人在会话建立阶段把双方交换的真实公钥替换成自己的公钥了,那么中间人还是可以篡改消息的内容而双方并不知情。为了解决这个问题,需要找一个通信双方都信任的第三方来为双方确认身份。这就像大家都相信公证处,公证处拿着自己的公章为每一封信件都盖上了自己的章,证明这封信确实是由本人发出的,这样就算中间人可以替换掉通信双方消息的签名,也无法替换掉公证处的公章。这个公章,在二进制的世界里,就是数字证书,公证处就是CA(数字证书认证机构)。
数字证书就是申请人将一些必要信息(包括公钥、姓名、电子邮件、有效期)等提供给 CA,CA 在通过各种手段确认申请人确实是他所声称的人之后,用自己的私钥对申请人所提供信息计算散列值进行加密,形成数字签名,附在证书最后,再将数字证书颁发给申请人,申请人就可以使用 CA 的证书向别人证明他自己的身份了。对方收到数字证书之后,只需要用 CA 的公钥解密证书最后的签名得到加密之前的散列值,再计算数字证书中信息的散列值,将两者进行对比,只要散列值一致,就证明这张数字证书是有效且未被篡改过的。
优缺点
优点
使用HTTPS协议可认证用户和服务器,确保数据发送到正确的客户机和服务器
HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,要比HTTP协议安全,防止数据在传输过程中被窃取,确保数据的完整性
HTTPS是现行架构下最安全的解决方案,虽然不是绝对安全,但是它大幅度增加了中间人攻击的成本
缺点相同网络环境下,HTTPS协议会使页面的加载时间延长50%,增加10%~20%耗电,此外,HTTPS协议还会影响缓存,增加数据开销和功耗(增加了加密解密过程)
HTTPS协议的安全是有范围的,在黑客攻击、拒绝服务攻击、服务器劫持方面几乎起不到什么作用
最关键的,SSL证书信用链体系并不安全,特别是再某些国家可以控制CA根证书的情况下,中间人攻击一样可行
成本方面:
(1)SSL的专业证书需要购买,功能越强大,费用越高
(2)SSL证书通常需要绑定固定IP,为服务器增加固定IP会增加一定费用
(3)HTTPS连接服务器端资源占用高,相同负载下会增加带宽和投入成本
SSL/TLS
SSL(Secure Sockets Layer 安全套接层),及其继任者传输层安全(Transport Layer Security,TLS)是为网络通信提供安全及数据完整性的一种安全协议。TLS与SSL在传输层对网络连接进行加密。
SSL协议位于TCP/IP协议与各种应用层协议之间,为数据通讯提供安全支持。SSL协议可分为两层:
SSL记录协议(SSL Record Protocol):它建立在可靠的传输协议(如TCP)之上,为高层协议提供数据封装、压缩、加密等基本功能的支持。 (通过对称加密实现,用来保证数据传输过程中完整性和私密性)
SSL握手协议(SSL Handshake Protocol):它建立在SSL记录协议之上,用于在实际的数据传输开始前,通讯双方进行身份认证、协商加密算法、交换加密密钥等。(通过非对称加密实现,负责握手过程的身份认证)
加密算法
(1)对称加密
原理:加密算法是公开的,靠的是密钥来加密数据。使用一个密钥加密,使用相同的密钥才能解密
常用算法:DES,3DES,AES
优点:计算量小,加密和解密速度较快,适合加密较大数据
缺点:在传输加密数据之前需要传递密钥,密钥传输容易泄露;一个用户需要对应一个密钥,服务器管理密钥比较麻烦(2)非对称加密
原理:加密算法是公开的,有一个公钥,一个私钥(公钥和私钥不是随机的,由加密算法生成);公钥加密只能私钥解密,私钥加密只能公钥解密,加密解密需要不同密钥
常用算法:RSA
优点:可以传输公钥(服务器—>客户端)和公钥加密的数据(客户端->服务器),数据传输安全
缺点:计算量大,加密和解密速度慢
数据链路层,IP层
ARP和RARP协议
ARP协议:实现IP地址向物理地址的映射\ RARP协议:实现物理地址向IP地址的映射
ICMP和IGMP
ICMP协议:探测&报告传输中产生的错误\IGMP协议:管理多播组测成员关系
NAT协议
NAT(网络地址转换):在专用网连接到因特网的路由器上安装NAT软件,安装了NAT软件的路由器叫NAT路由器。当一个分组离开专用网的时候,首先要通过一个NAT路由器,它会将内部的IP源地址转换成该公司所拥有的真实IP地址。注意私有IP地址的范围。NAT通常与防火墙组合使用。
DNS
DNS(域名解析系统):用来把便于人们使用的机器名字(域名)转换为IP地址;DNS系统采用客户/服务器模式,其协议运行在UDP上,使用53号端口。
常见协议
TCP
握手挥手
直接看博客理解版先吧
拥塞控制
可靠传输原理
计算机网络——TCP可靠性传输原理_tcp可靠传输的工作原理-CSDN博客
TCP 实现可靠传输的方式之一,是通过序列号与确认应答。
重传机制:
- 超时重传
- 快速重传
滑动窗口:
流量控制
拥塞控制
缺点以及如何改进
看下面UDP那个博客
TCP存在队头阻塞问题,TCP 队头阻塞的问题要从两个角度看,一个是发送窗口的队头阻塞,另外一个是接收窗口的队头阻塞(但是这个设计本来就是保证数据的有序性)
在 HTTP/2 连接上,不同 Stream 的帧是可以乱序发送的(因此可以并发不同的 Stream ),因为每个帧的头部会携带 Stream ID 信息,所以接收端可以通过 Stream ID 有序组装成 HTTP 消息,而同一 Stream 内部的帧必须是严格有序的。
但是 HTTP/2 多个 Stream 请求都是在一条 TCP 连接上传输,这意味着多个 Stream 共用同一个 TCP 滑动窗口,那么当发生数据丢失,滑动窗口是无法往前移动的,此时就会阻塞住所有的 HTTP 请求,这属于 TCP 层队头阻塞。
http3.0针对TCP缺点改进
看下面UDP那个博客
QUIC 也借鉴 HTTP/2 里的 Stream 的概念,在一条 QUIC 连接上可以并发发送多个 HTTP 请求 (Stream)。
但是 QUIC 给每一个 Stream 都分配了一个独立的滑动窗口,这样使得一个连接上的多个 Stream 之间没有依赖关系,都是相互独立的,各自控制的滑动窗口。假如 Stream2 丢了一个 UDP 包,也只会影响 Stream2 的处理,不会影响其他 Stream,与 HTTP/2 不同,HTTP/2 只要某个流中的数据包丢失了,其他流也会因此受影响。
对于 HTTP/1 和 HTTP/2 协议,TCP 和 TLS 是分层的,分别属于内核实现的传输层、openssl 库实现的表示层,因此它们难以合并在一起,需要分批次来握手,先 TCP 握手(1RTT),再 TLS 握手(2RTT),所以需要 3RTT 的延迟才能传输数据,就算 Session 会话服务,也需要至少 2 个 RTT,这在一定程序上增加了数据传输的延迟。HTTP/3 在传输数据前虽然需要 QUIC 协议握手,这个握手过程只需要 1 RTT,握手的目的是为确认双方的连接 ID,连接迁移就是基于连接 ID 实现的。
但是 HTTP/3 的 QUIC 协议并不是与 TLS 分层,因为 QUIC 也是应用层实现的协议,所以可以将 QUIC 和 TLS 协议握手的过程合并在一起,QUIC 内部包含了 TLS,它在自己的帧会携带 TLS 里的 记录,再加上 QUIC 使用的是 TLS1.3,因此仅需 1 个 RTT 就可以 同时 完成建立连接与密钥协商,甚至在第二次连接的时候,应用数据包可以和 QUIC 握手信息(连接信息 + TLS 信息)一起发送,达到 0-RTT 的效果。TCP连接数目上限
32位ip,16位端口(2进制),一共2^48,-1就是65535
65535,先记住这个数字吧
UDP
2022.9.06 UDP的优缺点,UDP适用场合,UDP实现客户端与服务端的通信步骤,UDP实现客户端与服务端的通信的完整代码。_udp的优点-CSDN博客
- 优缺点
- 和TCP比较
- 应用场景
- 一般和TCP一起出现,和TCP区别,如何通过UDP优化TCP的缺点
HTTP 3.0之QUIC优势和TCP弊端_如何用udp集成tcp的优势(说到http3.0),然后说到quic、tcp的滑动窗口、拥塞控制-CSDN博客
数据格式
JSON(JavaScript Object Notation, JS 对象简谱) 是一种轻量级的数据交换格式。它基于ECMAScript (欧洲计算机协会制定的js规范)的一个子集,采用完全独立于编程语言的文本格式来存储和表示数据。简洁和清晰的层次结构使得 JSON 成为理想的数据交换语言。 易于人阅读和编写,同时也易于机器解析和生成,并有效地提升网络传输效率。
JSONObject的数据是用 { } 来表示的
JSONArray的数据是由JSONObject构成的数组,用 [ { } , { } , …… , { } ] 来表示的
把Java对象JSON序列化,Jackson速度最快,在测试中比Gson快接近50%,FastJSON和Gson速度接近。
把JSON反序列化成Java对象,FastJSON、Jackson速度接近,Gson速度稍慢,不过差距很小。
因此初测的结论是:不管是字符串转对象,还是对象转字符串,gson的运行性能都是fastjson的两倍,且gson拥有更好的容错性,两者都是独立的,不依赖于其它JAR,因此推荐gson!

优势
- JSON数据清晰
- JSON有很多工具类支持它的转换
- JSON在所有主流浏览器有很好的支持
- JSON在传输时数据量更小
- JSON在JS中有天然的语言优势(因为它是标准的子集合)
缺点
- 不适合存储大量数据
- 不支持注解
- 不支持日期和时间类型
Android网络知识和框架
HttpURLConnection和HttpClient:这两种方式都支持HTTPS协议、以流的形式进行上传和下载、配置超时时间、IPv6、以及连接池等功能。
HtttpClient
DefaultHttpClient和它的兄弟AndroidHttpClient都是HttpClient具体的实现类,它们都拥有众多的API,而且实现比较稳定,bug数量也很少。
但同时也由于HttpClient的API数量过多,使得我们很难在不破坏兼容性的情况下对它进行升级和扩展,结构复杂,维护成本高。
Android SDK中包含了HttpClient,在Android6.0版本直接删除了HttpClient类库。
1 | public Boolean LoginGet(Context context,String username,String password){ |
HttpURLConnection
HttpURLConnection是一种多用途、轻量极的HTTP客户端,使用它来进行HTTP操作可以适用于大多数的应用程序。虽然HttpURLConnection的API提供的比较简单,但是同时这也使得我们可以更加容易地去使用和扩展它。
创建一个UrlConnManager类,然后里面提供getHttpURLConnection()方法用于配置默认的参数并返回HttpURLConnection
1 | public static HttpURLConnection getHttpURLConnection(String url){ |
发送POST请求,所以在UrlConnManager类中再写一个postParams()方法用来组织一下请求参数并将请求参数写入到输出流中
1 | public static void postParams(OutputStream output,List<NameValuePair>paramsList) throws IOException{ |
接下来我们添加请求参数,调用postParams()方法将请求的参数组织好传给HttpURLConnection的输出流,请求连接并处理返回的结果
1 | private void useHttpUrlConnectionPost(String url) { |
最后开启线程请求网络
1 | private void useHttpUrlConnectionGetThread() { |
Android2.2前不建议使用HttpURLConnection,Android4.4后,底层实现被OkHttp替换
Android5.0后HttpClient被官方弃用
所以,在Android 2.2版本以及之前的版本使用HttpClient是较好的选择,而在Android 2.3版本及以后,HttpURLConnection则是最佳的选择,它的API简单,体积较小,因而非常适用于Android项目。压缩和缓存机制可以有效地减少网络访问的流量,在提升速度和省电方面也起到了较大的作用。另外在Android 6.0版本中,HttpClient库被移除了,HttpURLConnection则是以后我们唯一的选择。
主流网络请求库
简介
网络请求开源库是一个将 网络请求+异步+数据处理 封装好的类库(网络请求是Android网络请求原生方法HttpClient或HttpURLConnection,异步包括多线程、线程池,数据处理包括序列化和反序列化)
使用网络请求库后,实现网络请求的需求同时不需要考虑:异步请求、线程池、缓存等等;降低开发难度,缩短开发周期,使用方便对比
现在使用人数变化很大,volley3.4k,android-async-http10.6k,okhttp 45.1k,retrofit 42.5k
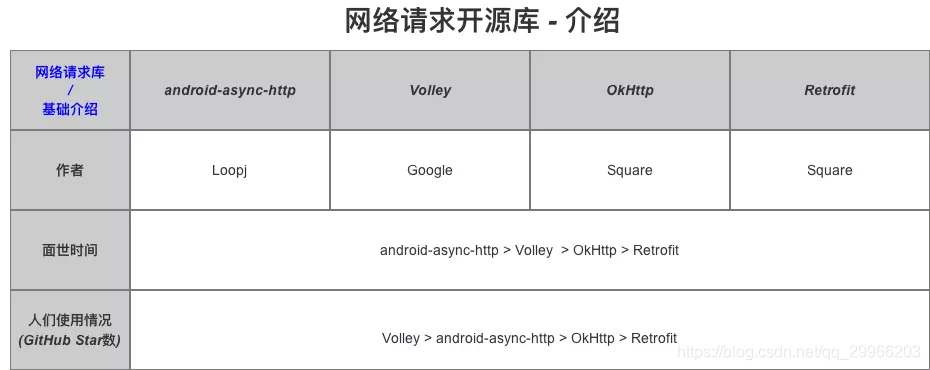
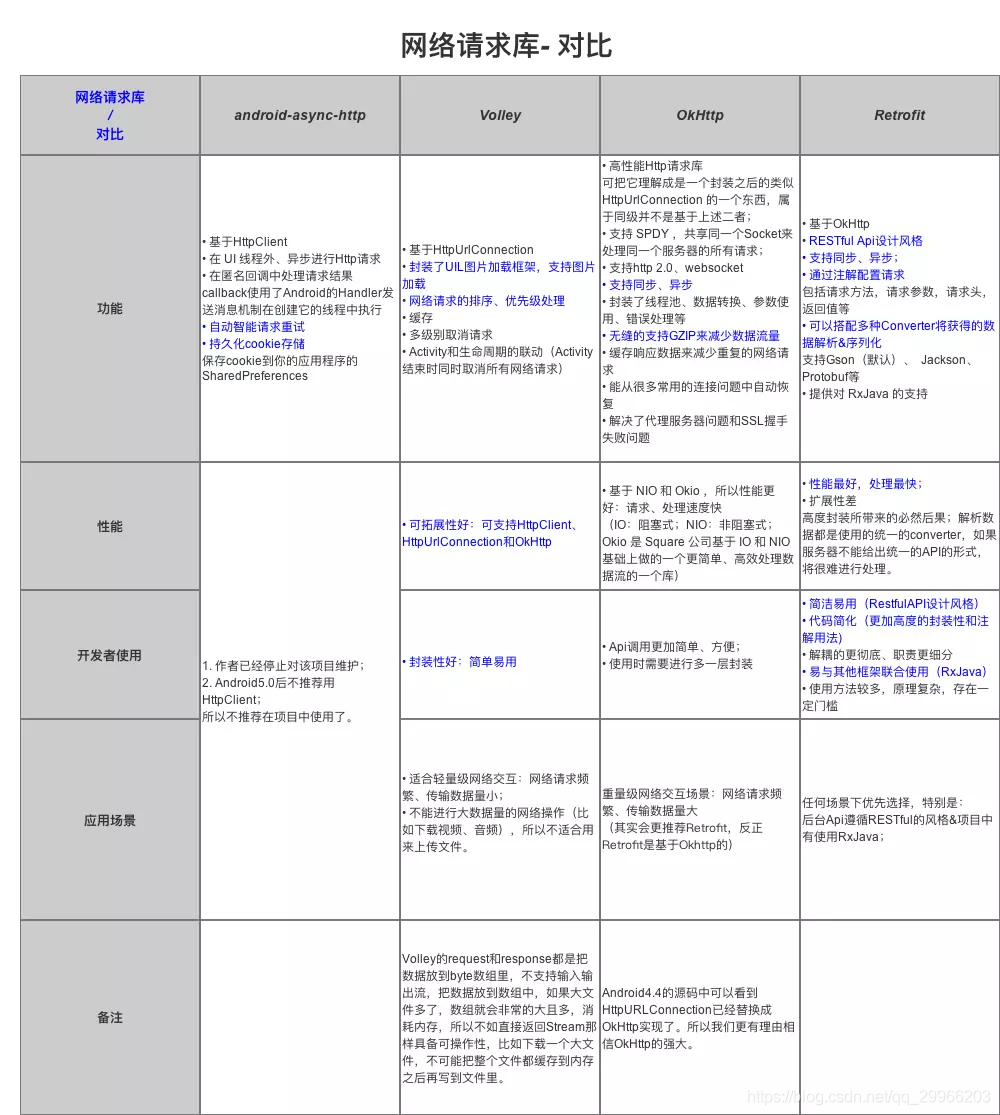
Volley
后面再进行补充,用的人少加上没用过。。。
OkHttp
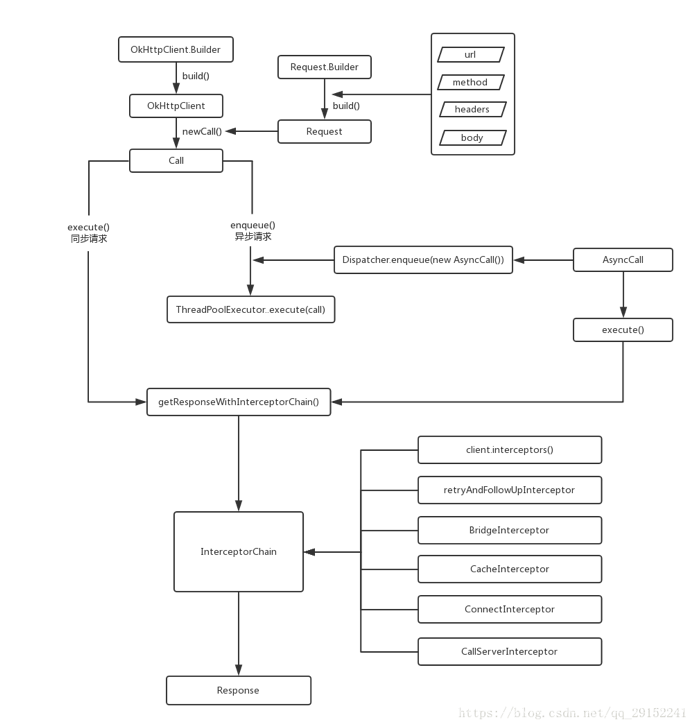
使用和工作原理
首先是OkHttpClient
(官方建议使用单例创建OkHttpClient,即一个进程中只创建一次即可,以后的每次交易都使用该实例发送交易。这是因为OkHttpClient拥有自己的连接池和线程池,这些连接池和线程池可以重复使用,这样做利于减少延迟和节省内存。)
1
2
3
4
5
6
7
8//OkHttpClient的构造采用了建造者模式
mOkHttpClient = new OkHttpClient.Builder()
.addInterceptor(loggingInterceptor)
.retryOnConnectionFailure(true)
.connectTimeout(TIME_OUT, TimeUnit.SECONDS)
.readTimeout(TIME_OUT, TimeUnit.SECONDS)
.build();1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37final Dispatcher dispatcher;//调度器
final
Proxy proxy;//代理
final List<Protocol> protocols;//协议
final List<ConnectionSpec> connectionSpecs;//传输层版本和连接协议
final List<Interceptor> interceptors;//拦截器
final List<Interceptor> networkInterceptors;//网络拦截器
final EventListener.Factory eventListenerFactory;
final ProxySelector proxySelector;//代理选择器
final CookieJar cookieJar;//cookie
final
Cache cache;//cache 缓存
final
InternalCache internalCache;//内部缓存
final SocketFactory socketFactory;//socket 工厂
final
SSLSocketFactory sslSocketFactory;//安全套层socket工厂 用于https
final
CertificateChainCleaner certificateChainCleaner;//验证确认响应书,适用HTTPS 请求连接的主机名
final HostnameVerifier hostnameVerifier;//主机名字确认
final CertificatePinner certificatePinner;//证书链
final Authenticator proxyAuthenticator;//代理身份验证
final Authenticator authenticator;//本地省份验证
final ConnectionPool connectionPool;//链接池 复用连接
final Dns dns; //域名
final boolean followSslRedirects;//安全套接层重定向
final boolean followRedirects;//本地重定向
final boolean retryOnConnectionFailure;//重试连接失败
final int connectTimeout;//连接超时
final int readTimeout;//读取超时
final int writeTimeout;//写入超时其次是Request
1
2
3
4
5
6
7
8
9String run(String url) throws IOException {
//Request中包含客户请求的参数:url、method、headers、requestBody和tag,也采用了建造者模式。
Request request = new Request.Builder()
.url(url)
.build();
Response response = client.newCall(request).execute();
return response.body().string();
}Call其实是RealCall,其中主要方法是①同步请求:client.newCall(request).execute;②异步请求:client.newCall(request).enqueue(常用)
1
2
3
4
5
6
7
8interface Factory {
Call newCall(Request request);
}
...
public Call newCall(Request request) {
return RealCall.newRealCall(this, request, false /* for web socket */);
}1
2
3
4
5
6
7
8
9
10
11
12
13
14RealCall.java
public void enqueue(Callback responseCallback) {
//TODO 不能重复执行
synchronized (this) {
if (executed) throw new IllegalStateException("Already Executed");
executed = true;
}
captureCallStackTrace();
eventListener.callStart(this);
//TODO 交给 dispatcher调度器 进行调度
client.dispatcher().enqueue(new AsyncCall(responseCallback));
}
/*这里synchronized (this) 确保每个call只能被执行一次不能重复执行,之后Dispatcher 调度器 将 Call 加入队列,并通过线程池执行 Call,在上面的OkHttpClient就已经初始化了Dispatcher*/下面就是Dispatcher了,具体结构原理在后面享学课堂部分写到了
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19//Dispatcher的属性和方法
//TODO 同时能进行的最大请求数
private int maxRequests = 64;
//TODO 同时请求的相同HOST的最大个数 SCHEME :// HOST [ ":" PORT ] [ PATH [ "?" QUERY ]]
//TODO 如 https://restapi.amap.com restapi.amap.com - host
private int maxRequestsPerHost = 5;
/**
* Ready async calls in the order they'll be run.
* TODO 双端队列,支持首尾两端 双向开口可进可出,方便移除
* 异步等待队列
*
*/
private final Deque<AsyncCall> readyAsyncCalls = new ArrayDeque<>();
/**
* Running asynchronous calls. Includes canceled calls that haven't finished yet.
* TODO 正在进行的异步队列
*/
private final Deque<AsyncCall> runningAsyncCalls = new ArrayDeque<>();1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17//TODO 执行异步请求
synchronized void enqueue(AsyncCall call) {
//TODO 同时请求不能超过并发数(64,可配置调度器调整)
//TODO okhttp会使用共享主机即 地址相同的会共享socket
//TODO 同一个host最多允许5条线程通知执行请求
if (runningAsyncCalls.size() < maxRequests &&
runningCallsForHost(call) < maxRequestsPerHost) {
//TODO 加入运行队列 并交给线程池执行
runningAsyncCalls.add(call);
//TODO AsyncCall 是一个runnable,放到线程池中去执行,查看其execute实现
executorService().execute(call);
} else {
//TODO 加入等候队列
readyAsyncCalls.add(call);
}
}
/*可见Dispatcher将Call加入队列中(若同时请求数未超过最大值,则加入运行队列,放到线程池中执行;否则加入等待队列),然后通过线程池执行call。*/executorService() 本质上是一个线程池执行方法,用于创建一个线程池
1
2
3
4
5
6
7
8
9
10
11public synchronized ExecutorService executorService() {
if (executorService == null) {
//TODO 线程池的相关概念 需要理解
//TODO 核心线程 最大线程 非核心线程闲置60秒回收 任务队列
executorService = new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>(), Util.threadFactory("OkHttp Dispatcher",
false));
}
/*使用的是SynchronousQueue作为运行队列,有请求进来就创建线程去执行,这才满足网络请求的要求,高并发并按顺序进行请求*/
return executorService;
}加入线程池中的Call实际是AsyncCall,继承自NamedRunnable类,而NamedRunnable实现Runnable接口,线程池中执行execute()其实就是执行AsyncCall的execute()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29final class AsyncCall extends NamedRunnable {
protected void execute() {
boolean signalledCallback = false;
try {
//TODO 责任链模式
//TODO 拦截器链 执行请求
Response response = getResponseWithInterceptorChain();
//回调结果
if (retryAndFollowUpInterceptor.isCanceled()) {
signalledCallback = true;
responseCallback.onFailure(RealCall.this, new IOException("Canceled"));
} else {
signalledCallback = true;
responseCallback.onResponse(RealCall.this, response);
}
} catch (IOException e) {
if (signalledCallback) {
// Do not signal the callback twice!
Platform.get().log(INFO, "Callback failure for " + toLoggableString(), e);
} else {
eventListener.callFailed(RealCall.this, e);
responseCallback.onFailure(RealCall.this, e);
}
} finally {
//TODO 移除队列
client.dispatcher().finished(this);
}
}
}下面就是拦截器的部分了
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35//TODO 核心代码 开始真正的执行网络请求
Response getResponseWithInterceptorChain() throws IOException {
// Build a full stack of interceptors.
//TODO 责任链
List<Interceptor> interceptors = new ArrayList<>();
//TODO 在配置okhttpClient 时设置的intercept 由用户自己设置
interceptors.addAll(client.interceptors());
//TODO 负责处理失败后的重试与重定向
interceptors.add(retryAndFollowUpInterceptor);
//TODO 负责把用户构造的请求转换为发送到服务器的请求 、把服务器返回的响应转换为用户友好的响应 处理 配置请求头等信息
//TODO 从应用程序代码到网络代码的桥梁。首先,它根据用户请求构建网络请求。然后它继续呼叫网络。最后,它根据网络响应构建用户响应。
interceptors.add(new BridgeInterceptor(client.cookieJar()));
//TODO 处理 缓存配置 根据条件(存在响应缓存并被设置为不变的或者响应在有效期内)返回缓存响应
//TODO 设置请求头(If-None-Match、If-Modified-Since等) 服务器可能返回304(未修改)
//TODO 可配置用户自己设置的缓存拦截器
interceptors.add(new CacheInterceptor(client.internalCache()));
//TODO 连接服务器 负责和服务器建立连接 这里才是真正的请求网络
interceptors.add(new ConnectInterceptor(client));
if (!forWebSocket) {
//TODO 配置okhttpClient 时设置的networkInterceptors
//TODO 返回观察单个网络请求和响应的不可变拦截器列表。
interceptors.addAll(client.networkInterceptors());
}
//TODO 执行流操作(写出请求体、获得响应数据) 负责向服务器发送请求数据、从服务器读取响应数据
//TODO 进行http请求报文的封装与请求报文的解析
interceptors.add(new CallServerInterceptor(forWebSocket));
//TODO 创建责任链
Interceptor.Chain chain = new RealInterceptorChain(interceptors, null, null, null, 0,
originalRequest, this, eventListener, client.connectTimeoutMillis(),
client.readTimeoutMillis(), client.writeTimeoutMillis());
//TODO 执行责任链
return chain.proceed(originalRequest);
}后面是根据责任链的设计模式,按照责任链去递归执行拦截器,当责任链执行完毕,如果拦截器想要拿到最终的数据做其他的逻辑处理等,这样就不用在做其他的调用方法逻辑了,直接在当前的拦截器就可以拿到最终的数据。这也是okhttp设计的最优雅最核心的功能。周执行调度器完成方法,移除队列
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37private <T> void finished(Deque<T> calls, T call, boolean promoteCalls) {
int runningCallsCount;
Runnable idleCallback;
synchronized (this) {
//TODO calls 移除队列
if (!calls.remove(call)) throw new AssertionError("Call wasn't in-flight!");
//TODO 检查是否为异步请求,检查等候的队列 readyAsyncCalls,如果存在等候队列,则将等候队列加入执行队列
if (promoteCalls) promoteCalls();
//TODO 运行队列的数量
runningCallsCount = runningCallsCount();
idleCallback = this.idleCallback;
}
//闲置调用
if (runningCallsCount == 0 && idleCallback != null) {
idleCallback.run();
}
}
private void promoteCalls() {
//TODO 检查 运行队列 与 等待队列
if (runningAsyncCalls.size() >= maxRequests) return; // Already running max capacity.
if (readyAsyncCalls.isEmpty()) return; // No ready calls to promote.
//TODO 将等待队列加入到运行队列中
for (Iterator<AsyncCall> i = readyAsyncCalls.iterator(); i.hasNext(); ) {
AsyncCall call = i.next();
//TODO 相同host的请求没有达到最大,加入运行队列
if (runningCallsForHost(call) < maxRequestsPerHost) {
i.remove();
runningAsyncCalls.add(call);
executorService().execute(call);
}
if (runningAsyncCalls.size() >= maxRequests) return; // Reached max capacity.
}
}1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26//TODO 同步执行请求 直接返回一个请求的结果
/*同步请求就直接交给调度器将Call加入执行队列,然后通过拦截器链通过责任链模式真正进行网络请求,之后完成后移除队列*/
public Response execute() throws IOException {
synchronized (this) {
if (executed) throw new IllegalStateException("Already Executed");
executed = true;
}
captureCallStackTrace();
//TODO 调用监听的开始方法
eventListener.callStart(this);
try {
//TODO 交给调度器去执行
client.dispatcher().executed(this);
//TODO 获取请求的返回数据
Response result = getResponseWithInterceptorChain();//这里就是责任链的开始部分
if (result == null) throw new IOException("Canceled");
return result;
} catch (IOException e) {
eventListener.callFailed(this, e);
throw e;
} finally {
//TODO 执行调度器的完成方法 移除队列
client.dispatcher().finished(this);
}
}
总结
①OkhttpClient 实现了Call.Fctory,负责为Request 创建 Call;
②RealCall 为Call的具体实现,其enqueue() 异步请求接口通过Dispatcher()调度器利用ExcutorService实现,而最终进行网络请求时和同步的execute()接口一致,都是通过 getResponseWithInterceptorChain() 函数实现
③getResponseWithInterceptorChain() 中利用 Interceptor 链条,责任链模式 分层实现缓存、透明压缩、网络 IO 等功能;最终将响应数据返回给用户。
设计模式
建造者模式
创建者模式又叫建造者模式,是将一个复杂的对象的构建与它的表示分离,使得同样的构建过程可以创建不同的表示。创建者模式隐藏了复杂对象的创建过程,它把复杂对象的创建过程加以抽象,通过子类继承或者重载的方式,动态的创建具有复合属性的对象。OkHttp中HttpClient、Request构造便是通过建造者模式
简单工厂模式
okhttp 实现了Call.Factory接口
1
2
3
4
5
6
7
8
9interface Factory {
Call newCall(Request request);
}
//实现Call接口
public Call newCall(Request request) {
return RealCall.newRealCall(this, request, false /* for web socket */);
}责任链模式
责任链模式(Chain of Responsibility Pattern)为请求创建了一个接收者对象的链。这种模式给予请求的类型,对请求的发送者和接收者进行解耦。这种类型的设计模式属于行为型模式。在这种模式中,通常每个接收者都包含对另一个接收者的引用。如果一个对象不能处理该请求,那么它会把相同的请求传给下一个接收者,依此类推。看完只能说设计真的精妙
1
2
3
4
5
6
7
8
9
10public interface Interceptor {
String interceptor(Chain chain);
interface Chain {
String request();
String proceed(String request);
}
}
1
2
3
4
5
6
7
8
9public class BridgeInterceptor implements Interceptor {
public String interceptor(Chain chain) {
System.out.println("执行 BridgeInterceptor 拦截器之前代码");
String proceed = chain.proceed(chain.request());
System.out.println("执行 BridgeInterceptor 拦截器之后代码 得到最终数据:"+proceed);
return proceed;
}
}1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68public class RetryAndFollowInterceptor implements Interceptor {
public String interceptor(Chain chain) {
System.out.println("执行 RetryAndFollowInterceptor 拦截器之前代码");
String proceed = chain.proceed(chain.request());
System.out.println("执行 RetryAndFollowInterceptor 拦截器之后代码 得到最终数据:" + proceed);
return proceed;
}
}
public class CacheInterceptor implements Interceptor {
public String interceptor(Chain chain) {
System.out.println("执行 CacheInterceptor 最后一个拦截器 返回最终数据");
return "success";
}
}
public class RealInterceptorChain implements Interceptor.Chain {
private List<Interceptor> interceptors;
private int index;
private String request;
public RealInterceptorChain(List<Interceptor> interceptors, int index, String request) {
this.interceptors = interceptors;
this.index = index;
this.request = request;
}
public String request() {
return request;
}
public String proceed(String request) {
if (index >= interceptors.size()) return null;
//获取下一个责任链
RealInterceptorChain next = new RealInterceptorChain(interceptors, index+1, request);
// 执行当前的拦截器
Interceptor interceptor = interceptors.get(index);
return interceptor.interceptor(next);
}
}
//测试和结果
List<Interceptor> interceptors = new ArrayList<>();
interceptors.add(new BridgeInterceptor());
interceptors.add(new RetryAndFollowInterceptor());
interceptors.add(new CacheInterceptor());
RealInterceptorChain request = new RealInterceptorChain(interceptors, 0, "request");
request.proceed("request");
//打印出的log
/*执行 BridgeInterceptor 拦截器之前代码
执行 RetryAndFollowInterceptor 拦截器之前代码
执行 CacheInterceptor 最后一个拦截器 返回最终数据
执行 RetryAndFollowInterceptor 拦截器之后代码 得到最终数据:success
执行 BridgeInterceptor 拦截器之后代码 得到最终数据:success
*/
源码解读
ConnectionPool连接池
管理HTTP和SPDY连接的重用,减少网络延迟。连接池是将已经创建好的连接保存在一个缓冲池中,当有请求来时,直接使用已经创建好的连接。
在okhttp中,客户端与服务端的连接被抽象为一个个的Connection,实现类是RealConnection。而ConnectionPool就是专门用来管理Connection的类。ConnectionPool用来管理connections的复用,以减少网络的延迟。一些共享一个地址(Address)的HTTP requests可能也会共享一个Connection。ConnectionPool设置这样的策略:让一些connections保持打开状态,以备将来使用。
OKHttp开源框架学习十:ConnectionPool连接池_okhttp connectionpool-CSDN博客
Route路由:对地址Adress的一个封装类
RouteSelector路由选择器:在OKhttp中其实其作用也就是返回一个可用的Route对象
Platform平台:用于针对不同平台适应性
Call请求(Request\Response):代表实际的http请求,它是连接Request和response的桥梁。由于重写,重定向,跟进和重试,你简单的请求Call可能产生多个请求Request和响应Response。OkHttp会使用Call来模化满足请求的任务,然而中间的请求和响应是必要的(重定向处理和IP出错)
Call执行有两种方式:
Synchronous:线程会阻塞直到响应可读。
Asynchronous:在一个线程中入队请求,当你的响应可读时在另外一个线程获取回调。
线程中的请求取消、失败、未完成,写请求主体和读响应主体代码会遇到IOExceptionDispatchar调度器:Dispatcher是okhttp3的任务调度核心类,负责管理同步和异步的请求,管理每一个请求任务的请求状态,并且其内部维护了一个线程池用于执行相应的请求
1
2
3
4
5
6
7
8
9// Dispatchar内部维护了三个队列
private final Deque<AsyncCall> readyAsyncCalls = new ArrayDeque<>();//等待执行的异步队列
private final Deque<AsyncCall> runningAsyncCalls = new ArrayDeque<>();//正在执行的异步队列
private final Deque<RealCall> runningSyncCalls = new ArrayDeque<>();//同步队列
一个线程池
executorService = new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>(), Util.threadFactory("OkHttp Dispatcher", false));
/*Deque是一个双向队列接口,Deque接口具有丰富的抽象数据形式,它支持从队列两端点检索和插入元素
当需要执行的线程大于所能承受的最大范围时,就把未能及时执行的任务保存在readyAsyncCalls队列中。当线程池有空余线程可以执行时,会调用promoteCall()方法把等待队列readyAsyncCalls中的任务放到线程池执行,并把任务转移到runningAsyncCalls队列中*/Interceptor拦截器:拦截器是一个强大的机制,它可以监控,重写和重试Calls,自带5种拦截器,在享学课堂的OkHttp部分有写,下面的缓存相关部分是缓存拦截器内相关的原理
缓存Cache
Cache来自OkHttpClient
Cache中采用了DiskLruCache,以Request的URL的md5为key,相应Response为value。此外Cache中还通过外观模式对外提供了InternalCache接口变量,用于调用Cache中的方法,也满足面向对象的接口隔离原则和依赖倒置原则等。
DiskLruCache和LruCache内部都是使用了LinkedHashMap去实现缓存算法的,只不过前者针对的是将缓存存在硬盘(/sdcard/Android/data//cache),而后者是直接将缓存存在内存;缓存策略CacheStrategy
CacheStrategy的内部工厂类Factory中有一个getCandidate方法,会根据实际的请求生成对应的CacheStrategy类返回,是个典型的简单工厂模式。其内部维护一个request和response,通过指定request和response来告诉CacheInterceptor是使用缓存还是使用网络请求,亦或两者同时使用。
缓存框架
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78public Response intercept(Chain chain) throws IOException {
// 1.如果设置缓存并且当前request有缓存,则从缓存Cache中获取当前请求request的缓存response
Response cacheCandidate = cache != null
? cache.get(chain.request())
: null;
long now = System.currentTimeMillis();
// 2.传入的请求request和获取的缓存response通过缓存策略对象CacheStragy的工厂类get方法根据一些规则获取缓存策略CacheStrategy(这里的规则根据请求的request和缓存的Response的header头部信息生成的,比如是否有noCache标志位,是否是immutable不可变,缓存是否过期等等)
CacheStrategy strategy = new CacheStrategy.Factory(now, chain.request(), cacheCandidate).get();
// 3.生成的CacheStrategy有2个变量,networkRequest和cacheRequest,如果networkRequest为Null表示不进行网络请求,如果cacheResponse为null,则表示没有有效缓存
Request networkRequest = strategy.networkRequest;
Response cacheResponse = strategy.cacheResponse;
// 4.缓存不可用,关闭
if (cacheCandidate != null && cacheResponse == null) {
closeQuietly(cacheCandidate.body()); // The cache candidate wasn't applicable. Close it.
}
// 5.如果networkRequest和cacheResponse都为Null,则表示不请求网络且缓存为null,返回504,请求失败
if (networkRequest == null && cacheResponse == null) {
return new Response.Builder()
.request(chain.request())
.protocol(Protocol.HTTP_1_1)
.code(504)
.message("Unsatisfiable Request (only-if-cached)")
.body(Util.EMPTY_RESPONSE)
.sentRequestAtMillis(-1L)
.receivedResponseAtMillis(System.currentTimeMillis())
.build();
}
// 6.如果不请求网络,但存在缓存,则不请求网络,直接返回缓存,结束,不执行下一个拦截器
if (networkRequest == null) {
return cacheResponse.newBuilder()
.cacheResponse(stripBody(cacheResponse))
.build();
}
// 7.否则,请求网络,并调用下一个拦截器链,将请求转发到下一个拦截器
Response networkResponse = null;
try {
networkResponse = chain.proceed(networkRequest);
} finally {
// If we're crashing on I/O or otherwise, don't leak the cache body.
if (networkResponse == null && cacheCandidate != null) {
closeQuietly(cacheCandidate.body());
}
}
//8.请求网络,并且网络请求返回HTTP_NOT_MODIFIED,说明缓存有效,则合并网络响应和缓存结果,同时更新缓存
if (cacheResponse != null) {
if (networkResponse.code() == HTTP_NOT_MODIFIED) {
Response response = cacheResponse.newBuilder()
.headers(combine(cacheResponse.headers(), networkResponse.headers()))
.sentRequestAtMillis(networkResponse.sentRequestAtMillis())
.receivedResponseAtMillis(networkResponse.receivedResponseAtMillis())
.cacheResponse(stripBody(cacheResponse))
.networkResponse(stripBody(networkResponse))
.build();
networkResponse.body().close();
// Update the cache after combining headers but before stripping the
// Content-Encoding header (as performed by initContentStream()).
cache.trackConditionalCacheHit();
cache.update(cacheResponse, response);
return response;
} else {
closeQuietly(cacheResponse.body());
}
}
//9.若没有缓存,则写入缓存
Response response = networkResponse.newBuilder()
.cacheResponse(stripBody(cacheResponse))
.networkResponse(stripBody(networkResponse))
.build();
if (cache != null) {
if (HttpHeaders.hasBody(response) && CacheStrategy.isCacheable(response, networkRequest)) {
// Offer this request to the cache.
CacheRequest cacheRequest = cache.put(response);
return cacheWritingResponse(cacheRequest, response);
}
}
return response;
}具流流程如下:
①如果本地没有缓存,直接发送网络请求;cacheResponse == null
如果当前请求是Https,而缓存没有TLS握手,则重新发起网络请求;
request.isHttps() && cacheResponse.handshake() == null
如果当前的缓存策略是不可缓存,直接发送网络请求;
!isCacheable(cacheResponse, request)
请求头no-cache或者请求头包含If-Modified-Since或者If-None-Match,则需要服务器验证本地缓存是不是还能继续使用,直接网络请求;
requestCaching.noCache() || hasConditions(request)
可缓存,并且ageMillis + minFreshMillis < freshMillis + maxStaleMillis(意味着虽过期,但可用,只是会在响应头添加warning),则使用缓存;
缓存已经过期,添加请求头:If-Modified-Since或者If-None-Match,进行网络请求;ConnectInterceptor(核心,连接池)
(下面有部分内容前面有过了)
okhttp的一大特点就是通过连接池来减小响应延迟。如果连接池中没有可用的连接,则会与服务器建立连接,并将socket的io封装到HttpStream(发送请求和接收response)中,HttpCodec(Stream):数据交换的流,对请求的编码以及对响应数据的解码(Stream:基于Connection的逻辑Http请求/响应对),RealConnecton(Collection):Connection实现类,主要实现连接的建立等工作;Http中Stream和Collection关系:Http1(Http1.0)1:1一个连接只能被一个请求流使用Http2(Http1.1)1:n一个连接可被多个请求流同时使用,且keep-alive机制保证连接使用完不关闭,当下一次请求与连接的Host相同时,连接可以直接使用,不用再次创建StreamAllocation(流分配):会通过ConnectPool获取或者创建一个RealConnection来得到一个连接到Server的Connection连接,同时会生成一个HttpCodec用于下一个CallServerInterceptor,以完成最终的请求;RouteDataBase:这是一个关于路由信息的白名单和黑名单类,处于黑名单的路由信息会被避免不必要的尝试;ConnectionPool:连接池,实现连接的复用;
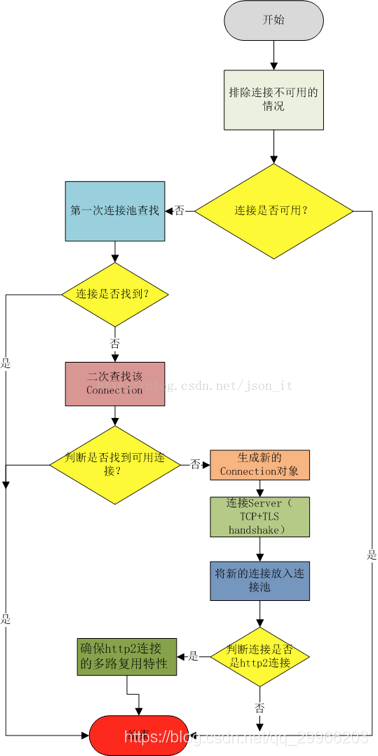
具体源码不看了,直接看步骤
1.框架使用URL和配置好的OkHttpClient创建一个address。此地址指定我们将如何连接到网络服务器。
2.框架通过address从连接池中取回一个连接。
3.如果没有在池中找到连接,ok会选择一个route尝试连接。这通常意味着使用一个DNS请求, 以获取服务器的IP地址。如果需要,ok还会选择一个TLS版本和代理服务器。
4.如果获取到一个新的route,它会与服务器建立一个直接的socket连接、使用TLS安全通道(基于HTTP代理的HTTPS),或直接TLS连接。它的TLS握手是必要的。
5.开始发送HTTP请求并读取响应。
如果有连接出现问题,OkHttp将选择另一条route,然后再试一次。这样的好处是当服务器地址的一个子集不可达时,OkHttp能够自动恢复。而且当连接池过期或者TLS版本不受支持时,这种方式非常有用。
一旦响应已经被接收到,该连接将被返回到池中,以便它可以在将来的请求中被重用。连接在池中闲置一段时间后,它会被赶出。CallServerInterceptor
CallServerInterceptor的intercept()方法里 负责发送请求和获取响应,实际上都是由HttpStream类去完成具体的工作。
一个socket连接用来发送HTTP/1.1消息,这个类严格按照以下生命周期:
1、 writeRequestHeaders()发送request header
httpCodec.writeRequestHeaders(request);
2、打开一个sink来写request body,然后关闭sinkSink requestBodyOut = httpCodec.createRequestBody(request, request.body().contentLength());
3、readResponseHeaders()读取response头部responseBuilder = httpCodec.readResponseHeaders(true);
4、打开一个source来读取response body,然后关闭source
Retrofit
基于Restful风格推出的基于OkHttp的网络请求框架的二次封装的网络请求框架,本质还是OkHttp,通过Http进行网络请求,网络请求的工作本质是OkHttp完成的,Retrofit仅负责网络请求接口的封装。
App应用程序通过 Retrofit 请求网络,实际上是使用 Retrofit 接口层封装请求参数、Header、Url 等信息,之后由 OkHttp 完成后续的请求操作。在服务端返回数据之后,OkHttp 将原始的结果交给 Retrofit,Retrofit根据用户的需求对结果进行解析。
特点
基于OKHttp & 遵循Restful API设计风格
REST,即Representational State Transfer的缩写。直接翻译的意思是”表现层状态转化”。它是一种互联网应用程序的API设计理念:URL定位资源+用HTTP动词描述操作。
常用的HTTP动词有下面五个:
1.GET(SELECT):从服务器取出资源(一项或多项)。
2.POST(CREATE):在服务器新建一个资源。
3.PUT(UPDATE):在服务器更新资源(客户端提供改变后的完整资源)。
4.PATCH(UPDATE):在服务器更新资源(客户端提供改变的属性)。
5.DELETE(DELETE):从服务器删除资源。
REST简单来说就是url地址中只包含名词表示资源,使用http动词表示动作进行操作资源功能强大
支持同步、异步网络请求;
支持多种数据解析方式,包括Gson、Jackson、Simple XML、Protobuf
支持多种网络请求适配器方式,包括guava、Java8、rxjava
RxJava是一个在Java VM上使用可观测的序列来组成异步的、基于事件的程序的库。
虽然,在Android中,我们可以使用AsyncTask来完成异步任务操作,但是当任务的梳理比较多的时候,我们要为每个任务定义一个AsyncTask就变得非常繁琐。
RxJava能帮助我们在实现异步执行的前提下保持代码的清晰。
它的原理就是创建一个Observable来完成异步任务,组合使用各种不同的链式操作,来实现各种复杂的操作,最终将任务的执行结果发射给Observer进行处理。
当然,RxJava不仅适用于Android,也适用于服务端等各种场景。
简单来说,RxJava2.0是非常好用的一个异步链式库,遵循观察者模式。简介易用
通过注解配置网络请求参数;采用大量设计模式简化使用
可扩展性好
功能模块高度封装;解耦彻底:如:自定义Converters
使用
- 注解类型
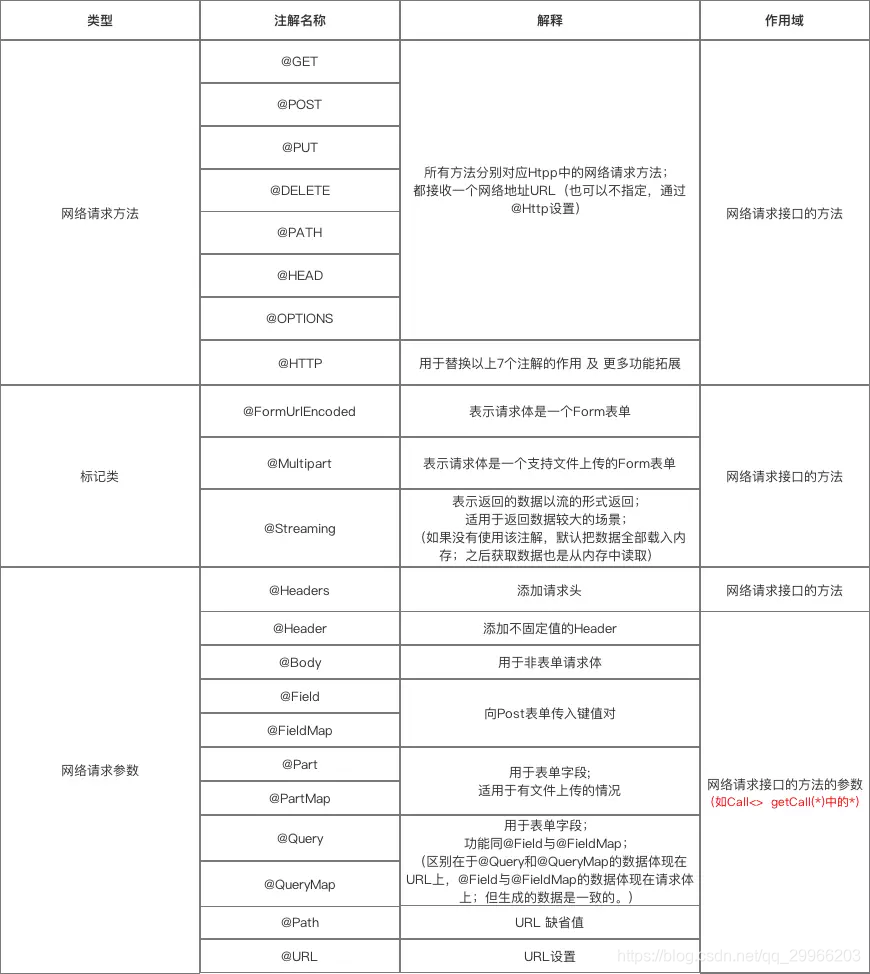
- 流程
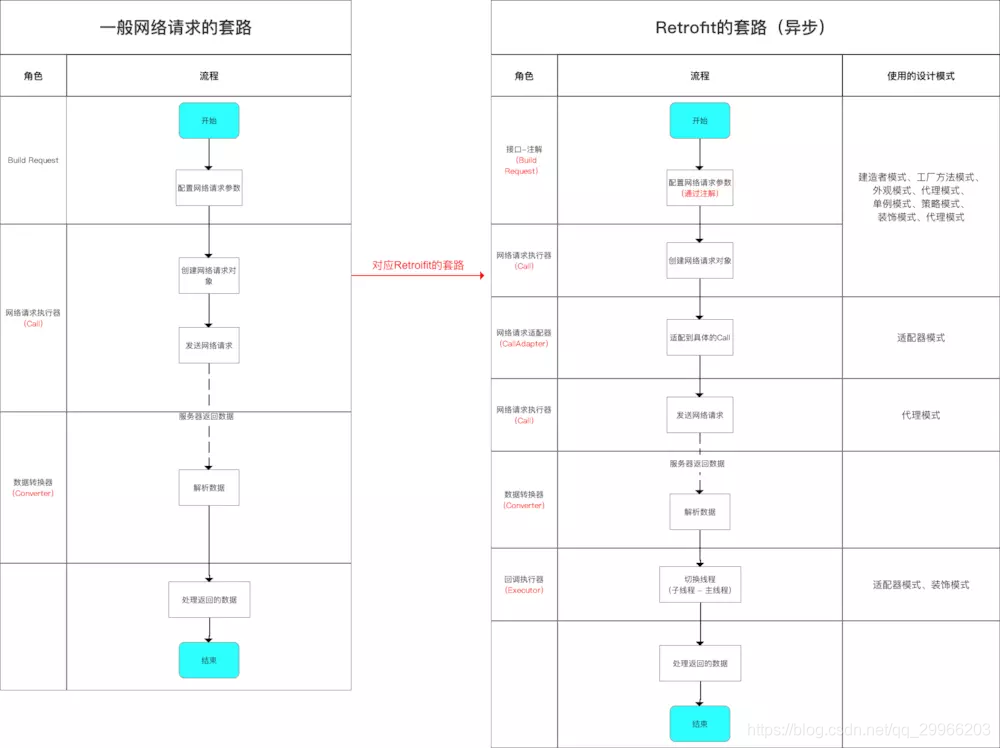
- 具体步骤
添加Retrofit依赖
创建接收服务器返回数据的类(网络请求数据类型)与用于描述网络请求的接口,服务器返回数据的类应根据返回数据的格式和数据解析方式(Json、XML等)定义
1
2
3
4
5
6
7
8
9
10
11
12//Translation为根据服务器返回的数据需要解析成的Java Bean类,不定义可以传入ResponseBody
//用于描述网络请求的接口,采用注解描述网络请求参数和配置网络请求参数
public interface GetRequest_Interface {
Call<Translation> getCall();
// @GET注解的作用:采用Get方法发送网络请求
// getCall() = 接收网络请求数据的方法
// 其中返回类型为Call<*>,*是接收数据的类(即上面定义的Translation类)
// 如果想直接获得Responsebody中的内容,可以定义网络请求返回值为Call<ResponseBody>
}创建Retrofit实例,设置数据解析器(Converter)与网络请求适配器(CallAdapter)
1
2
3
4
5Retrofit retrofit = new Retrofit.Builder()
.baseUrl("http://fanyi.youdao.com/") // 设置网络请求的Url地址
.addConverterFactory(GsonConverterFactory.create()) // 设置数据解析器
.addCallAdapterFactory(RxJavaCallAdapterFactory.create()) // 支持RxJava平台
.build();创建网络请求接口实例并配置网络请求参数
1
2// 创建 网络请求接口 的实例
GetRequest_Interface request = retrofit.create(GetRequest_Interface.class);调用接口方法返回Call对象,并发送异步或同步的网络请求(封装了数据转换和线程切换的操作)
1
2//对 发送请求 进行封装
Call<Reception> call = request.getCall();1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18//发送网络请求(异步)
call.enqueue(new Callback<Translation>() {
//请求成功时回调
public void onResponse(Call<Translation> call, Response<Translation> response) {
//请求处理,输出结果
response.body().show();
}
//请求失败时候的回调
public void onFailure(Call<Translation> call, Throwable throwable) {
System.out.println("连接失败");
}
});
// 发送网络请求(同步)
Response<Reception> response = call.execute();处理服务器返回的数据(Call<*>指定了返回的数据进行解析返回的具体类型,里面可以写Responsebody来获取Responsebody的内容,这就是请求服务器成功获取到数据后进行数据解析后自己再进行处理的逻辑了)
- 重要角色
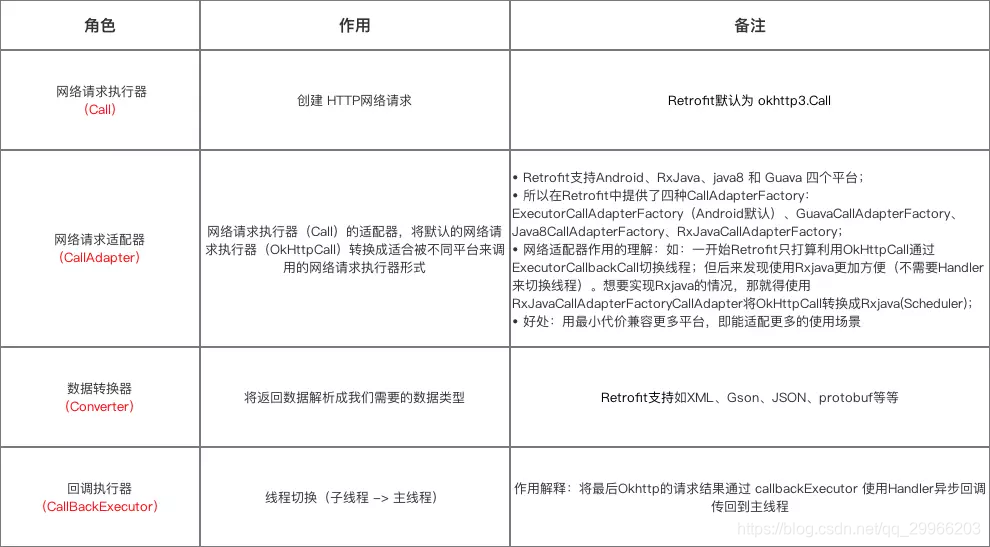
Retrofit源码分析
创建Retrofit实例
Retrofit实例是使用建造者模式通过Builder类创建的。
建造者模式:将一个复杂对象的构建与表示分离,使用户在不知道对象的创建细节情况下就可以直接创建复杂的对象。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50<-- Retrofit类 -->
public final class Retrofit {
private final Map<Method, ServiceMethod> serviceMethodCache = new LinkedHashMap<>();
// 网络请求配置对象(对网络请求接口中方法注解进行解析后得到的对象)
// 作用:存储网络请求相关的配置,如网络请求的方法、数据转换器、网络请求适配器、网络请求工厂、基地址等
private final HttpUrl baseUrl;
// 网络请求的url地址
private final okhttp3.Call.Factory callFactory;
// 网络请求器的工厂
// 作用:生产网络请求器(Call)
// Retrofit是默认使用okhttp
private final List<CallAdapter.Factory> adapterFactories;
// 网络请求适配器工厂的集合
// 作用:放置网络请求适配器工厂
// 网络请求适配器工厂作用:生产网络请求适配器(CallAdapter)
// 下面会详细说明
private final List<Converter.Factory> converterFactories;
// 数据转换器工厂的集合
// 作用:放置数据转换器工厂
// 数据转换器工厂作用:生产数据转换器(converter)
private final Executor callbackExecutor;
// 回调方法执行器,切换线程(子线程-主线程)
private final boolean validateEagerly;
// 标志位
// 作用:是否提前对业务接口中的注解进行验证转换的标志位
<-- Retrofit类的构造函数 -->
Retrofit(okhttp3.Call.Factory callFactory, HttpUrl baseUrl,
List<Converter.Factory> converterFactories, List<CallAdapter.Factory> adapterFactories,
Executor callbackExecutor, boolean validateEagerly) {
this.callFactory = callFactory;
this.baseUrl = baseUrl;
this.converterFactories = unmodifiableList(converterFactories);
this.adapterFactories = unmodifiableList(adapterFactories);
// unmodifiableList(list)近似于UnmodifiableList<E>(list)
// 作用:创建的新对象能够对list数据进行访问,但不可通过该对象对list集合中的元素进行修改
this.callbackExecutor = callbackExecutor;
this.validateEagerly = validateEagerly;
...
// 仅贴出关键代码
}异步请求
设计模式
- Builder模式
- 工厂模式
- 适配器模式
- 代理模式
- 外观模式
- 策略模式
- 观察者模式
RxJava
图片
其他部分
OOM异常:
Android的 OOM 异常_android读取数据库出现oom-CSDN博客
GC机制
Android—GC回收机制与分代回收策略_androidgc回收机制-CSDN博客
加载大图
Android对图片的解码是图片大小等于图片总像素数*每个像素大小,图库里面的图片的分辨率比手机屏幕分辨率高的多,应该将图片压缩和用来展示的控件大小相近,否则会占用内存。
按照缩放比解析位图
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21//1.获取手机的分辨率 获取windowmanager 实例
WindowManager wm = (WindowManager) getSystemService(WINDOW_SERVICE); screenWidth = wm.getDefaultDisplay().getWidth();
screenHeight = wm.getDefaultDisplay().getHeight();
//2.把xxxx.jpg 转换成bitmap
//创建bitmap工厂的配置参数
BitmapFactory.Options options = new Options();
//=true返回一个null 没有bitmap:不去为bitmap分配内存 但是能返回图片的一些信息(宽和高) options.inJustDecodeBounds = true; BitmapFactory.decodeFile("/mnt/sdcard/xxxx.jpg",options);
//3.获取图片的宽和高
int imgWidth = options.outWidth;
int imgHeight = options.outHeight;
//4.计算缩放比
int scalex = imgWidth/screenWidth;
int scaley = imgHeight /screenHeight;
scale =min(scalex, scaley,scale);
//5.按照缩放比显示图片,inSampleSize给图片赋予缩放比,其值大于1时,会按缩放比返回一个小图片用来节省内存
options.inSampleSize = scale;
//6.=false开始真正的解析位图,可显示位图
options.inJustDecodeBounds = false;
Bitmap bitmap = BitmapFactory.decodeFile("/mnt/sdcard/dog.jpg",options);
//7.把bitmap显示到控件上
iv.setImageBitmap(bitmap); } }图片分块加载
图片分块加载在地图绘制上的情况最为明显,当想获取一张尺寸很大的图片的某一块区域时,就用到了图片的分块加载,在Android中BitmapRegionDecoder类的功能就是加载一张图片的指定区域。
LruCache缓存机制
Android的图片三级缓存机制
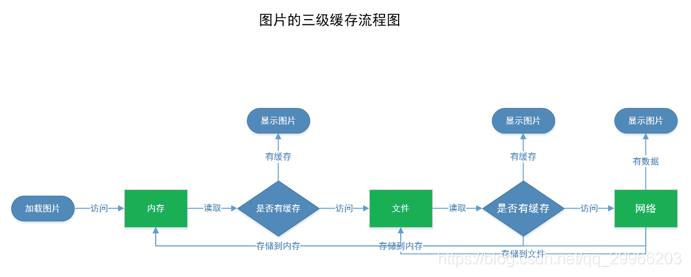
- 第一级:内存LruCache
- 相关介绍
LruCache是android提供的一个缓存工具类,其算法是最近最少使用算法。它把最近使用的对象用“强引用”存储在LinkedHashMap中,并且把最近最少使用的对象在缓存值达到预设定值之前就从内存中移除。
LinkedHashMap:HashMap和双向链表合二为一即是LinkedHashMap。它通过维护一个额外的双向链表保证了迭代顺序。特别地,该迭代顺序可以是插入顺序,也可以是访问顺序。
这里的LinkedHashMap是基于HashMap和双向链表的封装,HashMap是线程不安全的,这里本身是个类,进入put方法会对this指带这个类进行synchronized进行加锁,保证了同步操作
put方法中put成功就对size做减操作,put成功就根据缓存大小整理内存,看是否需要移除LinkedHashMap中的元素,移除过程是进行一个while循环,不断移除LinkedHashMap双向链表表头元素,近期最少使用的数据,直到满足当前缓存大小
get方法是如果该值在缓存中存在或可被创建便返回,当调用LruCache的get()方法获取集合中的缓存对象时,就代表访问了一次该元素,将会更新队列,移动到表尾,这个更新过程就是在LinkedHashMap中的get()方法中完成的。
由重排序可知,对LinkedHashMap的put和get操作,都会让被操作的Entry移动到双向链表的尾部。而移除是从map.entrySet().iterator().next()开始的,也就是双向链表的表头的header的after开始的,这也就符合了LRU算法的需求。
- 具体使用
1 | /* 内存缓存 */ |
- 第二级:文件缓存
存储的路径首先要考虑SD卡的缓存目录,当SD卡不存在时,就只能存到内部存储的缓存目录了。Android新版本内存改变需要注意,现在都使用内存储存
1 | private File getCacheDir() { |
1 | private Bitmap getBitmapFromFile() { |
- 第三级:联网加载
1 | //构建出5条线程的线程池 |
Glide
基本用法
1 | //with(Context/Activity/Fragment)决定Glide加载图片的生命周期 |
图片加载源码分析
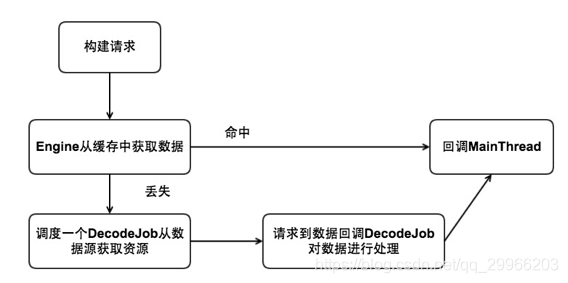
with(Context/Activity/Fragment)
得到一个RequestManager对象(实现request和Activity/Fragment生命周期的关联),Glide再根据传入的with()方法的参数确定图片加载的生命周期:
1、Application类型参数——应用程序生命周期
2、非Application类型参数——Activity/Fragment生命周期load(url)
得到一个DrawableTypeRequest对象(extends DrawableRequestBuilder)
into(imageView)
直接看博客里面吧,写的好乱
缓存机制
- 用法开关
1 | //设置内存缓存开关 |
Glide缓存源码设计思路
内存缓存的操作应该是在异步处理之前,磁盘缓存是耗时操作应该是在异步处理中完成。Glide的内存缓存的读存都在Engine类中完成。
内存缓存使用弱引用(ActiveCache)和LruCache(Cache)结合完成的,弱引用来缓存的是正在使用中的图片。图片封装类Resources内部有个计数器判断是该图片否正在使用。
深入理解Glide的三级缓存机制,优化图像加载 - 知乎 (zhihu.com)
- 内存缓存源码分析
流程
读:先从LruCache取,取不到再从弱引用中取
存;内存缓存取不到,从网络拉取回来先放在弱引用中,渲染图片,图片对象Resources使用计数+1,计数>0表示正在使用;渲染完图片,图片对象Resources使用数-1,如果计数为0表示图片缓存从弱引用中删除,放入LruCache
内存缓存源码分析
- Enfine在加载流程中的入口方法是load,生成一个缓存key,从LruCache中获取缓存图片,获取不到就从弱引用中获取缓存图片,内存缓存不到就进入异步处理
(从内存混存取图片的两个方法loadFromCache()和loadFromActiveResources()。loadFromCache使用的就是LruCache算法,loadFromActiveResources使用的就是弱引用。)
EngineJob是进行异步处理的核心对象,在获取到图片后就会回调Engine的onEngineJobComplete()将正在加载的图片放到弱引用缓存
EngineResource是用一个acquired变量用来记录图片被引用的次数,调用acquire()方法会让变量加1,调用release()方法会让变量减1。当引用计数acquired变量为0,即表示图片使用完,应该放入LruCache中。这里调用了listener.onResourceReleased(key, this);这个listener就是Engine对象。
- 磁盘缓存源码分析
流程
读:先找处理后(result)的图片,没有的话再找原图。
存:先存原图,再存处理后的图。磁盘缓存源码分析
从磁盘缓存读取图片
EngineRunnable的run()方法->decode()方法
将图片存入磁盘缓存
获取图片后存入原图(decodeFromSource())
1
2
3
4
5public Resource<Z> decodeFromSource() throws Exception {
Resource<T> decoded = decodeSource();
return transformEncodeAndTranscode(decoded);
}存入原图
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19private Resource<T> decodeSource() throws Exception {
decoded = decodeFromSourceData(data);
}
private Resource<T> decodeFromSourceData(A data) throws IOException {
final Resource<T> decoded;
if (diskCacheStrategy.cacheSource()) {//设置是否缓存原图
decoded = cacheAndDecodeSourceData(data);
} else {
decoded = loadProvider.getSourceDecoder().decode(data, width, height);
}
return decoded;
}
private Resource<T> cacheAndDecodeSourceData(A data) throws IOException {
SourceWriter<A> writer = new SourceWriter<A>(loadProvider.getSourceEncoder(), data);
//获取DiskCache工具类并写入缓存
diskCacheProvider.getDiskCache().put(resultKey.getOriginalKey(), writer);
Resource<T> result = loadFromCache(resultKey.getOriginalKey());
return result;
}存入处理后的图
1
2
3
4
5
6
7
8
9
10
11private Resource<Z> transformEncodeAndTranscode(Resource<T> decoded) {
Resource<T> transformed = transform(decoded);
writeTransformedToCache(transformed);
Resource<Z> result = transcode(transformed);
return result;
}
private void writeTransformedToCache(Resource<T> transformed) {
SourceWriter<Resource<T>> writer = new SourceWriter<Resource<T>>(loadProvider.getEncoder(), transformed);
diskCacheProvider.getDiskCache().put(resultKey, writer); //获取DiskCache实例并写入缓存
}
框架总结
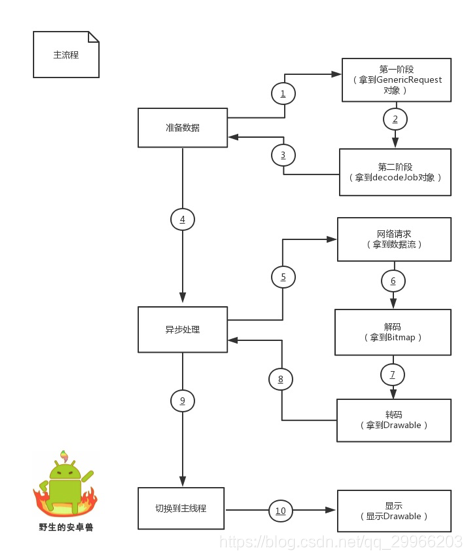
构建GenericRequest对象——Glide配置
构建decodeJob对象——异步处理核心对象
WebView
简介
WebView是一个基于webkit引擎、展现web页面的控件。(Android的Webview在低版本和高版本采用了不同的webkit版本内核,4.4前使用webkit,4.4后直接使用了Chrome。)
- 显示和渲染Web页面
- 直接使用html文件(网络上或本地assets中)作布局
- 可和JavaScript交互调用
由于H5具备 开发周期短、灵活性好 的特点,所以现在 Android App大多嵌入了 Android Webview 组件进行 Hybrid 开发
(移动应用开发的3种方式比较:Native App:本地应用程序(原生App),Web App:网页应用程序(移动web),Hybrid App:混生应用程序(混生App))
Android中的WebView组件,在4.4以前的版本是WebKit的内核,4.4以后才换成chromium的内核,同时鉴于Google版本帝的风格,因此也导致各个版本之间的运行效率参差不齐。而且即使是chromium内核的版本,也因为要考虑兼容以前的版本,而变得不是那么美好。并且内存泄露的问题并没有非常有效的解决方案。
使用
WebView可以单独使用,也可以和工具类一起使用,简单用法
加载url
webView.loadUrl("http://www.google.com/");加载apk包中的html页面
webView.loadUrl("file:///android_asset/test.html");加载手机本地的html页面
webView.loadUrl("content://com.android.htmlfileprovider/sdcard/test.html");加载html的一小段内容
WebView.loadData(String data, String mimeType, String encoding)第一个参数为需要截取展示的内容(内容里不能出现 ’#’, ‘%’, ‘\’ , ‘?’ 这四个字符,若出现了需用 %23, %25, %27, %3f 对应来替代,否则会出现异常);第二个参数为展示内容的类型;第三个参数为字节码
常用工具类
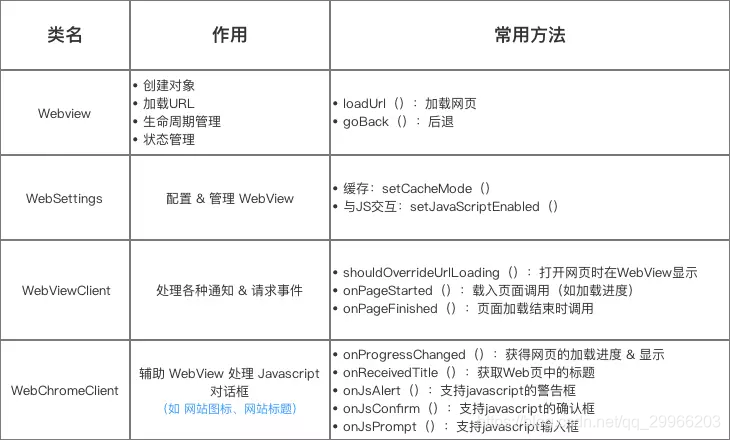
WebSetting类
这个工具类的作用是对webView进行配置和管理,下面是一些具体的配置
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51//声明WebSettings子类
WebSettings webSettings = webView.getSettings();
//如果访问的页面中要与Javascript交互,则webview必须设置支持Javascript
webSettings.setJavaScriptEnabled(true);
// 若加载的 html 里有JS 在执行动画等操作,会造成资源浪费(CPU、电量)
// 在 onStop 和 onResume 里分别把 setJavaScriptEnabled() 给设置成 false 和 true 即可
//支持插件
webSettings.setPluginsEnabled(true);
//设置自适应屏幕,两者合用
webSettings.setUseWideViewPort(true); //将图片调整到适合webview的大小
webSettings.setLoadWithOverviewMode(true); // 缩放至屏幕的大小
//缩放操作
webSettings.setSupportZoom(true); //支持缩放,默认为true。是下面那个的前提。
webSettings.setBuiltInZoomControls(true); //设置内置的缩放控件。若为false,则该WebView不可缩放
webSettings.setDisplayZoomControls(false); //隐藏原生的缩放控件
//其他细节操作
webSettings.setCacheMode(WebSettings.LOAD_CACHE_ELSE_NETWORK); //关闭webview中缓存
webSettings.setAllowFileAccess(true); //设置可以访问文件
webSettings.setJavaScriptCanOpenWindowsAutomatically(true); //支持通过JS打开新窗口
webSettings.setLoadsImagesAutomatically(true); //支持自动加载图片
webSettings.setDefaultTextEncodingName("utf-8");//设置编码格式
//优先使用缓存:
WebView.getSettings().setCacheMode(WebSettings.LOAD_CACHE_ELSE_NETWORK);
//缓存模式如下:
//LOAD_CACHE_ONLY: 不使用网络,只读取本地缓存数据
//LOAD_DEFAULT: (默认)根据cache-control决定是否从网络上取数据。
//LOAD_NO_CACHE: 不使用缓存,只从网络获取数据.
//LOAD_CACHE_ELSE_NETWORK,只要本地有,无论是否过期,或者no-cache,都使用缓存中的数据。
//不使用缓存:
WebView.getSettings().setCacheMode(WebSettings.LOAD_NO_CACHE);
if (NetStatusUtil.isConnected(getApplicationContext())) {
webSettings.setCacheMode(WebSettings.LOAD_DEFAULT);//联网状态,根据cache-control决定是否从网络上取数据。
} else {
webSettings.setCacheMode(WebSettings.LOAD_CACHE_ELSE_NETWORK);//无网状态,则从本地获取,即离线加载
}
webSettings.setDomStorageEnabled(true); // 开启 DOM storage API 功能
webSettings.setDatabaseEnabled(true); //开启 database storage API 功能
webSettings.setAppCacheEnabled(true);//开启 Application Caches 功能
String cacheDirPath = getFilesDir().getAbsolutePath() + APP_CACAHE_DIRNAME;
webSettings.setAppCachePath(cacheDirPath); //设置 Application Caches 缓存目录WebViewClient
处理各种通知&请求事件
- shouldOverrideUrlLoading
- onPageStarted
- onPageFinished
- onLoadResource
- onReceivedError
- onReceivedSslError
WebChronmeClient
具体看博客吧,太多了
辅助 WebView 处理 Javascript 的对话框,网站图标,网站标题等等。
onProgressChanged
onReceivedTitle
onJsAlert/onJsConfirm/onJsPrompt
WebView与JS交互
Android通过WebView调用JS代码
通过WebView的loadUrl()
将js代码以.html格式放到assets文件夹中
1
2
3
4
5
6
7
8
9
10
11
12
13// 设置与Js交互的权限
webSettings.setJavaScriptEnabled(true);
// 设置允许JS弹窗
webSettings.setJavaScriptCanOpenWindowsAutomatically(true);
// 先载入JS代码
// 格式规定为:file:///android_asset/文件名.html,这里文件名为javascript.html
mWebView.loadUrl("file:///android_asset/javascript.html");
// 注意调用的JS方法名要对应上
// 调用javascript的callJS()方法
mWebView.loadUrl("javascript:callJS()");通过WebView的evaluateJavascript()
1
2
3
4
5
6
7
8// 只需要将第一种方法的loadUrl()换成下面该方法即可
mWebView.evaluateJavascript("javascript:callJS()", new ValueCallback<String>() {
public void onReceiveValue(String value) {
//此处为 js 返回的结果
}
});
}
Android 4.4以下使用方法1,Android 4.4以上方法2
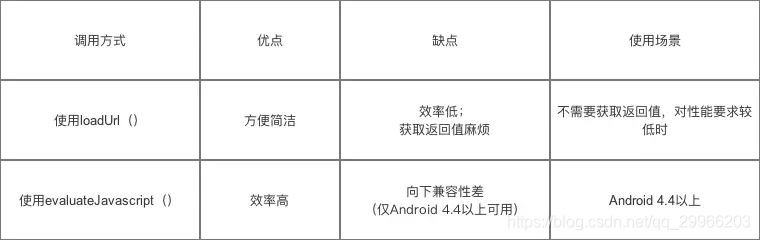
JS通过WebView调用Android代码
具体看博客吧,太多
- 通过 WebView的addJavascriptInterface()进行对象映射
- 通过 WebViewClient 的方法shouldOverrideUrlLoading ()回调拦截 url
- 通过 WebChromeClient 的onJsAlert()、onJsConfirm()、onJsPrompt()方法回调拦截JS对话框alert()、confirm()、prompt() 消息
性能优化
问题
- H5页面加载速度慢,体验跟Native存在很大的差距
- 渲染速度慢,因为JS本身解析过程就很复杂,解析速度慢,并且前端涉及到很多的js文件,叠加起来更慢,并且Android的机型很多,导致手机设备的性能不可控,大部分安卓手机无法达到很好的硬件性能
- 页面加载缓慢,H5页面一般很多并且请求H5页面会产生许多的网络请求,每个网络请求都是串行的,加载速度更加缓慢
- 耗费流量,每次使用H5页面,每加载一个页面都会产生很多的网络请求,很耗费流量
解决方案
前端的缓存机制
其实就是离线缓存,这样在没有网络的时候也可以访问,WebView的本质 = 在 Android中嵌入 H5页面,所以,Android WebView自带的缓存机制其实就是 H5页面的缓存机制。Android WebView除了新的File System缓存机制还不支持,其他都支持。
离线缓存可以让用户在没有网络的时候依然可以对H5页面进行访问;并且这样可以提高网页的加载速度和减少流量的消耗,直接使用已缓存的资源就不需要重新加载
在看缓存机制之前先看缓存模式,WebView缓存模式有下面四种
1
2
3
4
5
6
7
8// 缓存模式说明:
// LOAD_CACHE_ONLY: 不使用网络,只读取本地缓存数据
// LOAD_NO_CACHE: 不使用缓存,只从网络获取数据.
// LOAD_DEFAULT: (默认)根据cache-control决定是否从网络上取数据。
// LOAD_CACHE_ELSE_NETWORK,只要本地有,无论是否过期,或者no-cache,都使用缓存中的数据。
//具体使用
WebView.getSettings().setCacheMode(WebSettings.LOAD_CACHE_ELSE_NETWORK);①缓存机制:浏览器的缓存机制是在Http协议头里面的Cache-Control(或 Expires)和 Last-Modified(或 Etag)等字段来控制文件缓存的机制。(这里可以看网络的Http相关的部分)这个属于浏览器内核机制,Android WebView内置自动实现,即不需要设置即实现。
②上面是浏览器的缓存机制,这里是Application Cache 缓存机制,以文件为单位进行缓存,类似浏览器缓存机制
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17<!DOCTYPE html>
<html manifest="demo_html.appcache">
// HTML 在头中通过 manifest 属性引用 manifest 文件
// manifest 文件:就是上面以 appcache 结尾的文件,是一个普通文件文件,列出了需要缓存的文件
// 浏览器在首次加载 HTML 文件时,会解析 manifest 属性,并读取 manifest 文件,获取 Section:CACHE MANIFEST 下要缓存的文件列表,再对文件缓存
<body>
...
</body>
</html>
// 原理说明如下:
// AppCache 在首次加载生成后,也有更新机制。被缓存的文件如果要更新,需要更新 manifest 文件
// 因为浏览器在下次加载时,除了会默认使用缓存外,还会在后台检查 manifest 文件有没有修改(byte by byte)
发现有修改,就会重新获取 manifest 文件,对 Section:CACHE MANIFEST 下文件列表检查更新
// manifest 文件与缓存文件的检查更新也遵守浏览器缓存机制
// 如用户手动清了 AppCache 缓存,下次加载时,浏览器会重新生成缓存,也可算是一种缓存的更新
// AppCache 的缓存文件,与浏览器的缓存文件分开存储的,因为 AppCache 在本地有 5MB(分 HOST)的空间限制这是专门为web app离线使用而开发的缓存机制,应用场景是存储静态文件,如js、css、字体文件**(AppCache 是对 浏览器缓存机制 的补充,不是替代。)**
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16//具体实现
// 通过设置WebView的settings来实现
WebSettings settings = getSettings();
String cacheDirPath = context.getFilesDir().getAbsolutePath()+"cache/";
settings.setAppCachePath(cacheDirPath);
// 1. 设置缓存路径
settings.setAppCacheMaxSize(20*1024*1024);
// 2. 设置缓存大小
settings.setAppCacheEnabled(true);
// 3. 开启Application Cache存储机制
// 特别注意
// 每个 Application 只调用一次 WebSettings.setAppCachePath() 和WebSettings.setAppCacheMaxSize()③还有Dom Storage 缓存机制,通过存储字符串的 Key - Value 对来提供,DOM Storage 分为 sessionStorage(具备临时性,存储和页面相关的数据,页面关闭后无法使用) & localStorage(具备持久性,保存的数据在页面关闭后也可以使用),使用方法基本相同,不同浏览器的存储空间大小不同,但是简单数据存储在本地就不需要频繁向浏览器发送网络请求,可替代cookies,存储不需要让服务器知道的消息,这个类似Android的SharedPreference机制
1
2
3
4// 通过设置 `WebView`的`Settings`类实现
WebSettings settings = getSettings();
// 开启DOM storage
settings.setDomStorageEnabled(true);④IndexedDB 缓存机制,属于 NoSQL (非关系型数据库)数据库,通过存储字符串的 Key - Value 对来提供,类似于 Dom Storage 存储机制 的key-value存储方式,特点是功能强大,通过数据库事物进行存储,默认250M空间,内存空间较大,适用于存储复杂、数据量大的结构化数据
1
2
3
4
5
6// 通过设置WebView的settings实现
WebSettings settings = getSettings();
settings.setJavaScriptEnabled(true);
// 只需设置支持JS就自动打开IndexedDB存储机制
// Android 在4.4开始加入对 IndexedDB 的支持,只需打开允许 JS 执行的开关就好了。⑤Web SQL Database 缓存机制(不再维护)
⑥File System,这是H5新加入的缓存机制,android webView不支持
缓存机制总结和建议
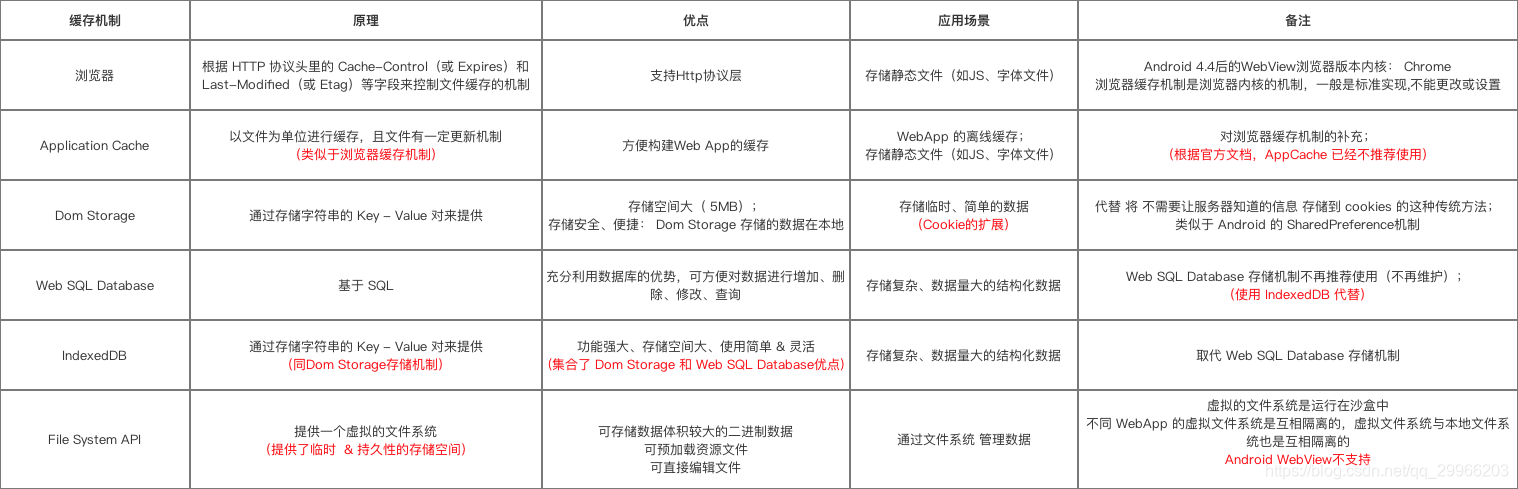
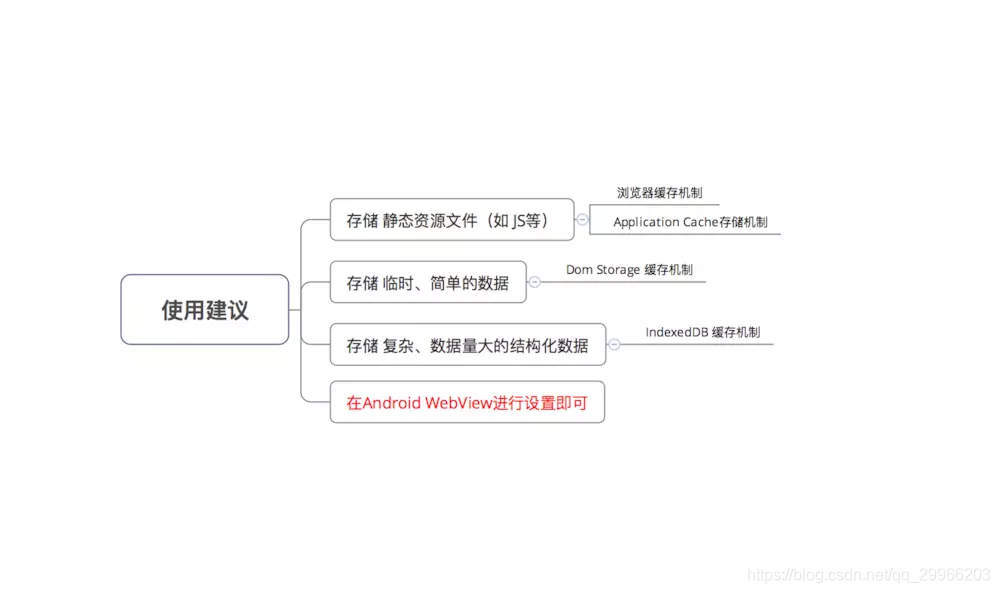
资源预加载
在应用启动、初始化第一个WebView对象时,直接开始网络请求加载H5页面,后续需打开这些H5页面时就直接从该本地对象中获取。
a. 从而 事先加载常用的H5页面资源(加载后就有缓存了)
b. 此方法虽然不能减小WebView初始化时间,但数据请求和WebView初始化可以并行进行,总体的页面加载时间就缩短了;缩短总体的页面加载时间:
具体实现
在Android 的BaseApplication里初始化一个WebView对象(用于加载常用的H5页面资源);当需使用这些页面时再从BaseApplication里取过来直接使用资源拦截(自身构建缓存)
H5页面有一些更新频率低、常用&固定的静态资源文件,如JS、CSS文件、图片等。每次重新加载会浪费很多资源(时间&流量)。可以通过拦截H5页面的资源请求网络,若资源相同,可以直接从本地读取资源而不需发送网络请求到服务器读取。
步骤1:事先将更新频率较低、常用 & 固定的H5静态资源 文件(如JS、CSS文件、图片等) 放到本地
步骤2:拦截H5页面的资源网络请求 并进行检测。(重写WebViewClient 的 shouldInterceptRequest 方法,当向服务器访问这些静态资源时进行拦截)
步骤3:如果检测到本地具有相同的静态资源 就 直接从本地读取进行替换 而 不发送该资源的网络请求 到 服务器获取1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99public class MainActivity extends AppCompatActivity {
WebView mWebview;
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
mWebview = (WebView) findViewById(R.id.webview);
// 创建WebView对象
mWebview.getSettings().setJavaScriptEnabled(true);
// 支持与JS交互
mWebview.loadUrl("http://ip.cn/");
// 加载需要显示的网页
mWebview.setWebViewClient(new WebViewClient() {
// 复写shouldInterceptRequest
//API21以下用shouldInterceptRequest(WebView view, String url)
public WebResourceResponse shouldInterceptRequest(WebView view, String url) {
// 步骤1:判断拦截资源的条件,即判断url里的图片资源的文件名
// 此处网页里图片的url为:http://s.ip-cdn.com/img/logo.gif
// 图片的资源文件名为:logo.gif
if (url.contains("logo.gif")) {
InputStream is = null;
// 步骤2:创建一个输入流
try {
is =getApplicationContext().getAssets().open("images/error.png");
// 步骤3:打开需要替换的资源(存放在assets文件夹里)
// 在app/src/main下创建一个assets文件夹
// assets文件夹里再创建一个images文件夹,放一个error.png的图片
} catch (IOException e) {
e.printStackTrace();
}
// 步骤4:替换资源
WebResourceResponse response = new WebResourceResponse("image/png",
"utf-8", is);
// 参数1:http请求里该图片的Content-Type,此处图片为image/png
// 参数2:编码类型
// 参数3:替换资源的输入流
System.out.println("旧API");
return response;
}
return super.shouldInterceptRequest(view, url);
}
// API21以上用shouldInterceptRequest(WebView view, WebResourceRequest request)
public WebResourceResponse shouldInterceptRequest(WebView view, WebResourceRequest request) {
// 步骤1:判断拦截资源的条件,即判断url里的图片资源的文件名
// 此处图片的url为:http://s.ip-cdn.com/img/logo.gif
// 图片的资源文件名为:logo.gif
if (request.getUrl().toString().contains("logo.gif")) {
InputStream is = null;
// 步骤2:创建一个输入流
try {
is = getApplicationContext().getAssets().open("images/error.png");
// 步骤3:打开需要替换的资源(存放在assets文件夹里)
// 在app/src/main下创建一个assets文件夹
// assets文件夹里再创建一个images文件夹,放一个error.png的图片
} catch (IOException e) {
e.printStackTrace();
}
//步骤4:替换资源
WebResourceResponse response = new WebResourceResponse("image/png",
"utf-8", is);
// 参数1:http请求里该图片的Content-Type,此处图片为image/png
// 参数2:编码类型
// 参数3:存放着替换资源的输入流(上面创建的那个)
return response;
}
return super.shouldInterceptRequest(view, request);
}
});
}
}
总结
加载速度慢,跟Native相比差很远
解析速度慢(在BaseApplication预加载)
消耗流量(缓存,浏览器的缓存机制,不需要手动实现;Application Cache本地文件存储,js,css,字体文件;Dom Storage键值对,存储内容少,Cookice;Index DB非关系型数据库,250M,存储空间大,键值对)(资源拦截,通过回调事件拦截请求的链接中的某些固定资源文件直接从本地替换)
使用漏洞
任意代码执行漏洞
JS调用Android的其中一个方式是通过addJavascriptInterface接口进行对象映射,但是获取到这个对象后就能借助这个对象进行任意代码的运行,可以窃取本地数据,那么就会造成数据的泄密
解决方案1: Android 4.2版本之后
Google 在Android 4.2 版本中规定对被调用的函数以 @JavascriptInterface进行注解从而避免漏洞攻击
解决方案2:Android 4.2版本之前
在Android 4.2版本之前采用拦截prompt()进行漏洞修复。
步骤1:继承 WebView ,重写 addJavascriptInterface 方法,然后在内部自己维护一个对象映射关系的 Map;将需要添加的 JS 接口放入该Map中
步骤2:每次当 WebView 加载页面前加载一段本地的 JS 代码,原理是:
(1)让JS调用一Javascript方法:该方法是通过调用prompt()把JS中的信息(含特定标识,方法名称等)传递到Android端;
(2)在Android的onJsPrompt()中 ,解析传递过来的信息,再通过反射机制调用Java对象的方法,这样实现安全的JS调用Android代码。
关于Android返回给JS的值:可通过prompt()把Java中方法的处理结果返回到Js中
具体需加载的JS代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33javascript:(function JsAddJavascriptInterface_(){
// window.jsInterface 表示在window上声明了一个Js对象
// jsInterface = 注册的对象名
// 它注册了两个方法,onButtonClick(arg0)和onImageClick(arg0, arg1, arg2)
// 如果有返回值,就添加上return
if (typeof(window.jsInterface)!='undefined') {
console.log('window.jsInterface_js_interface_name is exist!!');}
else {
window.jsInterface = {
// 声明方法形式:方法名: function(参数)
onButtonClick:function(arg0) {
// prompt()返回约定的字符串
// 该字符串可自己定义
// 包含特定的标识符MyApp和 JSON 字符串(方法名,参数,对象名等)
return prompt('MyApp:'+JSON.stringify({obj:'jsInterface',func:'onButtonClick',args:[arg0]}));
},
onImageClick:function(arg0,arg1,arg2) {
return
prompt('MyApp:'+JSON.stringify({obj:'jsInterface',func:'onImageClick',args:[arg0,arg1,arg2]}));
},
};
}
}
)()
// 当JS调用 onButtonClick() 或 onImageClick() 时,就会回调到Android中的 onJsPrompt ()
// 我们解析出方法名,参数,对象名
// 再通过反射机制调用Java对象的方法searchBoxJavaBridge_接口引起远程代码执行漏洞;accessibility和 accessibilityTraversal接口引起远程代码执行漏洞
在Android 3.0以下,Android系统会默认通过searchBoxJavaBridge_的Js接口给 WebView 添加一个JS映射对象:searchBoxJavaBridge_对象,该接口可能被利用,实现远程任意代码。
1
2// 通过调用该方法删除接口
removeJavascriptInterface();
密码明文存储漏洞
WebView默认会开启M码保存功能,开启后会提示是否保存密码,但是这个密码是明文保存到本地的数据库中的,就会有密码被窃的风险,只需要关闭这个功能就行
1
mWebView.setSavePassword(false)
域控制不严格漏洞
即 A 应用可以通过 B 应用导出的 Activity 让 B 应用加载一个恶意的 file 协议的 url,从而可以获取 B 应用的内部私有文件,从而带来数据泄露威胁.
对于不需要使用file协议的应用,禁用file协议
1
2
3
4
5// 禁用 file 协议;
setAllowFileAccess(false);
setAllowFileAccessFromFileURLs(false);
setAllowUniversalAccessFromFileURLs(false);对于需要使用file协议的应用,禁止file协议加载js
1
2
3
4
5
6
7
8
9
10
11// 需要使用 file 协议
setAllowFileAccess(true);
setAllowFileAccessFromFileURLs(false);
setAllowUniversalAccessFromFileURLs(false);
// 禁止 file 协议加载 JavaScript
if (url.startsWith("file://") {
setJavaScriptEnabled(false);
} else {
setJavaScriptEnabled(true);
}避免内存泄露
不在xml中定义 WebView ,而是在需要的时候在Activity中创建,并且Context使用 getApplicationgContext()
1
2
3
4
5LinearLayout.LayoutParams params = new LinearLayout.LayoutParams(ViewGroup.LayoutParams.MATCH_PARENT, ViewGroup.LayoutParams.MATCH_PARENT);
mWebView = new WebView(getApplicationContext());
mWebView.setLayoutParams(params);
mLayout.addView(mWebView);在 Activity 销毁( WebView )的时候,先让 WebView 加载null内容,然后移除 WebView,再销毁 WebView,最后置空。
1
2
3
4
5
6
7
8
9
10
11
12
protected void onDestroy() {
if (mWebView != null) {
mWebView.loadDataWithBaseURL(null, "", "text/html", "utf-8", null);
mWebView.clearHistory();
((ViewGroup) mWebView.getParent()).removeView(mWebView);
mWebView.destroy();
mWebView = null;
}
super.onDestroy();
}
状态
webView.onResume() ;
激活WebView为活跃状态,能正常执行网页的响应
webView.onPause();
当页面被失去焦点,被切换到后台不可见状态,需要执行onPause,通过onPause动作通知内核暂停所有的动作,比如DOM的解析、plugin的执行、JavaScript执行。
webView.pauseTimers();
当应用程序(存在webview)被切换到后台时,这个方法不仅仅针对当前的webview而是全局的全应用程序的webview,它会暂停所有webview的layout,parsing,javascripttimer。降低CPU功耗。
webView.resumeTimers();
恢复pauseTimers状态。
rootLayout.removeView(webView);以及webView.destroy();
销毁Webview。在关闭了Activity时,如果Webview的音乐或视频,还在播放。就必须销毁Webview,但是注意:webview调用destory时,webview仍绑定在Activity上,这是由于自定义webview构建时传入了该Activity的context对象。因此需要先从父容器中移除webview,然后再销毁webview。
一些相关的方法
- 关于前进/后退网页
1 | //是否可以后退 |
- 清除缓存数据
1 | //清除网页访问留下的缓存 |
多线程、进程间通信
多线程
- 基础使用
这里主要讲在Android部分的多线程运用,基础看前面的Java部分
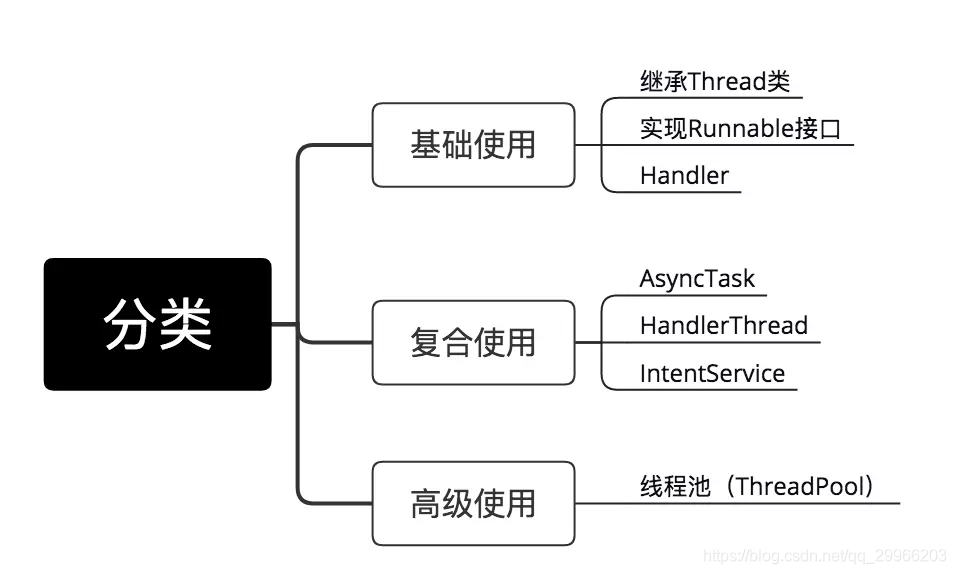
继承Thread和实现Runnable接口的方式前面Java部分有,使用方式一样,这里不写了
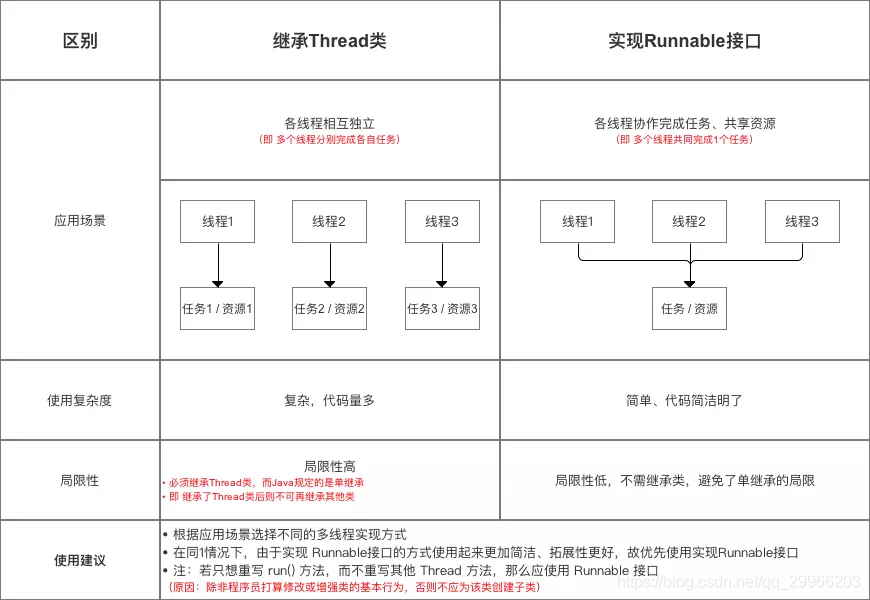
这部分看后面的内容,下面设计到Handler,需要先了解Handler
复合使用
AsyncTask
(已经弃用,Android给出的替代建议是使用java.util.concurrent包下的相关类,如Executor,ThreadPoolExecutor,FutureTask或kotlin并发工具中的协程-Coroutines)
1
2
3public abstract class AsyncTask<Params, Progress, Result> {
...
}不需使用”任务线程(如Thread类)+Handler”复杂组合,方便实现异步通信
采用线程池的缓存线程+复用线程,避免频繁创建&销毁线程所带来的系统资源开销1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72//创建AsyncTask子类
//这里接收三个范型,不使用就用void替代
private class MyTask extends AsyncTask<String, Integer, String> {
// 方法1:onPreExecute()
// 作用:执行 线程任务前的操作
protected void onPreExecute() {
text.setText("加载中");
// 执行前显示提示
}
// 方法2:doInBackground()
// 作用:接收输入参数、执行任务中的耗时操作、返回 线程任务执行的结果
// 此处通过计算从而模拟“加载进度”的情况
protected String doInBackground(String... params) {
try {
int count = 0;
int length = 1;
while (count<99) {
count += length;
// 可调用publishProgress()显示进度, 之后将执行onProgressUpdate()
publishProgress(count);
// 模拟耗时任务
Thread.sleep(50);
}
}catch (InterruptedException e) {
e.printStackTrace();
}
return null;
}
// 方法3:onProgressUpdate()
// 作用:在主线程 显示线程任务执行的进度
protected void onProgressUpdate(Integer... progresses) {
progressBar.setProgress(progresses[0]);
text.setText("loading..." + progresses[0] + "%");
}
// 方法4:onPostExecute()
// 作用:接收线程任务执行结果、将执行结果显示到UI组件
protected void onPostExecute(String result) {
// 执行完毕后,则更新UI
text.setText("加载完毕");
}
// 方法5:onCancelled()
// 作用:将异步任务设置为:取消状态
protected void onCancelled() {
text.setText("已取消");
progressBar.setProgress(0);
}
}
//必须在UI线程创建
MyTask mTask = new MyTask();
//手动调用execute()执行异步线程任务
mTask.execute();AsyncTask不与任何组件绑定生命周期,cancel需要在Activity或Fragment销毁时调用;需要声明为Activity的静态内部类,否则Activity无法回收最后会引起内存泄露;Activity重建时重写onPostExecute()不生效,即无法更新UI操作,在Activity恢复时要重启任务线程
原理
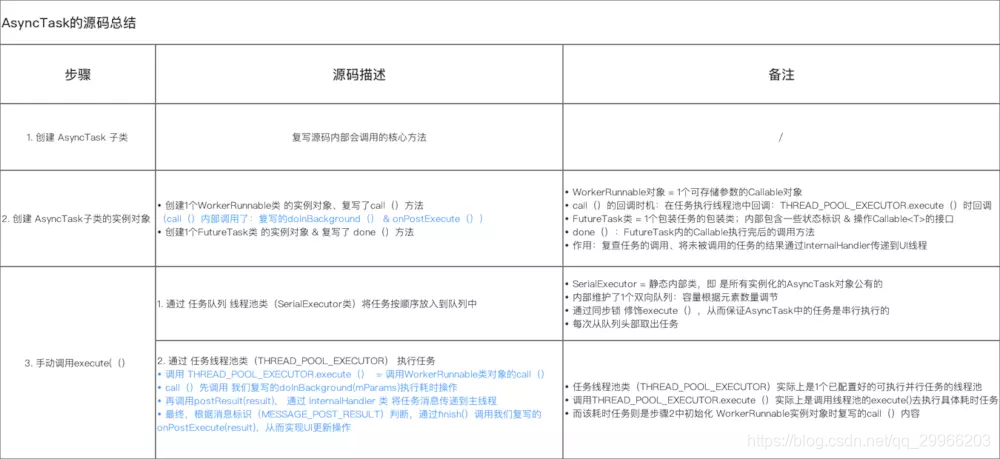
HandlerThread
HandlerThread是一个Android已封装好的轻量级异步类,用于实现多线程(在工作线程中执行耗时任务)及异步通信、消息传递(工作线程&主线程之间通信)从而保证线程安全
HandlerThread本质上是通过继承Thread类和封装Handler类的使用,从而使得创建新线程和与其他线程进行通信变得更加方便易用(不需要使用”任务线程(如继承Thread类)+Handler”复杂组合)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127public class MainActivity extends AppCompatActivity {
Handler mainHandler,workHandler;
HandlerThread mHandlerThread;
TextView text;
Button button1,button2,button3;
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
// 显示文本
text = (TextView) findViewById(R.id.text1);
// 创建与主线程关联的Handler
mainHandler = new Handler();
/**
* 步骤1:创建HandlerThread实例对象
* 传入参数 = 线程名字,作用 = 标记该线程
*/
mHandlerThread = new HandlerThread("handlerThread");
/**
* 步骤2:启动线程
*/
mHandlerThread.start();
/**
* 步骤3:创建工作线程Handler & 复写handleMessage()
* 作用:关联HandlerThread的Looper对象、实现消息处理操作 & 与其他线程进行通信
* 注:消息处理操作(HandlerMessage())的执行线程 = mHandlerThread所创建的工作线程中执行
*/
workHandler = new Handler(mHandlerThread.getLooper()){
// 消息处理的操作
public void handleMessage(Message msg)
{
//设置了两种消息处理操作,通过msg来进行识别
switch(msg.what){
// 消息1
case 1:
try {
//延时操作
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
// 通过主线程Handler.post方法进行在主线程的UI更新操作
mainHandler.post(new Runnable() {
public void run () {
text.setText("我爱学习");
}
});
break;
// 消息2
case 2:
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
mainHandler.post(new Runnable() {
public void run () {
text.setText("我不喜欢学习");
}
});
break;
default:
break;
}
}
};
/**
* 步骤4:使用工作线程Handler向工作线程的消息队列发送消息
* 在工作线程中,当消息循环时取出对应消息 & 在工作线程执行相关操作
*/
// 点击Button1
button1 = (Button) findViewById(R.id.button1);
button1.setOnClickListener(new View.OnClickListener() {
public void onClick(View v) {
// 通过sendMessage()发送
// a. 定义要发送的消息
Message msg = Message.obtain();
msg.what = 1; //消息的标识
msg.obj = "A"; // 消息的存放
// b. 通过Handler发送消息到其绑定的消息队列
workHandler.sendMessage(msg);
}
});
// 点击Button2
button2 = (Button) findViewById(R.id.button2);
button2.setOnClickListener(new View.OnClickListener() {
public void onClick(View v) {
// 通过sendMessage()发送
// a. 定义要发送的消息
Message msg = Message.obtain();
msg.what = 2; //消息的标识
msg.obj = "B"; // 消息的存放
// b. 通过Handler发送消息到其绑定的消息队列
workHandler.sendMessage(msg);
}
});
// 点击Button3
// 作用:退出消息循环
button3 = (Button) findViewById(R.id.button3);
button3.setOnClickListener(new View.OnClickListener() {
public void onClick(View v) {
mHandlerThread.quit();
}
});
}
}原理
内部原理 = Thread类 + Handler类机制
(1)通过继承Thread类,快速创建1个带有Looper对象的新工作线程
(2)通过封装Handler类,快速创建Handler&与其他线程进行通信
源码分析看博客,有些部分在后面享学课堂多线程里面有
问题和解决
连续发消息,点击三下按钮但是不是显示最新的一次操作,而是所有的操作都会进行排队,一个个显示出来,只是因为只开了一个工作线程;
Handler导致内存泄露:当Handler消息队列 还有未处理的消息 / 正在处理消息时,存在引用关系: “未被处理 / 正处理的消息 -> Handler实例 -> 外部类”
若出现 Handler的生命周期 > 外部类的生命周期 时(即 Handler消息队列 还有未处理的消息 / 正在处理消息 而 外部类需销毁时),将使得外部类无法被垃圾回收器(GC)回收,从而造成 内存泄露
解决是:将Handler子类设置为静态内部类+使用weakReference弱引用(如果一个对象只具有弱引用(就是说弱引用指向了某个对象,但只要该对象不是强引用或没有被强引用指向),那么在垃圾回收器线程扫描的过程中,一旦发现了只具有弱引用的对象,不管当前内存空间足够与否,都会回收它的内存。)持有Activity实例
IntentService
Android里的一个封装类,继承四大组件之一Service,用于处理异步请求&实现多线程。线程任务需按顺序、在后台执行。适用于离线下载,不符合多个数据同时请求的场景(所有任务都在同一个Thread looper里执行)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84public class myIntentService extends IntentService {
/**
* 在构造函数中传入线程名字
**/
public myIntentService() {
// 调用父类的构造函数
// 参数 = 工作线程的名字
super("myIntentService");
}
/**
* 复写onHandleIntent()方法
* 根据 Intent实现 耗时任务 操作
**/
protected void onHandleIntent(Intent intent) {
// 根据 Intent的不同,进行不同的事务处理
String taskName = intent.getExtras().getString("taskName");
switch (taskName) {
case "task1":
Log.i("myIntentService", "do task1");
break;
case "task2":
Log.i("myIntentService", "do task2");
break;
default:
break;
}
}
public void onCreate() {
Log.i("myIntentService", "onCreate");
super.onCreate();
}
/**
* 复写onStartCommand()方法
* 默认实现 = 将请求的Intent添加到工作队列里
**/
public int onStartCommand(Intent intent, int flags, int startId) {
Log.i("myIntentService", "onStartCommand");
return super.onStartCommand(intent, flags, startId);
}
public void onDestroy() {
Log.i("myIntentService", "onDestroy");
super.onDestroy();
}
}
public class MainActivity extends AppCompatActivity {
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
// 同一服务只会开启1个工作线程
// 在onHandleIntent()函数里,依次处理传入的Intent请求
// 将请求通过Bundle对象传入到Intent,再传入到服务里
// 请求1
Intent i = new Intent("cn.scu.finch");
Bundle bundle = new Bundle();
bundle.putString("taskName", "task1");
i.putExtras(bundle);
startService(i);
// 请求2
Intent i2 = new Intent("cn.scu.finch");
Bundle bundle2 = new Bundle();
bundle2.putString("taskName", "task2");
i2.putExtras(bundle2);
startService(i2);
startService(i); //多次启动
}
}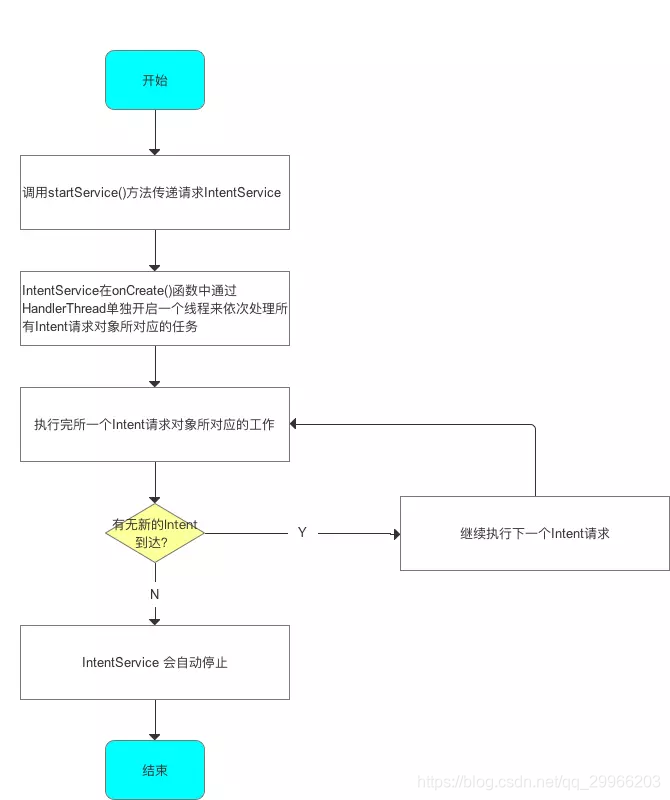
源码分析直接看博客
Handler+HandlerThread
高级使用
线程池部分跟前面Java部分的线程池使用方式一样
synchronized和ThreadLocal直接看博客吧,内容跟前面Java部分使用基本一样的

Java多线程夺命连环60问,逼自己2小时啃完并发多线程面试核心知识点!(JMM、线程池、ThreadLocal、并发锁)_哔哩哔哩_bilibili
Handler
Handler机制是一套Android消息传递机制。在Android开发多线程的应用场景中,将工作线程中需更新UI的操作信息 传递到 UI主线程,从而实现 工作线程对UI的更新处理,最终实现异步消息的处理。
在Android开发中,为了UI操作是线程安全的,规定了只允许主线程更新Activity里的UI组件。但在实际开发中,存在多个线程并发操作UI组件的情况,导致UI操作线程不安全。故采用Handler消息传递机制,是工作线程需更新UI时,通过Handler通知主线程,从而在主线程中更新UI操作。
一些概念(前面内容涉及过的就不列出来了)
Android 的消息机制是基于Handler实现的。Handler 采用的是一种生产者-消费者模型,Handler 就是生产者,通过它可以生产需要执行的任务。而 Looper 则是消费者,不断从 MessageQueue 中取出Message 对这些消息进行消费。
消息(Message):线程间通讯的数据单元(即Handler接受和处理的消息对象),用于存储需要操作的通信信息
下面是获取Message的方法,obtain(效率更高)或直接new
下面是从Message池中取得Message去复用,Message是一个链表结构,默认大小为50,并且永远保存第一个节点就行,然后可以通过Message的next获取到下一个节点


- 消息队列(Message Queue):先进先出的数据结构,存储Handler发过来的Message
- 处理者(Handler):Handler为主线程和子线程的通信媒介,是线程消息都主要处理者,用于添加Message到Message Queue,处理Looper分派过来的Message
- 循环器(Looper):Message Queue和Handler的通信媒介,用于消息循环,分为消息获取(循环取出Message Queue中的Message)和消息分发(将取出的Message发送给Handler)
使用方式
Handler.sendMessage()
继承Handler重写handleMessage方法(在该方法内部执行需要操作的UI操作,这里面的方法是在主线程中运行的)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28// 步骤1:自定义Handler子类(继承Handler类) & 复写handleMessage()方法
class mHandler extends Handler {
// 通过复写handlerMessage() 从而确定更新UI的操作
public void handleMessage(Message msg) {
...// 需执行的UI操作
}
}
// 步骤2:在主线程中创建Handler实例
private Handler mhandler = new mHandler();
// 步骤3:创建所需的消息对象
Message msg = Message.obtain(); // 实例化消息对象
msg.what = 1; // 消息标识
msg.obj = "AA"; // 消息内容存放
// 步骤4:在工作线程中 通过Handler发送消息到消息队列中
// 可通过sendMessage() / post()
// 多线程可采用AsyncTask、继承Thread类、实现Runnable
mHandler.sendMessage(msg);
// 步骤5:开启工作线程(同时启动了Handler)
// 多线程可采用AsyncTask、继承Thread类、实现Runnable
匿名内部类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21// 步骤1:在主线程中 通过匿名内部类 创建Handler类对象
private Handler mhandler = new Handler(){
// 通过复写handlerMessage()从而确定更新UI的操作
public void handleMessage(Message msg) {
...// 需执行的UI操作
}
};
// 步骤2:创建消息对象
Message msg = Message.obtain(); // 实例化消息对象
msg.what = 1; // 消息标识
msg.obj = "AA"; // 消息内容存放
// 步骤3:在工作线程中 通过Handler发送消息到消息队列中
// 多线程可采用AsyncTask、继承Thread类、实现Runnable
mHandler.sendMessage(msg);
// 步骤4:开启工作线程(同时启动了Handler)
// 多线程可采用AsyncTask、继承Thread类、实现Runnable
Handler.post()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16// 步骤1:在主线程中创建Handler实例
private Handler mhandler = new mHandler();
// 步骤2:在工作线程中 发送消息到消息队列中 & 指定操作UI内容
// 需传入1个Runnable对象
mHandler.post(new Runnable() {
public void run() {
... // 需执行的UI操作
}
});
// 步骤3:开启工作线程(同时启动了Handler)
// 多线程可采用AsyncTask、继承Thread类、实现Runnable
工作原理
步骤一:异步通信准备
在主线程中创建
(1)循环器 对象(Looper)
(2)消息队列 对象(Message Queue)
(3)Handler对象
Looper、Message Queue均属于主线程,创建Message Queue后,Looper自动进入消息循环。此时,Handler自动绑定了主线程的Looper、Message Queue步骤二:消息入队
工作线程通过Handler发送消息(Message)到消息队列(Message Queue)中,该消息内容=工作线程对UI的操作步骤三:消息循环
消息出队:Looper循环取出消息队列(Message Queue)中的消息(Message)
消息分发:Looper将去除的消息(Message)发送给创建该消息的处理者(Handler)
在消息循环过程中,若消息队列为空,则线程阻塞。步骤四:消息处理
处理者Handler接受循环器Looper发送过来的消息(Message)
处理者Handler根据消息(Message)进行UI操作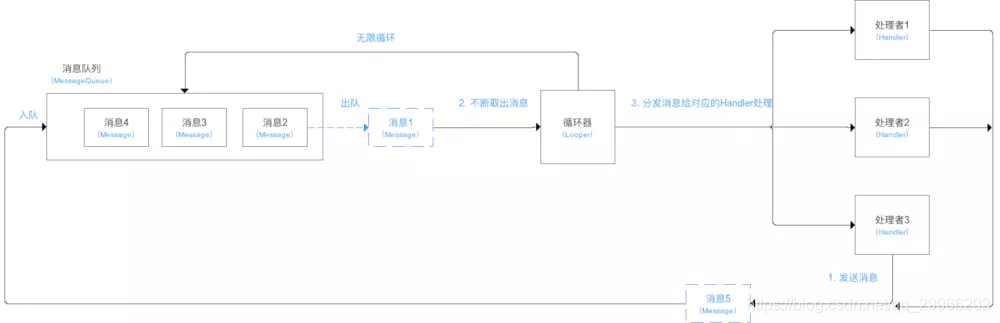
1个线程(Thread)只能绑定1个循环器(Looper),但可以有多个处理者;1个循环器(Looper)可绑定多个处理者(Handler);1个处理者(Handler)只能绑定1个循环器(Looper)
源码分析
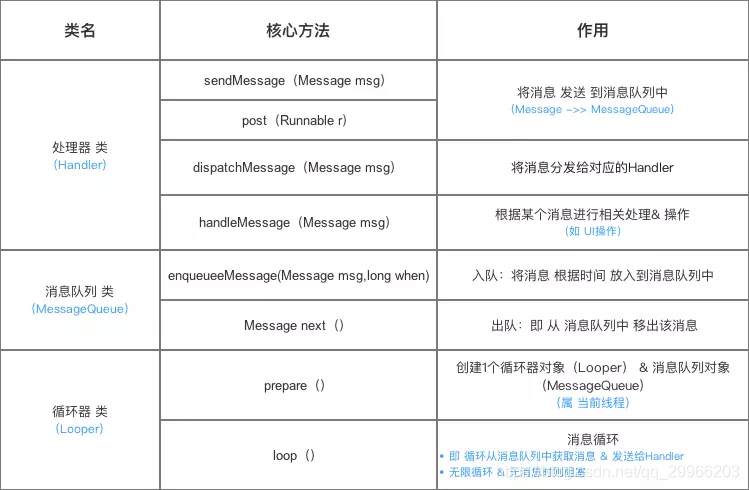
Handler.sendMessage()
创建Looper和MessageQueue
Looper.prepareMainLooper()会为主线程创建一个Looper,同时也会自动创建一个消息队列MessageQueue,这个方法会在主线程创建的时候自动调用,不需要手动生成。
并且在应用进程启动的时候会创建一个主线程(ActivityThread),创建的时候会自动调用ActivityThread的静态的main方法(也就是应用程序的入口),在这个main方法内部会调用Looper.prepareMainLooper()
要为子线程创建一个Looper对象并同时创建一个对应的消息队列(这两一起),就需使用**Looper.prepare()**,在生成Looper和MessageQueue对象后,则会自动进入消息循环,Looper.loop()
消息循环(Looper.loop())
需要注意的是主线程的循环不运行退出,即无限循环;子线程的循环允许退出,调用MessageQueue的quit()方法就可以退出
具体源码直接看博客对应部分
总结
(1)消息循环的操作 = 消息出队 + 分发给对应的Handler实例
(2)分发给对应的Handler的过程:根据出队消息的归属者通过dispatchMessage(msg)进行分发,最终回调复写的handleMessage(Message msg),从而实现 消息处理 的操作
(3)特别注意:在进行消息分发时(dispatchMessage(msg)),会进行1次发送方式的判断:
若msg.callback属性不为空,则代表使用了post(Runnable r)发送消息,则直接回调Runnable对象里复写的run()若msg.callback属性为空,则代表使用了sendMessage(Message msg)发送消息,则回调复写的handleMessage(msg)具体使用过程中如果是使用匿名内部类的方式去使用的,在Handler内部会调用Looper.myLooper();获取当前线程的Looper,并在获取不到Looper的时候抛出异常,当然也可以通过Loop.getMainLooper()获取当前线程的主线程的Looper对象,并绑定获取到Looper的消息队列对象,就是在新new的这个内部类中的成员变量引用获取到的消息队列对象
在sendMessage的背后会先获取消息队列对象,调用enqueueMessage方法将msg.target值赋值为this,后面的msg.target.dispatchMessage(msg)去处理信息,实际则是将该消息派发给对应的Handler执行,之后调用消息队列的enqueueMessage()进行入队(这个队列就是消息队列,内部是使用单链表实现的),有信息就按照创建时间when属性插入,无消息就将其作为对头
总结
Handler发送消息的本质 =
将消息对象的target属性设置为当前Handler实例(将Message绑定到Handler,使执行消息循环时将消息派发给对应的Handler实例)
获取对应的消息队列对象MessageQueue,调用MessageQueue.enqueueMessage(),将Handler需发送消息入队到绑定线程的消息队列中。之后,随着Looper对象的无限消息循环,不断从消息队列中取出Handler发送的消息&根据target分发到对应Handler,最终回调Handler.handleMessage()处理消息
Handler.post()
创建Handler对象
在此之前主线程已经隐式创建Looper对象和MessageQueue对象了,在新建的这个Handler的源码跟前面使用方式的源码类似
在工作线程中发送消息到消息队列
Runnable并无创建新线程,而是发送 消息 到消息队列中,这里的run方法内就可以直接把UI操作写在里面,post方法里面进来就直接执行
return sendMessageDelayed(getPostMessage(r), 0);,这里的getPostMessage(r)是将Runable对象封装成一个消息对象,调用的代码为1
2
3
4
5
6
7
8
9
10
11
12
13private static Message getPostMessage(Runnable r) {
// 1. 创建1个消息对象(Message)
Message m = Message.obtain();
// 注:创建Message对象可用关键字new 或 Message.obtain()
// 建议:使用Message.obtain()创建,
// 原因:因为Message内部维护了1个Message池,用于Message的复用,使用obtain()直接从池内获取,从而避免使用new重新分配内存
// 2. 将 Runable对象 赋值给消息对象(message)的callback属性
m.callback = r;
// 3. 返回该消息对象
return m;
}而sendMessageDelayed(msg, 0)方法的内容为
1
2
3
4
5
6
7
8
9public final boolean sendMessageDelayed(Message msg, long delayMillis)
{
if (delayMillis < 0) {
delayMillis = 0;
}
return sendMessageAtTime(msg, SystemClock.uptimeMillis() + delayMillis);
}其实调用的就是sendMessageAtTime(msg, SystemClock.uptimeMillis() + delayMillis);,内部先获取了消息队列,然后调用enqueueMessage方法,同样将 将msg.target赋值为this,之后调用queue.enqueueMessage(msg, uptimeMillis);保存到消息队列,这部分代码的逻辑跟前面的使用方式的源码很像,只不过这里是对Runable的封装对象进行处理,前面是对Message对象直接进行处理。
内存泄露问题
上述的Handler实例的消息队列有2个分别来自线程1、2的消息(分别 为延迟1s、6s)在Handler消息队列 还有未处理的消息 / 正在处理消息时,消息队列中的Message持有Handler实例的引用,由于Handler = 非静态内部类 / 匿名内部类(2种使用方式),故又默认持有外部类的引用(即MainActivity实例),即 Handler消息队列 还有未处理的消息 / 正在处理消息 而 外部类需销毁时,但是因为引用关系存在,外部类无法呗GC回收,从而造成内存泄露
解决方案就是静态内部类+弱引用或在外部类(Activity)生命周期结束时清空Handler内消息队列
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84public class MainActivity extends AppCompatActivity {
public static final String TAG = "carson:";
private Handler showhandler;
// 主线程创建时便自动创建Looper & 对应的MessageQueue
// 之后执行Loop()进入消息循环
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
//1. 实例化自定义的Handler类对象->>分析1
//注:
// a. 此处并无指定Looper,故自动绑定当前线程(主线程)的Looper、MessageQueue;
// b. 定义时需传入持有的Activity实例(弱引用)
showhandler = new FHandler(this);
// 2. 启动子线程1
new Thread() {
public void run() {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
// a. 定义要发送的消息
Message msg = Message.obtain();
msg.what = 1;// 消息标识
msg.obj = "AA";// 消息存放
// b. 传入主线程的Handler & 向其MessageQueue发送消息
showhandler.sendMessage(msg);
}
}.start();
// 3. 启动子线程2
new Thread() {
public void run() {
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
// a. 定义要发送的消息
Message msg = Message.obtain();
msg.what = 2;// 消息标识
msg.obj = "BB";// 消息存放
// b. 传入主线程的Handler & 向其MessageQueue发送消息
showhandler.sendMessage(msg);
}
}.start();
}
// 分析1:自定义Handler子类
// 设置为:静态内部类
private static class FHandler extends Handler{
// 定义 弱引用实例
private WeakReference<Activity> reference;
// 在构造方法中传入需持有的Activity实例
public FHandler(Activity activity) {
// 使用WeakReference弱引用持有Activity实例
reference = new WeakReference<Activity>(activity); }
// 通过复写handlerMessage() 从而确定更新UI的操作
public void handleMessage(Message msg) {
switch (msg.what) {
case 1:
Log.d(TAG, "收到线程1的消息");
break;
case 2:
Log.d(TAG, " 收到线程2的消息");
break;
}
}
}
}1
2
3
4
5
6
protected void onDestroy() {
super.onDestroy();
mHandler.removeCallbacksAndMessages(null);
// 外部类Activity生命周期结束时,同时清空消息队列 & 结束Handler生命周期
}对于线程安全,通过创建Handler子类的对象,并且每个Activity只需要一个Handler对象,Handler获取信息会判断如何处理,而Runnable则是直接给出处理的方法,队列是依次执行的,Handler会在处理完一个消息或执行完某个处理才会进行下一步,这样不会出现多个线程同时完球进行UI处理而引发混乱现象。
Android 之 Handler_android handler-CSDN博客
详细进阶
消息机制原理
Message源码分析
Handler源码分析
Handler有三个作用,分别是发送消息、处理消息、移除消息
- 发送消息
sendMessage(Message msg),会调用sendMessageDelayed(msg,0);sendEmptyMessage(int what),会调用sendEmptyMessageDelayed(what,0)//发送不带数据的消息内部都是使用
Message.obtain()之后调用sendMessageDelayed(msg, delayMillis),延迟时间小于0也会设为0这内部又是调用
sendMessageAtTime(msg,SystemClock.uptimeMillis()+delayMillis)当前时间+延迟时间这内部就调用
enqueueMessage(queue,msg,uptimeMillis)消息入队,并且保存发送Message的Handler(Message.target=this)- 移除消息
removeMessage(int what)内部调用消息队列的移除方法- 处理消息
handleMessage(Message msg)处理消息的回调方法MessageQueue源码分析
存储消息以message的when排序优先级队列,插入的时候进行比较,看插入到哪个位置
之后调用nativeWake()方法通过本地方法实现对处理等待状态的底层线程,去通知Looper,唤醒
next()方法返回Message,里面也是一个无限循环,nativePollOnce本地方法,会导致可能处于等待状态,这是调用底层方法去完成的,这样不会导致主线程的阻塞
Looper源码分析
主线程的Looper是由Android环境创建的,不需要我们关心
(从MessageQueue中获取当前需要处理的消息,并交给Handler处理)
loop()是核心方法,通过myLooper()得到Looper对象,之后可以通过Looper对象得到Queue对象,内部无限循环for(;;),并没有break,里面调用的是queue.next()来取消息,这就是MessageQueue内部的方法
之后调用msg.target.dispatchMessage(msg)方法调用Handler去分发消息,回到Handler首先判断message的callback是否是空,如果消息可以处理自己就自己处理自己,如果Handler的callback不为空就让回调Handler处理,最后都没有就让Handler的handleMessage来处理
最后调用msg.recycle()回收
消息机制与异步任务
多进程
一个应用运行系统会默认创建一个进程,并且一个应用默认只有一个进程,这个进程就是包名,为了彻底解决主进程占用内存超过内存限制的问题,Android引入多进程的概念,允许同一个应用内,为了分担主进程的压力,将占用内存的某些页面单独开一个进程,比如Flash、视频播放页面、频繁绘制的页面等。
进程等级(下面是按照进程的优先级高低进行排序的)
前台进程Foreground Processes
onResume状态前台可见,正在与用户交互;有BroadcastReceiver正在执行代码;有Service在回调方法中执行代码(这种进程较少,一般作为最后的手段回收内存)
可见进程Visible Processes
没有正在与用户交互但是可以被看见
Activity的onPause状态;调用Service.startForeground()作为前台服务;含有用户意识到特定服务,输入法等等
服务进程Service Processes
进程正在执行后台操作,用户不直接可见的服务组件,比如播放音乐的Service,后台做很多处理(如加载数据)而没有成为前台的应用
缓存/后台进程Background Processes、
该进程包含的组件没有与用户交互,用户也看不到 Service。在一般操作场景下,设备上的许多内存就是用在这上面的,使可以重新回到之前打开过的某个 activity 。
空进程Empty Processes
只是为了缓存的目的而保存,只要Android需要随时可以杀死它
创建线程
Android多进程创建很简单,只需要在AndroidManifest.xml的声明四大组件的标签中增加”android:process”属性即可。命名之后,就成了一个单独的进程。
1 | //私有进程 |
多进程创建好,应用运行时会对进程进行初始化,如果一个application中有多个进程,进行全局初始化时,进程会被初始化多次。此时应该判断当前进程,做相应的初始化操作。
UID机制和共享进程
- UID机制
Pid是进程ID,Uid是用户ID,Android中每个程序都有一个Uid,默认情况下,Android会给每个程序分配一个普通级别互不相同的Uid,如果用互相调用,只能是Uid相同才行,这就使得共享数据具有了一定安全性,每个软件之间是不能随意获得数据的。而同一个application只有一个Uid,所以application下的Activity之间不存在访问权限的问题。
共享进程
一个application中共享service,provider或者activity等数据
1、完全暴露,这就是android:exported=”true”的作用,而一旦设置了intentFilter之后,exported就默认被设置为true了,除非再强制设为false。当然,对那些没有intentFilter的程序体,它的exported属性默认仍然是false,也就不能共享出去。
【Android Activity】IntentFilter的匹配规则_intent-filter data可以有两个么-CSDN博客
2、权限提示暴露,这就是为什么经常要设置usePermission的原因,如果人家设置了android:permission=”xxx.xxx.xx”那么,你就必须在你的application的Manufest中usepermission xxx.xxx.xx才能访问人家的东西。
3、私有暴露,假如说一个公司做了两个产品,只想这两个产品之间可互相调用,那么这个时候就必须使用shareUserID将两个软件的Uid强制设置为一样的。这种情况下必须使用具有该公司签名的签名文档才能,如果使用一个系统自带软件的ShareUID,例如Contact,那么无须第三方签名。通过共享UID,使拥有同一个UID的多个APK可以配置成运行在同一进程中
1、在Manifest节点中增加android:sharedUserId属性。
2、在Android.mk中增加LOCAL_CERTIFICATE的定义。
如果增加了上面的属性但没有定义与之对应的LOCAL_CERTIFICATE的话,APK是安装不上去的。提示错误是:Package com.test.MyTest has no signatures that match those in shared user android.uid.system; ignoring!也就是说,仅有相同签名和相同sharedUserID标签的两个应用程序签名都会被分配相同的用户ID。例如所有和media/download相关的APK都使用android.media作为sharedUserId的话,那么它们必须有相同的签名media。
3、把APK的源码放到packages/apps/目录下,用mm进行编译。
多进程通信IPC
IPC就是进程间通信
Binder
定义
Linux内核基础知识
(1)用户空间/内核空间
用户空间指的是用户程序所运行的空间,内核空间是 Linux 内核的运行空间,为了安全,它们是隔离的,即使用户的程序崩溃了,内核也不受影响。
(2)系统调用——用户空间访问内核空间
用户空间访问内核空间的唯一方式就是系统调用;通过这个统一入口接口,所有的资源访问都是在内核的控制下执行,以免导致对用户程序对系统资源的越权访问,从而保障了系统的安全和稳定。
(3)Binder驱动——用户空间A访问用户空间B
在 Android 系统中,这个运行在内核空间的,负责各个用户进程通过 Binder 通信的内核模块叫做 Binder 驱动。
Binder的定义
(1)用户空间/内核空间
用户空间指的是用户程序所运行的空间,内核空间是 Linux 内核的运行空间,为了安全,它们是隔离的,即使用户的程序崩溃了,内核也不受影响。
(2)系统调用——用户空间访问内核空间
用户空间访问内核空间的唯一方式就是系统调用;通过这个统一入口接口,所有的资源访问都是在内核的控制下执行,以免导致对用户程序对系统资源的越权访问,从而保障了系统的安全和稳定。
(3)Binder驱动——用户空间A访问用户空间B
在 Android 系统中,这个运行在内核空间的,负责各个用户进程通过 Binder 通信的内核模块叫做 Binder 驱动。
优势
1)性能方面
在移动设备上(性能受限制的设备,比如要省电),广泛地使用跨进程通信对通信机制的性能有严格的要求,Binder相对于传统的Socket方式,传输效率高、开销小。Binder数据拷贝只需要一次,而管道、消息队列、Socket都需要2次;共享内存方式虽然一次内存拷贝都不需要,但控制复杂,难以使用。
(2)安全方面传统的进程通信方式对于通信双方的身份并没有做出严格的验证,使用传统IPC只能由用户在数据包里填入UID/PID,这样不可靠,容易被恶意程序利用。可靠的身份标记只有由IPC机制本身在内核中添加。比如Socket通信ip地址是客户端手动填入,很容易进行伪造,而Binder机制从协议本身就支持对通信双方做身份校检,因而大大提升了安全性。
(3)实现面象对象的调用方式
在使用Binder时就和调用一个本地实例一样。C/S通信方式
Binder使用Client-Server通信方式:一个进程作为Server提供诸如视频/音频解码,视频捕获,地址本查询,网络连接等服务;多个进程作为Client向Server发起服务请求,获得所需要的服务。
要想实现Client-Server通信据必须实现以下两点:
一是server必须有确定的访问接入点或者说地址来接受Client的请求,并且Client可以通过某种途径获知Server的地址;
二是制定Command-Reply协议来传输数据。Binder可以看成Server提供的实现某个特定服务的访问接入点, Client通过这个‘地址’向Server发送请求来使用该服务;对Client而言,Binder可以看成是通向Server的管道入口,要想和某个Server通信首先必须建立这个管道并获得管道入口。遍布于Client中的入口可以看成指向这个Binder对象的‘指针’,一旦获得了这个‘指针’就可以调用该对象的方法访问Server。
通信模型
Binder框架定义了四个角色:Server,Client,ServiceManager(以后简称SMgr)以及Binder驱动。其中Server,Client,SMgr运行于用户空间,驱动运行于内核空间。
理解:这四个角色和互联网类似:Server是服务器,Client是客户终端,SMgr是域名服务器(DNS),Binder驱动是路由器。和电话类似:Client给Server打电话,SMgr是通讯录,Binder是电话基站。Binder驱动
驱动负责进程之间Binder通信的建立,Binder在进程之间的传递,Binder引用计数管理,数据包在进程之间的传递和交互等一系列底层支持。
ServiceManager进程(守护进程,用来管理Server)
ServiceManager的作用是将字符形式的Binder名字转化成Client中对该Binder的引用,使得Client能够通过Binder名字获得对Server中Binder实体的引用。
Sever进程
Server创建了Binder实体,为其取一个字符形式,可读易记的名字,将这个Binder连同名字以数据包的形式通过Binder驱动发送给SMgr,通知SMgr注册一个名叫张三的Binder,它位于某个Server中。驱动为这个穿过进程边界的Binder创建位于内核中的实体节点以及SMgr对实体的引用,将名字及新建的引用打包传递给SMgr。SMgr收数据包后,从中取出名字和引用填入一张查找表中。
Client进程
Server向SMgr注册了Binder实体及其名字后,Client就可以通过名字获得该Binder的引用了。Client也利用保留的0号引用向SMgr请求访问某个Binder:我申请获得名字叫张三的Binder的引用。SMgr收到这个连接请求,从请求数据包里获得Binder的名字,在查找表里找到该名字对应的条目,从条目中取出Binder的引用,将该引用作为回复发送给发起请求的Client。
工作流程
步骤1:ServiceManager内维护了一张表,表存储着向他注册过的进程信息
在通信之初,首先需要有一个进程向驱动申请成为ServerManager,当内核驱动同意之后,这个成为ServerManager的进程就负责管理所有需要通信的进程信息步骤2:服务端进程向ServerManager注册信息
服务端进程首先会向ServerManager注册一张表,这个表中就存储了相关信息,告诉ServerManager我这里有一个返回值为Object的add方法,步骤3:客户端进程向ServerManager取得信息,通过Binder驱动与服务端进程通信
当ServerManger保存完毕后,客户端进程就会通过Binder驱动向ServerManger查询服务端进程的信息,ServerManage就会将服务端进程的信息返回给客户端进程,客户端与服务端进程之间就可以通过这些信息,利用Binder驱动来进行通信
AIDL
AIDL(Android Interface Define Language) 是IPC进程间通信方式的一种.用于生成可以在Android设备上两个进程之间进行进程间通信(interprocess communication, IPC)的代码.
Binder 与AIDL_aidl与binder的区别-CSDN博客
其他的先空着,后面再看
使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19//service
public class IRemoteService extends Service {
//客户端绑定service时会执行
public IBinder onBind(Intent intent) {
return iBinder;
}
private IBinder iBinder = new IImoocAIDL.Stub(){
public int add(int num1, int num2) throws RemoteException {
Log.e("TAG","收到了来自客户端的请求" + num1 + "+" + num2 );
return num1 + num2;
}
};
}1
2
3
4
5
6
7
8//AndroidMainfest.xml
<service android:name=".IRemoteService"
android:process=":remote"
android:exported="true">
<intent-filter>
<action android:name="com.mecury.aidltest.IRomoteService"/>
</intent-filter>
</service>1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74//client 客户端绑定服务并调用服务端的方法
public class MainActivity extends AppCompatActivity implements View.OnClickListener {
private EditText num1;
private EditText num2;
private Button button;
private TextView text;
private IImoocAIDL iImoocAIDL;
private ServiceConnection conn = new ServiceConnection() {
//绑定服务,回调onBind()方法
public void onServiceConnected(ComponentName name, IBinder service) {
iImoocAIDL = IImoocAIDL.Stub.asInterface(service);
}
public void onServiceDisconnected(ComponentName name) {
iImoocAIDL = null;
}
};
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
bindService();
initView();
}
private void initView() {
num1 = (EditText) findViewById(R.id.num1);
num2 = (EditText) findViewById(R.id.num2);
button = (Button) findViewById(R.id.button);
text = (TextView) findViewById(R.id.text);
button.setOnClickListener(this);
}
public void onClick(View v) {
int num11 = Integer.parseInt(num1.getText().toString());
int num22 = Integer.parseInt(num2.getText().toString());
try {
int res = iImoocAIDL.add(num11,num22);
text.setText(num11 +"+"+ num22 +"="+ res);
} catch (RemoteException e) {
e.printStackTrace();
}
}
private void bindService() {
Intent intent = new Intent();
//绑定服务端的service
intent.setAction("com.mecury.aidltest.IRomoteService");
//新版本(5.0后)必须显式intent启动 绑定服务
intent.setComponent(new ComponentName("com.mecury.aidltest","com.mecury.aidltest.IRemoteService"));
//绑定的时候服务端自动创建
bindService(intent,conn, Context.BIND_AUTO_CREATE);
}
protected void onDestroy() {
super.onDestroy();
unbindService(conn);
}
}
Messenger
使用Messenger为服务提供接口,让服务与远程进程通信。利用Handler实现。(适用于多进程、单线程,不需要考虑线程安全),其底层基于AIDL。
1 | //server |
1 | //AndroidManifest.xml |
1 | //client |
AIDL与Messenger、Binder区别
Using AIDL is necessary only if you allow clients from different applications to access your service for IPC and want to handle multithreading in your service. If you do not need to perform concurrent IPC across different applications, you should create your interface by implementing a Binder or, if you want to perform IPC, but do not need to handle multithreading, implement your interface using a Messenger. Regardless, be sure that you understand Bound Services before implementing an AIDL.
(1)只有当你允许来自不同的客户端访问你的服务并且需要处理多线程问题时你才必须使用AIDL
(2)如果进程间的通信来自同一应用,应该使用Binder
(3)如果进程间的通信不需要处理多线程,应该使用Messenger
a.Messenger不适用大量并发的请求:Messenger以串行的方式来处理客户端发来的消息,如果大量的消息同时发送到服务端,服务端仍然只能一个个的去处理。
b.Messenger主要是为了传递消息:对于需要跨进程调用服务端的方法,这种情景不适用Messenger。
c.Messenger的底层实现是AIDL,系统为我们做了封装从而方便上层的调用。
d.AIDL适用于大量并发的请求,以及涉及到服务端端方法调用的情况
详细进阶
- 为什么要问Binder
Android的进程间通信使用的就是Binder,Binder就是Android中的血管,在Android中我们使用到的Activity,Service等组件都需要和AMS(system_server)通信(Activity和AMS服务其实是在不同进程的),这种跨进程都是通过Binder完成的。
机制:Binder是一种进程间通信机制;驱动:Binder是一个虚拟物理设备驱动;应用层:Binder是一个能发起通信的Java类 (那么一个Java类要能够进行进程间通信就需要继承自Binder)

小项目是一个进程打天下的,但是多进程是有很多使用场景和优势的,微信、QQ、微博等都是多进程在运行,那么稍微大一点的公司面试就很看重这里,因为只使用单进程的应用性能是比较差劲的
虚拟机分配给各个进程的运行内存是有限制的、LMK也会优先回收对系统资源占用多的进程,那么使用多进程就可以:①突破进程的内存限制,如图库占用内存过多;②在功能稳定性方面,独立的通信进程保持长连接的稳定性;③可以规避系统内存的泄露,独立的WebView进程阻隔内存泄露导致的问题(推送、WebView);④隔离风险,对于不稳定功能放如独立进程,避免导致主进程崩溃。。。
- Binder优势
首先需要了解一个Linux的机制,有管道、信号量、共享内存、socket; Binder是android创造使用的,现在被Linux接受,现在Linux自带Binder机制

共享内存的性能是最好的,Binder次之,其他IPC更慢;共享内存共享同一块内存和变量,需要考虑很多问题,如死锁、数据不同步等等,使用是很不方便的;传统IPC如何知道进程的身份,就需要服务发送id给系统,这个id是自己发的,不安全,而Binder会为每个App分配一个UID(唯一),传统IPC接入点是开放的,那么谁都可以进行访问,而Binder支持实名和匿名(正常情况下,系统服务是实名的,个人服务是匿名的,在ServiceManager注册的就是实名的,那么如果个人服务也去注册就是实名的)
- Binder一次拷贝
进程间通信和线程间通信不同,主要就是内存机制不同,线程通信是共享内存的,但是进程间的内存是隔离的
(内存划分:内存被操作系统划分成两块,为用户空间和内核空间,用户空间是用户程序代码运行的地方,内核空间是内核代码运行的地方。为了安全,他们是隔离的,即使用户的程序崩溃了,内核也不受影响;不同进程之间的用户空间也是隔离的)
(平时所说的内存都是虚拟内存,物理内存就是硬件)
那么在内核空间是需要将虚拟内存的内容映射到物理内存,所有内核空间是映射在同一块物理内存上的,其实就是内存共享(内核空间可以理解成地球仪,但是物理内存就可以看成是地球)
看到这里就知道怎么共享内存了。进程1的内容要共享给进程2,那么就可以将内容放到自己的内核空间就行,内核空间自己会映射到物理内存,那么其他进程的内核空间也可以访问到,进程2就可以通过自己的内核空间访问到进程2的内容了(数据传递的原理,进程间通信达原理)
下面就是以前的数据传输(传统 )


结合上面的现代快递(丰巢)机制,理解Binder机制,就不需要进行两次拷贝,只需要接收方的内核空间和用户空间指向同一块物理内存即可,那么就不需要内核空间拷贝到接收方的具体进程地址空间(而这个公共的物理内存就是由Binder驱动提供的)

- MMAP的原理讲解
上面接收方如何进行映射同一块内存空间的就需要MMAP,MMAP原理
在 Android 中,Binder 通信机制中使用了 mmap(Memory Map)技术,用于实现进程间的共享内存。mmap 是一种内存映射文件的方式,可以将一个文件或者设备映射到进程地址空间的一段连续的地址区域中,这样就能够让多个进程共享同一块物理内存。
在 Binder 通信中,服务端和客户端通过 mmap 映射同一块物理内存来传递数据。具体来说,当客户端请求服务端获取数据时,服务端将需要传递的数据复制到共享内存区域,并返回共享内存区域的描述符给客户端。客户端接收到该描述符后可以通过 mmap 将其映射到自己的地址空间中,从而访问共享内存中的数据。
使用 mmap 技术的好处是,避免了数据的多次拷贝,提高了数据传输的效率,同时也避免了由于多次复制数据引起的内存浪费和性能损耗。
需要注意的是,mmap 机制只能用于 Linux 系统下的进程通信,而对于跨平台通信,需要使用其他的机制来进行实现。

原本用户空间访问磁盘和写入的逻辑如下

(那么共享内存的无需拷贝就是减少发送方的拷贝,减少的机制是一样的)
在客户端向服务端发送数据时,需要进行数据拷贝的操作如下:
1.客户端将需要传递的数据(比如字符串 “Hello, world!”)存储到自己的内存空间中。
2.客户端将自己的内存空间中的数据拷贝到该共享内存区域中。
3.客户端获取共享内存区域的描述符,并将该描述符通过 Binder 传递给服务端。
在第二步中,客户端需要将自己内存空间中的数据拷贝到共享内存区域中,这一过程需要进行一次数据的拷贝。具体来说,客户端会调用类似于 memcpy 这样的函数,将自己内存空间中的数据拷贝到共享内存区域中。这个过程类似于文件拷贝或者网络传输等操作,都涉及到数据的拷贝操作。
而在服务端接收到共享内存描述符之后,无需再进行数据的拷贝。服务端可以直接通过 mmap 函数将共享内存区域映射到自己的地址空间中,从而可以直接访问共享内存中的数据。因为共享内存区域已经与客户端进程、服务端进程进行了关联,所以服务端可以直接访问共享内存区域中的数据,而不需要进行数据的拷贝。
-
- Binder机制如何跨进程的
这部分就是归纳总结前面的部分,Binder一次拷贝和MMAP
copy_from_user()拷贝数据到内核地址空间,映射同一块物理内存就可以访问同一块内容
- AIDL生成Java类的细节
一文分析Binder机制和AIDL的理解 - 知乎 (zhihu.com)
AIDL是Android接口描述语言(跨进程通信有自己的规则,当然我们也可以按照这个规则自己去写,但是很麻烦,AIDL就是简化这个流程并且防止出错,具体写法可以看上面博客,AIDL就可以理解为一个工具)
stub asinterface proxy(同进程不需要使用,不同进程需要使用)
那么AIDL生成的代码是怎么进行处理具体逻辑的,stub的asinterface会判断是否是当前当前进程的服务,不是就会封装一层proxy再返回(而proxy继承Binder,最后也是获取到Binder,之后asInterface封装成接口),是就直接返回接口,那么就可以直接通过接口进行数据传输和各种操作,proxy中就是AIDL自动生成的代码,这里以一个接口的一个操作具体讲怎么实现,首先会准备两个Parcel对象,命名为data和reply,data就是客户端给服务端的数据,reply就是服务端给客户端的数据,通过Remote(就是Binder,那这里就不需要手动去写这里了,proxy自动去完成具体的了)的transact(可以设置同步和异步的),之后就是framework和kernel层的事情了(transact执行后客户端会挂起,可以通过flags参数是同步还是异步)

服务端需要new Stub()并重写里面的方法,将内容返回给客户端

这里的onTransact会按照code的不同判断调用哪个方法,是客户端给服务端传数据还是服务端给客户端传数据。。。
- 四大组件底层的通信机制
可以联想到Service,但是bindService后回调到ServiceConnection,这之间做了什么事情

那么就需要找到AMS服务,需要用到服务管理类,ServiceManager,这个看前面就行,有写,就是把服务的名字和id进行关联,只需要知道名字就能找到对应的服务,ServiceManager的id固定为0,(请求ServiceManager这里也是跨进程的)

没看完,有空再看了
8.为什么Intent不能传递大数据_batch_哔哩哔哩_bilibili
架构
一篇文章讲清楚Android中的MVC、MVP、MVVM架构 (附实现代码)_android mvc mvp mvvm-CSDN博客
MVC架构
- View: 视图层,对应xml文件
- Controller: 控制层,对应Activity和Fragme nt层,进行数据处理
- Model:实体层,负责获取实体数据

在Android语境下,这里的Controller一般特指Activity和Fragment。而Model可以是 Java 类、数据库、网络请求或其他数据源,就是负责数据的读取操作的。而View的话一般来说是指XML布局文件。
MVP架构
- Model: 数据提供层,负责向Presenter提供数据或者提供数据处理入口
- View: 视图层,负责接收Presenter通知,进行界面更新
- Presenter: View与Model的枢纽层,负责接收View层的命令,从Model层读取并处理好数据后,通知View进行界面更新。

优势
- 把业务逻辑抽离到Presenter层中,View层专注于UI的处理。
- 分离视图逻辑与业务逻辑,达到解耦的目的。
- 提高代码的阅读性。
- Presenter被抽象成接口,可以根据Presenter的实现方式进行单元测试。
- 可拓展性强。
缺点
- 项目结构会对后期的开发和维护有一定的影响。具体视APP的体量而定。
- 代码量会增多,如何避免编写过多功能相似的重复代码是使用MVP开发的一个重点要处理的问题。
- 有一定的学习成本。
简单实现
简单实现这里就是基本地使用接口进行通信

依赖
个人开发习惯使用的一些类
1
2
3
4
5
6maven { url 'https://www.jitpack.io' }//settings.gradle添加仓库
implementation 'com.github.zhpanvip:bannerviewpager:3.5.12'//Banner
implementation 'com.squareup.retrofit2:retrofit:2.9.0'//retrofit
implementation 'com.squareup.retrofit2:converter-gson:2.7.0'//gson
implementation 'com.github.bumptech.glide:glide:4.14.2';//GlideHomepageBannerAdapter
Banner的适配器
1
2
3
4
5
6
7
8
9
10
11
12public class HomepageBannerAdapter extends BaseBannerAdapter<String> {
protected void bindData(BaseViewHolder<String> holder, String data, int position, int pageSize) {
View view = holder.findViewById(R.id.img);
Glide.with(holder.itemView).load(data).error(R.mipmap.ic_launcher).placeholder(R.mipmap.ic_launcher).into((ImageView) view);
}
public int getLayoutId(int viewType) {
return R.layout.item_homepage_banner;
}
}BaseActivity
这个就是抽取Activity必须做的事情成一个Base基类,这个类中必须实现createPresenter去自定义自己的Presenter,并需要调用presenter的attachView去持有view的弱引用(绑定),并在onDestory阶段进行
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34public abstract class BaseActivity<T extends BasePresenter,V extends IBaseView> extends AppCompatActivity {
protected T presenter;
protected void onCreate( Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
//选择自己的表示层
presenter = createPresenter();
presenter.attachView((V)this);
registerSDK();
init();
}
/**
* 这里就要求用户去自己createPresenter选择一个Presenter
* SDK初始化。。。操作也而已定义在Base类中
*/
protected abstract T createPresenter();
protected void registerSDK(){};
protected void unRegisterSDK(){};
protected void init(){};
protected void onDestroy() {
super.onDestroy();
presenter.deatchView();
unRegisterSDK();
}
}BasePresenter
这个就是将每个Presenter必须做的事情抽取成一个Base类,也就是持有View的弱引用,防止内存泄露
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21public class BasePresenter<T extends IBaseView>{
public WeakReference<T> mView;
/**
* 绑定
*/
public void attachView(T view){
mView = new WeakReference<>(view);
}
/**
* 解绑
*/
public void deatchView(){
if (mView!=null){
mView.clear();
mView = null;
}
}
}IBaseView
这个类没有去做什么事情,单纯就是假设BaseView还有一些基本公共事件就抽取到这里面来
1
2
3public interface IBaseView {
//BaseView写一些View的一些通用的逻辑
}HomepageBannerModel
这是IHomepageBannerModel的具体实现,进行数据的加载,并告知IHomepageBannerPresenter数据加载完成,然后由IHomepageBannerPresenter告诉View更新View
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38public class HomepageBannerModel implements IHomepageBannerModel{
private IHomepageBannerPresenter mIHomepageBannerPresenter;//告诉Presenter加载数据完成
public HomepageBannerModel(IHomepageBannerPresenter IHomepageBannerPresenter) {
mIHomepageBannerPresenter = IHomepageBannerPresenter;
}
public void getBanner() {
Retrofit retrofit = new Retrofit.Builder().baseUrl("https://www.wanandroid.com/")
.addConverterFactory(GsonConverterFactory.create())
.build();
IWanAndroid wanAndroid = retrofit.create(IWanAndroid.class);
Call<HomepageBannerResponseBean> call = wanAndroid.getHomePagerBanner();
call.enqueue(new Callback<HomepageBannerResponseBean>() {
public void onResponse(Call<HomepageBannerResponseBean> call, Response<HomepageBannerResponseBean> response) {
HomepageBannerResponseBean responseBean = response.body();
if (responseBean!=null){
Log.i("TAGG",responseBean.getData().toString());
List<HomepageBannerResponseDataBean> beanData = responseBean.getData();
List<String>list = new ArrayList<>();
for (HomepageBannerResponseDataBean bean:beanData) {
list.add(bean.getImagePath());
}
mIHomepageBannerPresenter.loadBannerPicSuccess(list);//告诉Presenter数据加载完成
}
}
public void onFailure(Call<HomepageBannerResponseBean> call, Throwable t) {
Log.i("TAGG",t.toString());
}
});
}
}IHomepageBannerModel
Model接口,谁调用接口的getBanner就是通过具体实现类去完成数据获取
1
2
3
4
5
6
7public interface IHomepageBannerModel {
/**
* 向服务器请求数据
*
*/
void getBanner();
}HomepageBannerPresenter
Presenter的接口的具体实现,在View调用fetch方法就会调用持有的Model进行数据的获取,然后再获取到数据后调用持有的View去通知View进行页面的更新
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29public class HomepageBannerPresenter extends BasePresenter<IHomepageBannerView> implements IHomepageBannerPresenter{
private IHomepageBannerModel mIHomepageBannerModel;
public HomepageBannerPresenter() {
mIHomepageBannerModel = new HomepageBannerModel(this);
}
/**
* 执行业务逻辑
* 一般会把业务逻辑统一放在fetch方法中
*/
public void fetch(){
if (mView!=null&&mIHomepageBannerModel!=null){
loadBannerPic();
}
}
public void loadBannerPic() {
mIHomepageBannerModel.getBanner();
}
public void loadBannerPicSuccess(List<String> data) {
mView.get().showBannerPic(data);
}
}IHomepageBannerPresenter
1
2
3
4
5
6
7
8
9
10
11
12public interface IHomepageBannerPresenter {
/**
* 开始加载图片
*/
void loadBannerPic();
/**
* 成功加载图片
*/
void loadBannerPicSuccess(List<String> data);
}IWanAndroid
Retrofit进行网络请求
1
2
3
4public interface IWanAndroid {
Call<HomepageBannerResponseBean> getHomePagerBanner();
}HomepageBannerResponseBean
网络请求Bean类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18public class HomepageBannerResponseBean {
private List<HomepageBannerResponseDataBean> data;
private Integer errorCode;
private String errorMsg;
public List<HomepageBannerResponseDataBean> getData() {
return data;
}
public Integer getErrorCode() {
return errorCode;
}
public String getErrorMsg() {
return errorMsg;
}
}HomepageBannerResponseDataBean
网络请求Bean类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42public class HomepageBannerResponseDataBean{
private String desc;
private Integer id;
private String imagePath;
private Integer isVisible;
private Integer order;
private String title;
private Integer type;
private String url;
public String getDesc() {
return desc;
}
public Integer getId() {
return id;
}
public String getImagePath() {
return imagePath;
}
public Integer getIsVisible() {
return isVisible;
}
public Integer getOrder() {
return order;
}
public String getTitle() {
return title;
}
public Integer getType() {
return type;
}
public String getUrl() {
return url;
}
}IHomepageBannerView
1
2
3
4
5
6
7
8public interface IHomepageBannerView extends IBaseView {
/**
* 加载Banner图片成功
*/
void showBannerPic(List<String> data);
}MainActivity
这里当然还可以新建一个UI包,并将activity和Fragment等分别存放到这个包,具体的可以自己做,这里就是简单展示MVP
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30public class MainActivity extends BaseActivity<HomepageBannerPresenter,IHomepageBannerView> implements IHomepageBannerView {
private BannerViewPager bvp;
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
initView();
presenter.fetch();//执行presenter的业务逻辑
}
protected HomepageBannerPresenter createPresenter() {
return new HomepageBannerPresenter();
}
public void showBannerPic(List<String> data) {
bvp.refreshData(data);
}
private void initView() {
bvp = findViewById(R.id.bvp);
//异步同步
bvp.setLifecycleRegistry(getLifecycle())
.setAdapter(new HomepageBannerAdapter())
.create();
}
}activity_main.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
<RelativeLayout xmlns:android="http://schemas.android.com/apk/res/android"
xmlns:app="http://schemas.android.com/apk/res-auto"
xmlns:tools="http://schemas.android.com/tools"
android:layout_width="match_parent"
android:layout_height="match_parent"
tools:context=".MainActivity">
<com.zhpan.bannerview.BannerViewPager
android:layout_width="match_parent"
android:layout_height="wrap_content"
android:id="@+id/bvp"/>
</RelativeLayout>item_homepage_banner.xml
1
2
3
4
5
6
7
8
9
10
11<?xml version="1.0" encoding="utf-8"?>
<RelativeLayout xmlns:android="http://schemas.android.com/apk/res/android"
android:layout_width="match_parent"
android:layout_height="match_parent">
<ImageView
android:id="@+id/img"
android:layout_width="match_parent"
android:layout_height="match_parent" />
</RelativeLayout>
进阶
不使用接口,将接口链接转成总线,让presenter和model通过总线进行数据传输,如RxBus,并且解决了model和presenter接口爆炸的问题
dagger2注入型框架(依赖注入)
dagger android
hilt
Jetpack出现的Lifecycle
MVP融入Lifecycle
Jetpack
1 | # 使用androidx作为支持库 |
出现如下报错解决方案
1 | //Duplicate class kotlin.collections.jdk8.CollectionsJDK8Kt found in modules kotlin-stdlib-1.8.10 |
LiveData
Navigation
ViewModel
Room
DataBinding
WorkManager
Lifecycle
观察者和被观察者,Activity/Fragment相当于被观察者,而观察者可以为其他任何的类
AppCompatActivity继承FragmentActivity,FragmentActivity继承ComponentActivity
通过getLifecycle().addObserver(observer);去绑定观察者
addObserver()需要传入LifecycleObserver类型的对象,在addObserver内部用ObserverWithState类对LifecycleObserver类的对象进行了包装,并将初始状态存入(初始状态有几个值)
ObserverWithState类初始化的时候会调用Lifecycling.lifecycleEventObserver(observer)得到lifecycleEventObserver对象,lifecycleEventObserver方法需要传入一个Object对象(所以说什么对象都可以监听生命周期的变化)
MVVM架构
这里学完JetPack中的组件
Android 业务架构 · 基础篇 · Jetpack - 简书 (jianshu.com)
Android MVVM框架搭建(一)ViewModel + LiveData + DataBinding-CSDN博客
单向绑定就是数据发生改变就通知视图发生相应改变,但是视图发生改变并不会通知数据发生变化
而双向绑定就是数据发生改变时会通知视图发生相应的改变,视图发生改变也会通知数据发生变化

享学课堂视频
已看
Glide
12(看完觉得自己捞)23 24 25 27
55 56 57 58 59
60 61 62 63 64
65 66 67 68
85 86
88 89 90 92
93
学习过程记录
启动流程
Android设备启动流程
三分钟带你了解Android 系统启动流程详解 (zhihu.com)
BootLoader进程(相当于电脑主板的bios,引导程序)
安装在硬件上的固定进程,从Rom加载到Ram内存后就会拉起操作系统,也就是内核会启动
Linux Kernel
内核会运行init.cpp文件去读取init.rc,根据init.rc配置文件中的配置信息启动相关的服务,之后开启 一个Zygote进程
Zygote进程(init在Native层,Zygote走到C++FrameWork层了)
这个可以看成是Android的第一个进程,进程中会开启JVM(java虚拟机)和JNI方法注册,这个进程还会去孵化一个SystemServer的进程
SystemServer(SystemServer在Java Framework层)
启动过程中会启动80多种的服务,包括Binder线程池、SystemServiceManager等等,之后Zygote、SystemServer、SustemServiceManager会一起启动多种服务(如AMS、WMS、PMS。。。),接下来AMS就会开启Launch(Launcher.java),那么系统的桌面其实就是Launch,这也是系统中的一个应用,之后就可以看App启动流程了

APP启动流程
Android App 启动流程梳理(基于 Android 10)_android app启动流程-CSDN博客
Launch.java文件
- 首先肯定有一个onclick方法(点击事件),点击桌面的图标后会有一个tag标记
- 然后调用
startActivitysafely(view, intent, tag);,在这里面又会调用startActivity(view,intent,tag) - 在
startActivity()中根据是否使用动画进行不同处理,但是都会调用一个startActivity()(这个是进行冷启动,使用动画的冷启动传入参数为intent和opts.toBundle(),不使用动画的冷启动传入的参数是intent)和launcherApps.startMainActivity()(这个是进行热启动) - 冷启动方法的内部:冷启动内部会根据传入的option(这个是根据上面是否传入第二个参数来确定是否为null)是否为null,进行不同处理,都是调用
startActivityForResult(),不为null就把intent和options都传入,为null就不传入 - startActivityForResult内部会通过Instrumentation.execStartActivity()(Instrumentation是Activity和AMS通信的核心对象,为了做自动化测试而设计的 ),看到这里就找到了冷启动是借助Instrumentation去和黑盒(也就是上图的所有部分,AMS)沟通
- 热启动说直接点就是使用了Binder通信
- 那么在黑盒里面就会根据不同的启动方式,zygote进程会
fork()一个ActivityThread.java
ActivityThread.java文件
- 首先直接看到main方法,很多是看不懂的,但是有Handler通信和Looper的内容,直接看到
thread.attach()(这里的thread就是ActivityThread对象) - 在attach方法中,会通过ActivityManager.getService()获取一个IActivityManager类型的对象mgr,mgr会执行,这里也是使用Binder通信,这里调用
mgr.attachApplication(mAppThreaad,startSeq)去让黑盒调用handlerBindApplication方法 - 在handlerBindApplication方法中,就会根据一系列数据生产出application对象,也就是
app = data.info.makeApplication()这个就是平时项目中的application,之后就通过Instrumentation去管理生命周期,也就是调用mInstrumentation.callApplicationOnCreate(app),之后application的onCreate()就执行了 - 之后就是平时项目中的activity的onCreate了,黑盒子会调用
performLaunchActivity()生产Activity,然后Instrumentation类会newActivity()生产Activity,之后就会绑定到窗口,activity.attach(),又会进入黑盒(FrameWork层)会将Activity绑定到窗口,又调用mInstrumentation.callActivityOnCreate()
HashMap

hash
存放所有拼音和对应地址的表可以看做是 「哈希表」。
赞字的拼音索引可以看做是哈希表中的 「关键字 key」。
根据拼音索引来确定字对应页码的过程可以看做是哈希表中的 「哈希函数 Hash(key)」。
查找到的对应页码可以看做是哈希表中的 「哈希地址 value」。
插入节点流程Put
key就是为了能快速查找
key.hashCode()转变为hashcode,是一个int值(无符号右移 16 位然后做异或运算)(还有平方取中法,伪随机数法和取余数法。这三种效率都比较低。而无符号右移 16 位异或运算效率是最高的),之后进行位运算,也就是取模,得到的结果在0到length-1,得到index就存储即可,jdk1.7链表是前插
得到下标后需要创建一个节点,之后构建链表
在第一次用的时候才会去初始化,一开始虽然说是分配16长度的空间,但不使用也分配会浪费空间(懒加载) 创建长度为Node[] table (jdk1.8 之前是 Entry[] table)用来存储键值对数据
插入过程中会出现哈希碰撞
就是计算下标的过程会出现哈希碰撞,链表法解决碰撞,但本质是需要避免哈希冲突
极端情况就是一直哈希碰撞,那么就变成一个单链表,那么效率就会非常低,这就需要优化
(大牛设计为)16个节点(why?)
二进制中16就为10000, 减1就为1111(从0开始),进行与计算哈希冲突就少,假设与0进行,结果为0,与1进行,结果为1,其他的如1100进行与计算更容易冲突,设计者明文规定初始值哈希表的size为2的n次幂(list的长度)与操作就是两个同时为1结果才为1,否则结果为0
之后改进,不使用单链表,在Java8(JDK1.8)中HashMap改进为使用红黑树,解决极端情况出现长的单链表的问题
Hash冲突不再使用链表保存相同Index的节点,使用红黑树(高性能的平衡树)来保存冲突节点,节点查询优先级别从O(n)提高到了O(log n)
不是什么情况都是使用红黑树,构建过程很复杂,在Java8中如果链表长度大于8并且数组长度大于64才会考虑将链表转换为一个红黑树
查找过程
就是相反,先进行hash计算得到index,然后遍历链表得到需要的value即可
线程安全问题
在线程中是不安全的
简单情况,一边正在插入节点,一边正在删除节点就会出现问题,如扩容过程中插入节点也会有问题。。。
后面都是在HashMap基础上不断优化演变过来的
产生死锁的原因,都是在访问同一个链表的过程中产生死锁的
为什么key喜欢用String类型
改写了hashcode函数去计算hash值,与String的每一位字符去计算hash值,这是为了避免哈希冲突
解决哈希冲突的办法
扩容也是一种解决办法,使数组变的更大,那么取模的时候容纳的值更多,阈值=长度*填充因子,两倍两倍扩容
加载因子最优是0.6到0.75,这个值是根据空间和时间,通过泊松分布算法得到的一个折中的值
可以认为,当我们明确知道 HashMap 中元素的个数的时候,把默认容量设置成 initialCapacity/ 0.75F + 1.0F 是一个在性能上相对好的选择,但是,同时也会牺牲些内存。
HashTable
Put过程
跟HashMap数据结构一样,但是在put方法加锁,synchronized(同步锁,保证并发安全)public synchornized v put ,其他跟HashMap一样(所有方法都加了一个锁,那么效率就会非常低,频繁等锁)
为了解决效率低的问题,又出现了ConcurrentHashMap
与HashMap区别
都是基于hash表实现的KV结构的集合,HashMap是JDK1.0引入的线性安全的集合类,所有数据访问的方法都加了一个Synchronized同步锁,内部采用数组+链表来实现,链表主要是实现hash表的一个hash冲突的问题,HashMap是JDK1.2引入的线程不安全的集合类,内部使用数据结构相同,但在JDK1.8使用红黑树进行了优化,链表长度大于等于8并且数组长度大于64的时候就会把链表转换成红黑树,提高数据查找的性能。
高手回答(对比回答)
功能特性:
HashTable是线程安全的,HashMap不是
HashMap的性能要比HashTable更好,因为HashTable采用了全局同步锁来保证安全性,对性能的影响较大
内部实现角度:
HashTable内部使用数组+链表,HashMap采用数组+链表+红黑树
HashMap初始容量为16,每次扩充为2倍;HashTable初始容量为11,每次扩充为2n+1
HashMap可以使用null作为key,会转换为0,HashTable不允许
最后
他们使用的key的散列算法不同,HashTable直接使用key的hashcode对数组长度取模,HashMap对hashcode做了二次散列,从而避免了key分布不均匀影响到查询性能
LinkedHashMap
Java基础汇总(十六)——LinkedHashMap-CSDN博客
LinkedHashMap=HashMap + 双向链表
LinkedHashMap是HashMap的子类(拥有HashMap的所有特性)
HashMap是无序的,LinkedHashMap通过维护一个额外的双向链表保证了迭代顺序
迭代顺序可以是插入顺序,也可以是访问顺序(即根据链表中元素的顺序可以将LinkedHashMap分为:保持插入顺序的LinkedHashMap和保持访问顺序的LinkedHashMap,其中LinkedHashMap的默认实现是按插入顺序排序的)
图解LinkedHashMap原理 - 简书 (jianshu.com)
HashSet
基于HashMap的封装
ConcurrentHashMap
解决HashTable效率低的方法其实就是对当前需要访问的链表加锁即可,保证无多个线程对同一个链表进行操作即可
- JDK1.8的实现降低锁的粒度,JDK1.7版本锁的粒度是基于Segment的,包含多个HashEntry,而JDK1.8锁的粒度就是HashEntry。
- JDK1.8版本的数据结构变得更加简单,使得操作也更加清晰流畅,因为已经使用synchronized来进行同步,所以不需要分段锁的概念,也就不需要Segment这种数据结构了,由于粒度的降低,实现的复杂度也增加了。
- JDK1.8使用红黑树来优化链表,基于长度很长的链表的遍历是一个很漫长的过程,而红黑树的遍历效率是很快的,代替一定阈值的链表。
Put操作
对f进行加锁,也就是table数组index下标为i的值,也就是一个链表,而不是对整个方法进行加锁
remove操作
一样的,也是对f进行加锁
红黑树
红黑树(Red Black Tree)是一种自平衡的二叉查找树,是一种高效的查找树。在当时被称为平衡二叉 B 树(symmetric binary B-trees)。后来,在1978年被 Leo J. Guibas 和 Robert Sedgewick 修改为如今的红黑树。红黑树具有良好的效率,它可在 O(logN) 时间内完成查找、增加、删除等操作。所谓的平衡树是指一种改进的二叉查找树,顾名思义平衡树就是将二叉查找树平衡均匀地分布,这样的好处就是可以减少二叉查找树的深度。
特征
红黑树除了具备二叉查找树的基本特性之外,还具备以下特性
- 节点是红色或黑色;
- 根节点是黑色;
- 所有叶子都是黑色的空节点(NIL 节点);
- 每个红色节点必须有两个黑色的子节点,也就是说从每个叶子到根的所有路径上,不能有两个连续的红色节点;
- 从一个节点到该节点的子孙节点的所有路径上包含相同数目的黑色节点
平衡二叉树为了维护树的平衡,在一旦不满足平衡的情况就要进行自旋,但是自旋会造成一定的系统开销,因此红黑树在自旋造成的系统开销和减少查询次数之间做了权衡。因此红黑树有时候并不是一颗平衡二叉树
一个n个节点的红黑树的高度最高为2log(n+1)
平衡二叉树与红黑树的区别
- 平衡二叉树的左右子树的高度差绝对值不超过1,但是红黑树在某些时刻可能会超过1,只要符合红黑树的五个条件即可。
- 二叉树只要不平衡就会进行旋转,而红黑树不符合规则时,有些情况只用改变颜色不用旋转,就能达到平衡。
红黑树的原理
红黑树能够实现自平衡和保持红黑树特征的主要手段是:变色、左旋和右旋。
左旋:指的是围绕某个节点向左旋转,也就是逆时针旋转某个节点,使得父节点被自己的右子节点所替代
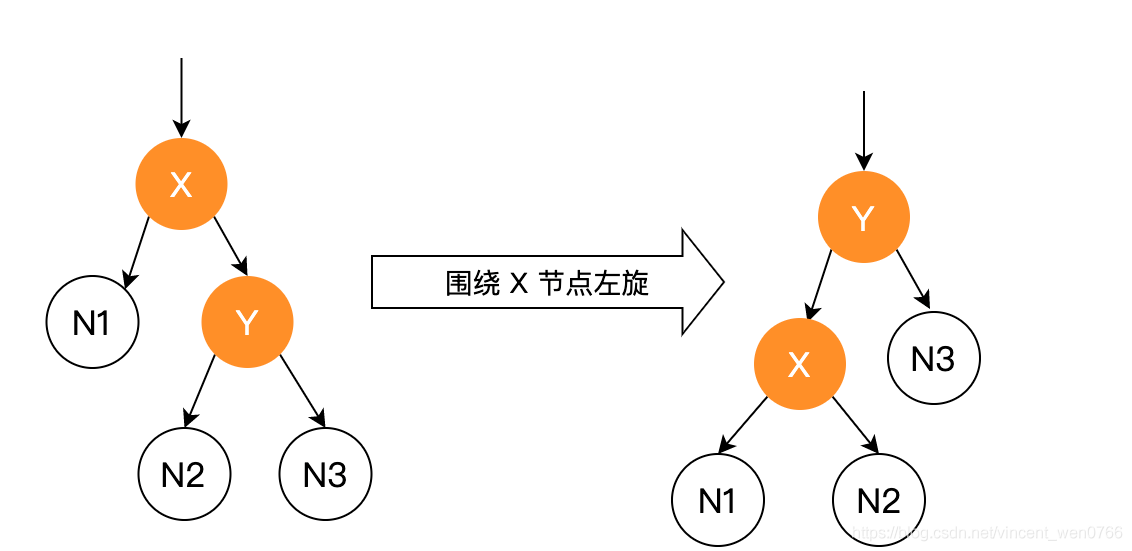
右旋:指的是围绕某个节点向右旋转,也就是顺时针旋转某个节点,此时父节点会被自己的左子节点取代
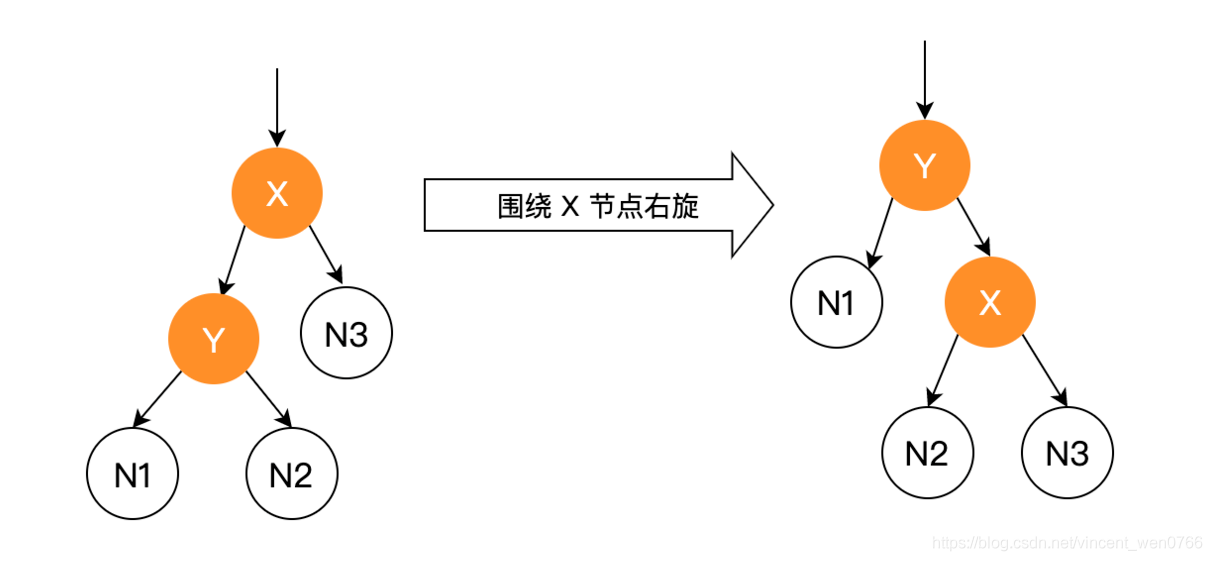
变色:如果当前节点的左、右子节点均为红色时,因为需要满足红黑树定义的第四条特征
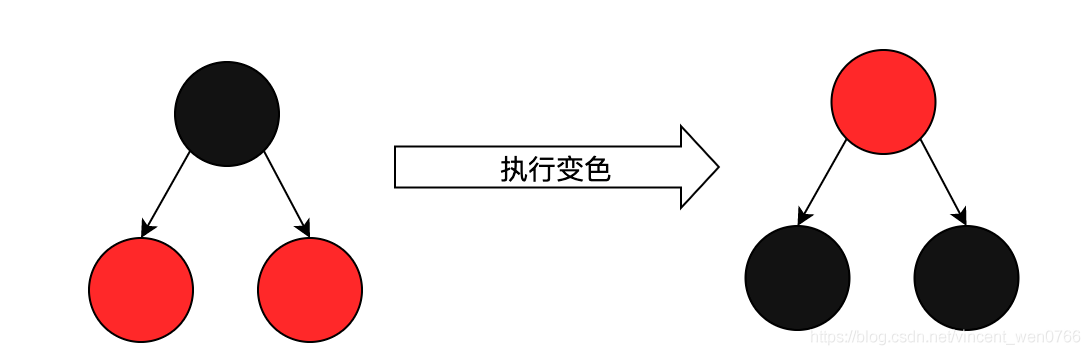
二叉查找树
二叉查找树(Binary Search Tree,BST),又叫做二叉排序树、二叉搜索树,是一种对查找和排序都有用的特殊二叉树;红黑树,AVL树都是特殊的二叉查找树(自平衡二叉搜索树)
二叉查找树或是空树,或是满足如下三个性质的二叉树:
- 若其左子树非空,则左子树上所有节点的值都小于根节点的值
- 若其右子树非空,则右子树上所有节点的值都大于根节点的值
- 其左右子树都是一棵二叉查找树
平衡二叉树
平衡二叉树,又称AVL树,它是一种特殊的二叉排序树。AVL树或者是一棵空树,或者是具有以下性质的二叉树:
(1)左子树和右子树都是平衡二叉树;
(2)左子树和右子树的深度(高度)之差的绝对值不超过1。
满二叉树
度:树节点的度就是该节点孩子的个数
一棵高度为h,并且含有2的h次方减1的二叉树称为满二叉树,即树中的每一层都含有最多的结点。满二叉树的叶子节点都集中在二叉树的最下一层,并且除叶子结点之外的每个结点度数均为2.(二叉树结点的度即为结点的孩子个数)。
特点:
- 只有最后一层有叶子结点。
- 不存在度为1的结点。
- 按层序从1开始编号,自上而下,自左向右。这样每个结点对应一个编号,对于编号为i的结点,如果有双亲,其双亲为[i / 2],如果有左孩子,则左孩子为2i,如果有右孩子,则有孩子为2i+1。
完全二叉树
设一个高度为h, 有n个结点的二叉树,当且仅当其每一个结点都与高度为h的满二叉树中编号为1… n 1 … n1…n的节点一一对应时,称为完全二叉树。
特点:
- 只有最后两层可能有叶子结点。
- 最多只有一个度为1的结点,且该节点只有左孩子没有右孩子。
- 若i < = ⌊ n / 2 ⌋,则节点i为分支结点,否则为叶子节点。
- 按层序编号之后,一旦出现某节点(其编号为i)为叶子结点或只有左孩子,那么编号大于i的节点均为叶子结点。
- 若n为奇数,则每个分支结点都有左孩子和右孩子;若n为偶数,则编号最大的分支结点(编号为n/2)只有左孩子没有右孩子,其余分支结点左右孩子都有。
Glide
Glide三部曲
with:空白的Fragment管理生命周期机制
为什么监听Fragment/Activity生命周期
Glide会监听传入的对象的生命周期,内部会自动进行回收,可以自己再手动在onDestory去回收,也可以不写,Glide会自动去做
(不把生命周期的管理交给用户去做可以避免发生人为的失误)
怎么监听生命周期的变化的
创建了一个空白的Fragment,连接Activity,就能监听到Activity的生命周期变化了,在Glide有一个RequestManager(这是监听生命周期变化的接口的实现类)去管理图片的请求,这个类可以根据Activity生命周期的变化而变化
源码分析
由一个get方法去获取RequestManager,如果是子线程不需要管什么,没有生命周期需要管理,主线程就需要先添加一个空白的Fragment,最终with会返回一个RequestManager对象
load:最终构建RequestBuilder对象
最终会返回一个RequestBuilder对象
into:等待队列,执行队列;活动缓存;内存缓存;HttpUrlConnection
源码分析
首先要得到ImageViewTarget
构建Request,是一个接口,实现类是SingleRequest,并且在上一个请求没有请求完就先完成上一个请求
维护两个队列,正在运行队列和等待队列,一进来都添加到运行队列中,运行队列暂停了就直接添加到运行队列运行(begin),运行队列还在运行就添加到等待队列
这里都是直接调用接口方法的,实现在SingleRequest
begin方法:onSizeReady,再会调用Engine.load,之后从内存获取(生成key,从弱引用获取),然后再通过jobs.get检测有没有真正执行的缓存可用(与磁盘缓存有关),实在没有就进行网络请求
EngineJob维护线程池
DecodeJob给EngineJob进行执行,相当于一个任务Runnable和run函数
后面具体请求部分太乱了,看视频吧!!!
OKHttp
使用方法
调用流程
代码部分前面了
OkHttp请求过程解除最多的是OkHttpClient、Request、Call、Response,但是框架内部进行了大量的逻辑处理,所有逻辑处理大部分集中在拦截器中,但是进入拦截器之前还需要依靠分发器来调配请求任务
分发器:内部维护队列和线程池,完成请求调配
拦截器:完成整个请求过程(完成一次完整的http请求的过程,DNS解析->三次握手建立TCP连接(socket)->发送http报文)(当然这里还完成了许多的优化的功能,包括连接池等等)
分发器Dispatcher
下面这部分就相当于是OkHttp进行网络请求的具体流程,源码分析就分析其中一些具体部分
构建OkHttpClient对象构造者模式可以使用自己的分发器对象
OkHttpClient的newCall方法传入Request对象得到一个Call对象(Call是一个接口,实现类是RealCall类,将OkHttpClient对象、Request对象都交给RealCall去处理,然后返回对象)
然后调用RealCall对象的同步和异步请求的方法发起请求
然后看到enqueue异步请求方法(进入这个方法一进来就synchronized(this),加锁保证RealCall并限制只能进行同步请求或异步请求,不能同时进行,否则抛出异常,可以使用clone方法,克隆一个对象出来进行请求)(OkHttpClient还可以设置EventListener对象,可以监听请求的开始。。。)
然后enqueue内部就调用OkHttpClient的dispatcher方法去获取DisPatcher对象去执行enqueue方法,之后传入一个AsyncCall对象(可以看作请求任务),这个对象传入CallBack回调
进入分发器的enqueue方法,有RunningAsyncCalls(正在执行异步请求队列)、RunningSyncCalls(正在执行的同步请求队列)、ReadyAsyncCalls(等待异步请求队列)队列(ArrayDeque类型,内部循环数组,作者解释,如果把这个类型当做stack栈来使用,它比栈快,如果把它当做queue来使用,它比LinkedList快)
接下来就是分发器分发任务的过程,对于异步请求有两种方式,进入等待队列,进入执行队列
进入Running队列的请求任务就会加入线程池执行,也是在enqueue方法中的,在加入执行队列代码下一行就是让ExecutorService对象(其实就是线程池)的execute执行这个Call对象任务(线程池需要接收Runnable,Call也就是AsyncCall其实就是Runnable)
接下来就是执行AsyncCall这个里面的execute方法(AsyncCall继承的类中的run执行了一个抽象方法execute),下面其实就是通过getResponseWithInterceptorChain方法去走拦截器,返回Response,这里异常机制,finally代码块一定执行,执行client.dispatcher().finished(this),finish方法传入running队列,AsyncCall对象和true,然后从Running队列移除已经完成的Call对象,然后就循环根据下面提到的从Ready队列拿对象放到Running队列
离并发任务分发
异步请求
分发器怎么决定放入ready还是running队列?
是一个判断语句
第一个条件根据正在执行异步请求队列的个数决定的,分发器默认定义这个值为64,小于这个值直接加入Running队列,大于这个值就加入Ready队列(可以修改)
第二个条件是同一个域名的请求最大数不大于5个,默认值为5个
从Ready移动到Running的条件是什么?
任务结束判断,Running队列数量少于分发器规定的最大同时异步请求对象的数量,并且请求队列不为空,而且对于同一域名的请求数量少于定义的数量(多于的对象就找下一个),就移动到Running队列中
分发器线程池怎么定义的?
executorService其实就是线程池,new了一个ThreadPoolExecutor对象(这个就是最基本的线程池类,不是那几个特别的,可以看前面的部分,下面讲一下它构造这个对象传入的内容),这里传入的等待队列传入的类型是synchronousQueue(因为LinkedBlockingQueue和ArrayBlockingQueue不合适,如果使用ArrayBlockingQueue设定值为1,核心线程数为1,那么如果有一个线程一直在跑,又进来一个任务就会进入队列,再进来一个任务就又要入队,但是队列满了按照这个类型的等待队列就需要额外新建一个线程,但是会先跑任务3再跑任务2,就很有问题,因为我们需要线程进来就开始跑,并且按顺序来),那么如果达到线程池定义的最大线程数怎么办呢,就会需要使用线程池传入的拒绝策略的参数来进行处理

同步请求
同样是先一个判断语句一个call只能用一次,然后执行分发器的同步请求方法(这里面就是直接把这个call放入running队列,直接执行),最后使用分发器的finished方法(将完成同步请求的call从队列remove)
前面异步的具体流程直接看分发器的部分就可以了
线程池排队
OKHttp传入的工作队列类型决定了他的工作行为为无等待,最大并发的,这个就是具体的排队机制,这很符合OkHttp的使用场景,高并发的网络请求场景,但是并不会很容易OOM,因为前面分发器中定义的等待队列和
执行队列就是为了限制所有的异步请求的数量,避免了OOM
拦截器
责任链模式
(避免请求发送者与接收者耦合在一起,让多个对象都有可能接收请求,将这些对象连接成一条链,并且沿着这条链传递请求,直到有对象处理它为止。
职责链上的处理者负责处理请求,客户只需要将请求发送到职责链上即可,无须关心请求的处理细节和请求的传递,所以职责链将请求的发送者和请求的处理者解耦了。)
请求从上往下去执行,响应再从下往上去回传

五大拦截器
RetryAndFollowUpInterceptor(重试和重定向拦截器)
第一个接触到请求,最后接触到响应;负责判断是否需要重新发起整个请求
BridgeInterceptor(桥接拦截器)
补全请求(如补全请求头,gzip解压or设置cookie),并对响应进行额外处理
CacheInterceptor(缓存拦截器)
请求前查询缓存,获得响应并判断是否需要缓存(需要使用就需要手动去开启缓存,就是在构建OkHttpClient的时候在Builder.cache(new Cache(存储路径,最大长度)))
HTTP缓存有多种规则,根据是否需要重新向服务器发起请求来分类可以分为强制缓存和对比缓存
强制缓存
http1.1的head中Cache-Control字段标明失效规则,private客户端可以缓存;public客户端和代理服务器都可以缓存;max-age=xxx:缓存的内容将在 xxx 秒后失效;no-cache:需要使用对比缓存来验证缓存数据;no-store:所有内容都不会缓存,强制缓存,对比缓存都不会触发
对比缓存
对比缓存,顾名思义,需要进行比较判断是否可以使用缓存。
最重要的就是在header中的传递的两种标识,Last-Modified / If-Modified-Since,Last-Modified:
服务器在响应请求时,告诉浏览器资源的最后修改时间;If-Modified-Since:再次请求服务器时,通过此字段通知服务器上次请求时,服务器返回的资源最后修改时间。
服务器收到请求后发现有头If-Modified-Since 则与被请求资源的最后修改时间进行比对。
若资源的最后修改时间大于If-Modified-Since,说明资源又被改动过,则响应整片资源内容,返回状态码200;若资源的最后修改时间小于或等于If-Modified-Since,说明资源无新修改,则响应HTTP 304,告知浏览器继续使用所保存的cache。还有Etag / If-None-Match(优先级高于Last-Modified / If-Modified-Since),Etag:
服务器响应请求时,告诉浏览器当前资源在服务器的唯一标识(生成规则由服务器决定),If-None-Match:再次请求服务器时,通过此字段通知服务器客户段缓存数据的唯一标识。服务器收到请求后发现有头If-None-Match 则与被请求资源的唯一标识进行比对,不同,说明资源又被改动过,则响应整片资源内容,返回状态码200;相同,说明资源无新修改,则响应HTTP 304,告知浏览器继续使用所保存的cache。
ConnectInterceptor(链接拦截器)
与服务器完成TCP连接 (Socket)
CallServerInterceptor(请求服务拦截器)
与服务器通信;封装请求数据与解析响应数据(如:HTTP报文)
还可以自定义拦截器
在Builder的addInterceptor和addNetworkInterceptor可以传入自定义的拦截器,这两者的区别体现在添加到list的顺序不同,添加拦截器是在RealCall中完成的,getResponseWithInterceptorChain中完成的,addInterceptor添加到拦截器会在list的最前面,也就是在重试和重定向拦截器的前面,而addNetworkInterceptor添加的拦截器在最后一个请求连接器的前面
1 | Response getResponseWithInterceptorChain() throws IOException { |
拦截器中的ConnectionPool(连接池)看前面的OkHttp部分有提到原理
网络代理
这是网络通信必备基础中的socket通信原则中的内容,socket通信原则中有SOCKS代理和HTTP普通代理与隧道代理
Retrofit

本身就是一个(外观设计模式),本身不具备新的功能,本身就是对其他东西的封装,但是所有网络请求都走这里就形成了一个类似接口的东西
Retrofit是不具备拦截器的,但是可以在OkHttpClient中添加然后传入给Retrofit
Retrofit实例创建过程(构建者设计模式:构造函数参数大于5个,存在可选参数就可以使用构造者设计模式)
baseUrl主域名;callFactory网络请求工厂;addConverterFactory数据转换器;addCallAdapterFactory这个就是添加到下面的adapterFactories中,这些其实就是通过构造者模式的builder往retrofit对象去添加不同的参数
里面参数
baseUrl(网络请求的url地址)
callFactory(网络请求工厂)参数如果不指定,为null的话默认构建一个OKHttpClient(默认只支持okhttp),那么这里可以自定义一个OKHttpClident,自定义自己的需求然后传入
callbackExecutor(回调方法执行器)线程池,默认会创建一个线程池
adapterFactories(网络请求适配器工厂)(工厂设计模式)是一个ArrayList,会把多个adapter加入list,本身还会加入一个默认的adapter,adapter其实就是要将okhttp的call转换成retrofit的call,这个封装其实就是适配的过程(适配器设计模式)
converterFactory(数据转换器工厂)也是一个ArrayList,会把多个数据转换器(序列化工具)加入到List中

代理实例创建过程

上面蓝色部分就是retrofit的核心部分,返回一个create传入的接口的对象(内部new了一个接口类型的对象,虽然是接口类型),这就是动态代理(JDK的动态代理,后面再看吧,有反射的内容在里面,在内存中生成一个动态的类)


静态代理:学习动态代理之前需要先学习静态代理,了解代理的思想,可以看下面的图,假设要找明星拍视频,那么明星其实只需要进行拍视频即可,那么其他的谈合作和收尾部分其实只需要经纪人代理去完成即可;但是如果要换个明星那就很复杂了,但是对于用户来说谈价格和收尾内容一样的,应该可以让一个人来做就可以了,但是代理找不到具体的明星了,因为一个经纪人就负责一个明星,所以说代理对象只有一个并且代理类的接口比较稳定的时候就可以使用静态代理

这里回到retrofit部分,那么使用动态代理就可以让所有接口都走invoke函数,通过invoke函数就可以拦截调用函数的执行,就获取到接口上注解的参数,那么就可以构建request请求动态变化对象,动态构建URL,从而将网络接口的参数配置归一化,这就解决了OkHttp使用中的缺陷(用户网络接口配置繁琐,尤其是需要配置复杂请求的body,请求头,参数的时候;数据解析过程需要用户手动拿到reponseBody进行解析,不能复用;无法适配自动进行线程的切换;万一我们存在嵌套网络就会陷入回调陷阱)
其实根本不用管在接口那里定义的方法名是什么,因为重要信息其实是注解的参数,那么接口定义的方法拿到后在invoke中拿到参数即可,那么就可以拿到参数进行处理,返回其他对象,那么这里最后返回的其实是一个call对象
ServiceMethod设计理念
这个类是出现在动态代理内部的类,这里面会包含大量的反射和大量的解析(那么这个过程是比较耗时间和耗性能的),这个类的内部使用了缓存,为了来提高性能,那么只要Retrofit不退出,那么访问过的接口就在缓存中存在了,就不需要重新进行创建;那么在这个内部获取到了接口注解定义的参数,也知道了具体需要返回的类型,那么就可以从retrofit对象中确认(前面arrayList中放的对象就用一个for循环去找需要的内容即可)访问的完整的URL,适配器的种类和需要使用到的数据转换器,并确认具体的回调方法的执行器

在前面构建retrofit的过程中就是单纯的准备了各种所需要的东西,那么在serviceMethod中就是要并且具体使用哪些东西了,包括baseUrl(网络请求的url地址),callFactory,callAdapter,responseType(call返回值类型),responseConverter(明确对应的数据转化器),parameterHandlers(对接口中的注解参数进行解析配置);那么一个接口就是对应一个serviceMethod
RxJavaCallAdapterFactory设计模式和理念
之后可以由serviceMethod获取到call对象,之后就由call对象进行异步请求,这个就是OkHttp发起请求而已,之后就只需要关注response返回是怎么样进行处理的,也就是解析的过程以及适配器的工作过程即可。
适配器
(CallAdapter适配器的作用就是将Call
在builder中会默认添加一个适配器工厂,rxjava是解决回调嵌套的(链式调度),实际开发中不存在嵌套访问的情况那么就可以不使用rxjava(在这里并不是说rxjava能完成线程切换而使用的,不使用rxjava也是可以进行线程的切换到),那么就会自动用到了默认的适配器工厂,那么下面看一下默认适配器工厂怎么进行线程切换的:
在创建默认的适配器工厂defaultCallAdapterFactory的时候会传入callbackExecutor(这个其实就是一个Handler),那么在获取到response后就会通过callbackExecutor的异步方法去进行回调,会在主线程完成(callbackExecutor异步请求就是将需要执行的内容通过handler.post(runnable)让主线程执行内容),那么也就是说这样就已经能够完成线程的切换了

下面看一下RxJavaCallAdapterFactory的设计模式, 抽象工厂设计模式,
内部是先选择适配器工厂,再由工厂选择适配器,两个get方法,存在多个工厂和多种适配器(ResponseAdapter、ResultAdapter、SimpleCallAdapter),根据不同的返回内容选择不同的适配器(最终是需要把请求得到的内容转化成Obserable类型的对象的)
解析过程
转换器就是转换请求体和响应体
多线程相关
Synchronized锁机制和wait notify原理
联系前面多线程知识和这里,觉悟!!!

为什么是while,这个锁可能被其他地方唤醒等待,这里使用while哪怕被唤醒也会继续循环,有对象了就结束循环,没有就继续等待
volatile
- 现代计算机缓存架构,Cache,CPU和主内存的速度差异

- Java内存模型

Java内存模型(JMM)及8种原子操作 - 萝卜不会抛异常 - 博客园 (cnblogs.com)
为什么加volatile就能解决线程之间变量不可见的问题

多了一条总线,多个线程将值取到工作内存中,只有在修改的时候并且写入内存的时候会经过总线(写回住内存的过程中是加了锁的),总线嗅探到就会清空副本,需要的时候再重新从主内存拿进来
只需要有一个子线程执行了store和write操作就会触发总线嗅探机制,每个线程池上就会有一个总线嗅探器,
使用了volatile就会激活总线嗅探器,就是类似一个监听器(或者说观察者),就会把自己的flag副本清除掉,继续使用就重新从主线程去读取,总线嗅探机制+总线就是缓存一致性协议,就是为了使变量在线程之间是可见的状态
指令重排
这里需要先了解Java中对象的半初始化
java对象半初始化问题是怎么回事_java 对象部分初始化问题-CSDN博客

上面这里如果是单线程当然没什么问题,但是如果是多线程,执行下面的检测部分的代码的时候如果new对象的过程没有完全执行完,但是instance对象已经建立联系,只是后面i的赋值还没有执行,那么当另外一个线程进来就会直接获取instance对象,但是这时i还没有赋值,里面的i还是0,这时候就会出现问题,那么解决这个问题就是通过volatile的指令重排的方式实现的,这涉及到内存屏障,内容很多
局部单例,只对一个Activity有效,后面看
作用
直接看前面的特性吧,有提到,前面2点就是
移动端常用的锁方法
这里主要介绍了Android中经常用到的锁的使用方法
1 | //1 |
AtomicInteger
首先将需要加锁的值赋给自己内部的一个成员变量,然后通过反射的方式获取偏移量去读取数据,后面value读取数据是直接从共享内存去读取数据的,下面是从C和C++底层去操作了,是获取偏移地址的过程
看i–的那部分方法怎么实现的,执行decrementAndGet方法进行原子操作,这里面使用的是一个U.getAndAddInt方法,之后直接调用api通过起始地址和偏移量去获取变量,这里面有一个while循环包围在外面,这个while循环里面的compareAndSwapInt就是CAS机制,代码图片放CAS机制下面
正常情况下使用对象.属性获取值是没有什么问题的,但是在多线程中这样使用就会有问题,正常使用过程这样就会先复制一个副本到栈内存,之后读取是从栈内存去读取的(即时生效效果很快)
CAS机制原理分析
CAS,全称Compare And Swap(比较与交换),解决多线程并行情况下使用锁造成性能损耗的一种机制。

上面这里的compareAndSwapInt就是先将var5+var4存一份下来,也就是var-1,然后再根据传入的this和偏移量取数据和上面api取得的数据做一个比较,如果比较相等返回,否则一直循环直到满足条件。

直接看代码看不懂,这里的具体运行步骤其实就是:
在单线程情况下这里是没什么意义的,多线程情况下就有意义了,A线程先进来读取数据,读到数据后想要减1进行保存,但是还没保存时间片就到了,需要停止运行,让其他线程先运行,B线程这时取的是A还没有更新的值,但是他执行的比较快,就取更新了共享内存中的值,A线程这时可以继续运行了,会走到取值进行比较的时候,发现原本取到的值和现在共享内存的值不一样,就得重新循环上面的事情,重新取值然后重新运行。这样就保证了所有线程只进行一次减的操作
CAS原理:
通过查看AtomicInteger的源码可知,
1
2
3
4
5
private volatile int value;
public final boolean compareAndSet(int expect, int update) {
return unsafe.compareAndSwapInt(this, valueOffset, expect, update);
}
通过申明一个volatile (内存锁定,同一时刻只有一个线程可以修改内存值)类型的变量,再加上unsafe.compareAndSwapInt的方法,来保证实现线程同步的。
这时候比较懵的其实,前面内容有点乱,可以看下面的博客就知道具体关系了,里面有CAS和ABA相关
CAS与volatile关系以及如何保证原子性_cas和volatile-CSDN博客
volatile与CAS的比较_cas和volatile的区别-CSDN博客
CAS的好处就是没有执行阻塞操作,运行过程是很快的,但是问题就是如果访问的线程过多,CPU占用率就很高,高吞吐量和高并发就不太适合,3-5个线程使用CAS机制就是锁机制比不了的,可能会有ABA问题,循环时间开销大和只能保证一个共享变量的原子操作
可以用CAS在无锁的情况下实现原子操作,但要明确应用场合,非常简单的操作且又不想引入锁可以考虑使用CAS操作,当想要非阻塞地完成某一操作也可以考虑CAS。不推荐在复杂操作中引入CAS,会使程序可读性变差,且难以测试,同时会出现ABA问题
ABA问题
这个是CAS机制中会出现的问题,就是其他线程获取一个值后进行了多次修改,最后的值和原来的值一样,(过程发生了修改但是被告知没有修改)
这时当前线程认为是可以执行的,其实是发生了不一致现象,如果这种不一致对程序有影响(真正有这种影响的场景很少,除非是在变量操作过程中以此变量为标识位做一些其他的事,比如初始化配置),则需要使用AtomicStampedReference(除了对更新前的原值进行比较,也需要用更新前的 stamp标志位来进行比较)。
AQS
AQS,非阻塞数据结构和原子变量类(java.util.concurrent.atomic包中的类),这些concurrent包中的基础类都是使用这种模式来实现的,而concurrent包中的高层类又是依赖于这些基础类来实现的。
synchronized锁升级过程
重量级和轻量级
synchronized线程阻塞是依赖于操作系统的,依赖性强,所以是重量锁(对外依赖性强就是重量级)
(略:任何一个对象大小必须为8的倍数,如16bytes,不够是会进行内存填充的,创建一个对象的时候包含三部分信息,对象头、实例数据、填充数据,创建对象时会存储锁相关的信息,包括指向轻量级锁指针、指向重量级锁指针、偏向线程ID 等。)

对一个对象,只有单线程访问就会上一个偏向锁,偏向锁其实就是上面的CAS机制的while循环判断是否有值相等改变成if,就是偏向锁(性能高)
如果出现多线程访问,也就是轻度竞争,那么就会升级为轻量级锁,也叫自旋锁(底层就是CAS)
轻量级锁如果3-5ms还抢不到就会自动转换为重量级锁(基于线程原地等待,但是一直获取不到锁这个问题,我们必须给线程空循环设置一个次数,当线程超过了这个次数,我们就认为,继续使用自旋锁就不适合了,此时锁会再次膨胀,升级为重量级锁。)
偏向锁如果调用wait等操作,也就是重度竞争就会转换成重量级锁
(重量级锁是依赖对象内部的monitor锁来实现的,而monitor又依赖操作系统的MutexLock(互斥锁)来实现的,所以重量级锁也被成为互斥锁。主要是,当系统检查到锁是重量级锁之后,会把等待想要获得锁的线程进行阻塞,被阻塞的线程不会消耗cup。但是阻塞或者唤醒一个线程时,都需要操作系统来帮忙,这就需要从用户态转换到内核态,而转换状态是需要消耗很多时间的,有可能比用户执行代码的时间还要长。这就是说为什么重量级线程开销很大的。互斥锁(重量级锁)也称为阻塞同步、悲观锁)


四大引用
软引用(SoftReference):内存不足的时候进行释放
(举一个例子:如果把用户需要访问的图片都加载进来内存,那么访问的时候速度就会很快,但是内存的消耗是非常大的;但是所有图片都不加载进来内存,每次都从磁盘去访问获取用户需要的图片,那么访问的速度是非常慢的;这时候就可以使用弱引用构建一个空间来进行使用,在内存不足的时候就回收空间内的内容)
强引用:引用链不断就不会释放
就是正常的
new Object()弱引用(WeakReference):GC回收的时候就会回收
一些对App运行没有影响的对象就可以使用弱引用,弱引用对处理内存泄露很有用,比如持有Activity解决内存泄露
虚引用(PhantomReference):GC回收的时候会得到一个通知
虚引用也叫幽灵引用,虚拟机开发可能会用到,日常开发极少用到
虚引用不会单独去使用,构架PhantomReference虚引用对象的时候需要传入一个对象和一个引用队列(ReferenceQueue对象),构建好对象后使用Queue.poll()对传入虚引用对象的对象访问并不会获取到数据,也就是为null,但是如果在GC到来后休眠线程然后在poll访问一下队列里面的这个对象就会发现可以访问到,说明对象存在了,但是并不能获得对象的引用,只能知道这个对象被GC的时间
单例的实现方式
个人记录
HashMap和SparseArray原理,相对有什么优缺点
HashMap 数组+链表的思想,使用容量为16的数组进行存储,并且每个数组是链表的表头,即使没有内容进行存储,在对象存在时会分配一块固定的内存空间供其使用,但不断往HashMap中put内容的时候如果超出它的阈值,也就是存储空间,那么就需要进行扩容操作。put操作在hashcode()函数后得到一个hash值之后进行取模映射到正确的位置(index),如果当前下标下面后面的链表为空,那么直接构建链表往后面放就可以了,如果不为空就往后放并更改最后的一个的指向下一个值的index信息,空间不够就需要进行扩容操作,Get过程计算hash过程相同,查找具体的值还需要进行遍历去从链表中进行查找
SparseArray的key和value都是数组,key为一个int类型的数组,value为一个Object类型的数组,双数组进行保存,对于put进来的值,对于一个key进行哈希操作得到一个hash值,之后通过二分查找去查找其需要放入的位置,对于get操作就直接根据hash值进行二分查找确定位置返回值即可。特别的,如果有值需要进行删除,先进行查找,找到需要删除的值后不是直接进行删除,而是直接将值赋值为DELETE,一个标识,之后需要存值如果key小于原本的值并且value为DELETE就直接赋值即可,不需要整体移动,耗时短。
它内部对数据还采取了压缩的方式来表示稀疏数组的数据,从而节约内存空间
这两者都是存储<key,value>键值对数组的数据结构,但具体数据结构不同,HashMap为数组+链表的结构,SparseArray为双数组的结构,性能方面:HashMap对于int类型的Key自动装箱为Integer,但是它的key为任何类型都可以,所以虽然性能不够好但是直到现在都没有被淘汰,SparseArray的key限制为int类型。
数据量小于1k。如果key不是int小于1000的话。可以用Arraymap。
虽说SparseArray性能比较好,但是由于其添加、查找、删除数据都需要先进行一次二分查找,所以在数据量大的情况下性能并不明显,将降低至少50%。满足下面两个条件我们可以使用SparseArray代替HashMap:数据量不大,最好在千级以内;key必须为int类型,这中情况下的HashMap可以用SparseArray代替。
ConcurrentHashMap基本原理
ConcurrentHashMap是一个支持高并发更新和查询的哈希表
Glide
Glide缓存机制
引入缓存的目的:可以减少流量的消耗,加快响应速度;Bitmap的加载和销毁比较占内存,可能会导致频繁GC,使用缓存可以更加高效地加载Bitmap
缓存过程:Glide的缓存分为内存缓存和磁盘缓存,内存缓存是由弱引用+LruCache组成的。取的顺序是:弱引用->LruCache->磁盘;存的顺序是磁盘->弱引用->LruCache
内存缓存原理:弱引用是由一个HashMap维护,key是缓存的key(这个key由图片url、width、heigjt等10来个参数组成)value是图片资源对象的弱引用类型
Map<Key, ResourceWeakReference> activeEngineResources = new HashMap<>();,LruCache是由一个LinkedHashMap维护,根据Lru算法来管理图片。大致的原理就是利用LinkedHashMap链表的特性,把最近使用过的文件插入到列表头部,没使用过的放在尾部;然后当图片大小达到预设的一个阈值的时候,按照算法删除列表的尾部的数据。图解LinkedHashMap原理 - 简书 (jianshu.com)
看了图,是头插,往header的before去插入Entry
内存缓存下的存取原理:(取数据)内存缓存中有一个概念为图片引用计数器,具体来说就是在EngineResource中定义了一个acquired变量用来记录图片被引用的次数,调用
acquire()方法会让变量+1,调用release()方法会让变量-1,获取图片资源是先从弱引用获取,拿到的话引用数+1,没有就从LruCache中拿缓存,拿到的话,引用数也+1,同时把图片从LruCache缓存移动到弱应用缓存池中;再没有的话就通过EngineJob开启线程池去加载图片,拿到的话引用数+1,会把图片放到弱引用中。(存数据)存数据是在加载图片之后的事情,通过EngineJob开启线程池去加载图片,拿到数据后就回调到主线程,把图片存到弱引用中,当图片不再使用或者暂停使用,也就EngineResource中的acquire为0的时候就会将弱引用中的图片放到LruCache中进行缓存,同一张图片只会出现在LruCache中的一个磁盘缓存原理(DiskLruCache):Glide的磁盘缓存策略有多种,
DiskCacheStrategy.DATA : 只缓存原始图片;
DiskCacheStrategy.RESOURCE :只缓存转换过后的图片;
DiskCacheStrategy.ALL :既缓存原始图片,也缓存转换过后的图片;对于远程图片,缓存 DATA
和 RESOURCE;对于本地图片,只缓存 RESOURCE;
DiskCacheStrategy.NONE :不缓存任何内容;
DiskCacheStrategy.AUTOMATIC :默认策略,尝试对本地和远程图片使用最佳的策略。当下载网
络图片时,使用 DATA (原因很简单,对本地图片的处理可比网络要容易得多);对于本地图片,使
用 RESOURCE 。同样的如果在磁盘缓存中没有获取到就通过EngineJob开启线程池去加载图片,这里有两个关键类,DecodeJob和EngineJob,EngineJob内部维护了线程池,DecodeJob是线程池中的一个任务
磁盘缓存是通过 DiskLruCache 来管理的,根据缓存策略,会有2种类型的图片, DATA (原始图片)和
RESOURCE (转换后的图片)。磁盘缓存依次通过 ResourcesCacheGenerator 、 SourceGenerator 、
DataCacheGenerator 来获取缓存数据。 ResourcesCacheGenerator 获取的是转换过的缓存数据;
SourceGenerator 获取的是未经转换的原始的缓存数据; DataCacheGenerator 是通过网络获取图片
数据再按照按照缓存策略的不同去缓存不同的图片到磁盘上。为什么引入弱引用?(提高效率)弱引用使用的是HashMap,而LruCache采用的是LinkedHashMap,从访问效率而言,肯定是HashMap更高;(分压策略)减少LruCache中的trimToSize的概率,同一张图片不会同时出现在弱引用和LruCache中,正在引用的放到弱引用中,减少了LruCache中存放的数量
总结
Glide缓存分为 弱引用+ LruCache+ DiskLruCache ,其中读取数据的顺序是:弱引用 > LruCache >
DiskLruCache>网络;写入缓存的顺序是:网络 –> DiskLruCache–> LruCache–>弱引用
内存缓存分为弱引用的和 LruCache ,其中正在使用的图片使用弱引用缓存,暂时不使用的图片用
LruCache缓存,这一点是通过 图片引用计数器(acquired变量)来实现的,详情可以看内存缓存的小
结。
磁盘缓存就是通过DiskLruCache实现的,根据缓存策略的不同会获取到不同类型的缓存图片。它的逻辑
是:先从转换后的缓存中取;没有的话再从原始的(没有转换过的)缓存中拿数据;再没有的话就从网
络加载图片数据,获取到数据之后,再依次缓存到磁盘和弱引用。Glide生命周期
在Glide加载图片时内部会创建一个无UI的Fragment,也就是RequestManagerFragment
(获取过程)
它在RequestManagerRetriever类的getRequestManagerFragment()被调用,这里通过findFragmentByTag去获取Fragment,如果为null就从pendingRequestManagerFragments这个Map集合去获取,如果还为null就直接new一个Fragment并保存到pendingRequestManagerFragments以及添加到Activity中(因为无UI,直接add进去也没事,事物动态添加),这样这个Fragment就和当前Activity生命周期关联起来了
(具体内部对于生命周期处理)
里面主要有ActivityFragmentLifecycle类,这个类调用了LifecycleListener的相关方法,LifecycleListener是一个接口,这个接口的作用是监听生命周期的作用,具体实现在RequestManager类。
项目中使用Glide框架出现内存溢出,应该是什么原因?
Glide在with中传入的是具有生命周期的作用域(非Application作用域),尽量避免使用Application作用域,因为Application作用域不会对页面绑定生命周期机制,就会回收不及时释放操作等
Glide作用域,一种作用域是Application,它的生命周期是全局的,不绑定空白Fragment就绑定Activity;第二种作用域是非Application,它的生命周期。。。(就是前面的部分)(这里就是对应子线程和主线程调用的区别了)